上一篇
hive数据仓库计算引擎答案
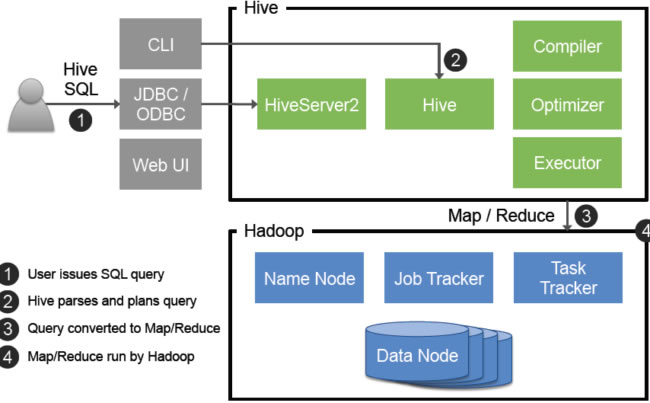
Hive是基于Hadoop的数据仓库工具,支持类SQL查询,通过HDFS存储数据,结合MapReduce实现批量处理,适用于大
Hive是基于Hadoop的数据仓库解决方案,其核心价值在于通过类SQL语言(HiveQL)实现对大规模数据的批处理分析,作为Apache开源项目,Hive将SQL查询转换为MapReduce任务,同时支持Tez、Spark等多种计算引擎,在互联网企业级数仓场景中应用广泛,以下是其技术架构与核心特性的深度解析:
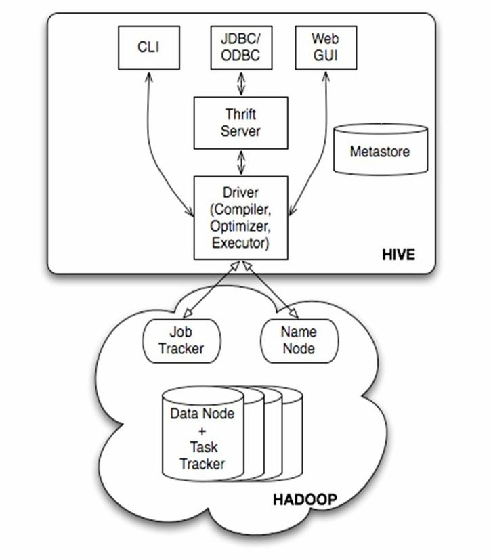
Hive技术架构解析
| 组件模块 | 功能描述 |
|---|---|
| Metastore | 元数据管理系统,存储表结构、分区信息、权限数据,默认使用内嵌Derby数据库,生产环境建议对接MySQL或PostgreSQL |
| Driver | 查询入口,负责解析HiveQL、生成执行计划、调用计算引擎 |
| Compiler | 语法解析与优化模块,包含解析器(Parser)、语义分析器(Analyzer)、优化器(Optimizer) |
| Execution Engine | 可插拔计算引擎接口,支持MR/Tez/Spark等多种执行模式 |
| HDFS Storage | 数据存储层,采用Hadoop分布式文件系统,支持ORC/Parquet/Avro等列式存储格式 |
核心执行流程
- SQL解析:通过ANTLR语法解析器将HiveQL转换为抽象语法树(AST)
- 语义分析:检查表/列存在性、数据类型兼容性,生成逻辑执行计划
- 优化处理:应用列式裁剪(Column Pruning)、谓词下推(Predicate Pushdown)等优化策略
- 任务拆分:将逻辑计划拆分为多个MapReduce/Tez DAG/Spark Job
- 物理执行:通过计算引擎执行任务,结果写入HDFS临时目录后合并返回
多计算引擎对比
| 特性维度 | MapReduce | Tez | Spark |
|---|---|---|---|
| 执行模型 | 两阶段MR任务 | DAG调度引擎 | 内存计算+RDD模型 |
| 性能表现 | 高延迟(分钟级) | 中等延迟(秒级) | 低延迟(亚秒级) |
| 资源消耗 | 高磁盘IO | 中间结果管道化 | 内存优先 |
| 适用场景 | 超大数据集处理 | 常规批处理 | 迭代式算法 |
| 典型配置 | set hive.execution.engine=mr | set hive.execution.engine=tez | set spark.master=yarn |
关键性能优化策略
存储层优化
| 优化项 | 实施方案 |
|---|---|
| 列式存储 | 使用ORC格式(支持Snappy压缩),相比Text/SequenceFile提升30%+存储效率 |
| 分区策略 | 按业务时间/地域等维度分区,避免全表扫描 |
| 文件大小控制 | 单个文件建议128MB-1GB,过小文件增加Map任务开销 |
| BloomFilter索引 | 开启ORC文件的BloomFilter(hive.orc.filter.enable=true)加速数据过滤 |
计算参数调优
| 参数配置 | 作用说明 |
|---|---|
mapreduce.map.memory | 单个Map任务内存上限(建议4-8GB) |
hive.exec.parallel | 并发执行同一查询的多个阶段(默认true) |
hive.exec.dynamic.partition | 允许动态分区插入(需配合set hive.exec.dynamic.partition.mode=nonstrict) |
hive.vectorized.execution | 启用向量化执行(C++层面向量化运算) |
数据倾斜解决方案
- 空值过滤:
SET hive.groupby.skewindata=true自动过滤null键 - 倾斜key分散:
MAPJOIN_KEY_DEDUP参数开启自动去重 - 手动拆分:使用
DISTRIBUTE BY将倾斜key随机分配到不同reducer - 本地合并:启用
hive.groupby.mapaggregate=true进行Map端预聚合
典型应用场景与限制
优势领域
- 离线数据分析:日均PB级日志处理、用户行为分析
- ETL管道:数据清洗、特征工程、宽表构建
- 即席查询:业务部门自助式OLAP分析
- 报表生成:定时调度生成运营报表
局限性
- 实时性不足:分钟级查询延迟无法满足实时需求
- 小数据集低效:处理GB级数据时资源利用率低
- 更新延迟:INSERT OVERWRITE操作需要全量重写
- 事务支持弱:仅支持ACID事务但性能损耗显著
生态工具链整合
Hive常与其他组件组合形成完整数仓解决方案:
- 数据采集:Flume/Kafka + Flume Source Connector
- 调度系统:Apache Oozie/Airflow管理定时作业
- BI对接:Tableau/PowerBI通过ODBC连接HiveServer2
- 安全体系:Ranger/Sentry实现细粒度权限控制
- 性能监控:集成Ganglia/Prometheus监控系统指标
FAQs
Q1:Hive与关系型数据库的核心区别是什么?
A1:Hive专为离线分析设计,支持PB级数据存储,采用分布式计算架构;而关系数据库侧重事务处理,强调ACID特性,Hive不支持行级更新,适合读多写少的场景。
Q2:如何诊断Hive作业的性能瓶颈?
A2:1) 使用EXPLAIN查看执行计划,检查是否全表扫描;2) 监控YARN资源使用情况,观察Map/Reduce阶段耗时;3) 检查数据倾斜(某reducer长时间99%进度);4) 分析HDFS I/O