上一篇
hive数据仓库及数据查询
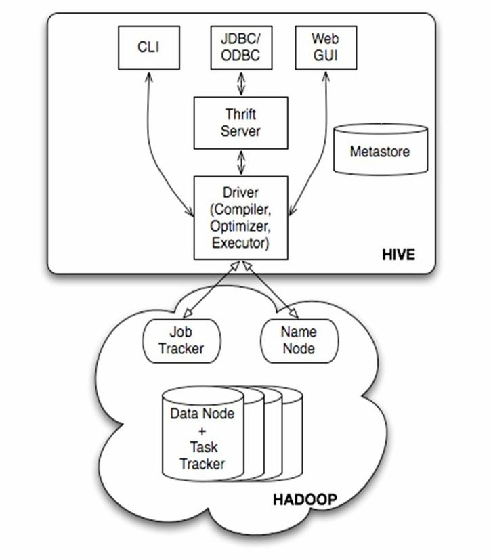
Hive是基于Hadoop的分布式数据仓库,支持类SQL的HiveQL进行批量数据查询,通过将查询转化为MapReduce任务实现对HDFS中
Hive是基于Hadoop的数据仓库工具,专为大规模数据存储和复杂查询设计,其核心优势在于将SQL语法(Hive QL)与分布式计算框架(MapReduce/Tez/Spark)结合,实现PB级数据的高效分析,以下是Hive数据仓库的核心要素及查询实践的详细解析:
Hive架构体系
| 组件 | 功能描述 |
|---|---|
| Metastore | 元数据管理系统,存储表结构、分区信息 |
| Driver | 编译执行计划,生成可执行的MapReduce任务 |
| Execution Engine | 底层计算引擎(MR/Tez/Spark) |
| User Interface | 提供CLI/JDBC/ODBC等多种访问接口 |
典型工作流程:
- 客户端提交HiveQL语句
- Driver解析语法并生成执行计划
- Metastore获取元数据
- Execution Engine执行分布式计算
- 结果返回给客户端
存储管理机制
存储格式对比
| 格式 | 特点 |
|---|---|
| Text | 纯文本存储,兼容HDFS,但无压缩和类型支持 |
| Parquet | 列式存储,支持嵌套结构,高效压缩(Snappy/GZIP),适合OLAP场景 |
| ORC | 优化的列式存储,支持复杂类型,提供轻量级索引,压缩比高于Parquet |
| Avro | 基于Schema的二进制格式,支持动态类型扩展,适合流批一体场景 |
最佳实践:

- 日志类数据优先选择ORC/Parquet格式
- 需要快速读取的场景启用BloomFilter
- 压缩算法推荐Snappy(平衡压缩率与性能)
分区与桶策略
- 分区(Partition):按业务维度(如日期、地区)划分目录结构,减少全表扫描
CREATE TABLE sales(id BIGINT, amount DECIMAL(10,2)) PARTITIONED BY (dt STRING, region STRING) STORED AS ORC;
- 桶(Bucket):通过哈希函数将数据均匀分布到多个文件,提升JOIN效率
CLUSTERED BY (user_id) INTO 16 BUCKETS -创建16个哈希桶
数据模型设计
表类型选择
| 类型 | 适用场景 |
|---|---|
| 内部表 | 数据生命周期与Hive完全一致,删除表时数据同步清除 |
| 外部表 | 数据独立于Hive存在,适合与其他系统共享数据源 |
| 临时表 | 会话级生命周期,用于中间计算结果缓存 |
分区剪裁原理
当执行WHERE dt='2023-10-01'时,Hive仅扫描dt=2023-10-01目录下的文件,避免全表扫描,需注意:
- 分区字段必须出现在WHERE条件中
- 动态分区需开启
set hive.exec.dynamic.partition=true
HiveQL查询优化
常见优化策略
| 策略 | 实现方式 |
|---|---|
| 谓词下推 | 开启hive.optimize.ppd=true,将过滤条件推送到Scan阶段 |
| 列式存储优化 | 使用ORC/Parquet格式,配合hive.io.file.buffer.size参数调优 |
| JOB合并 | 设置hive.merge.mapfiles=true,自动合并小文件 |
| 倾斜数据处理 | 使用MAPJOIN提示或hive.groupby.skewindata=true处理数据倾斜 |
复杂查询案例
需求:统计各省份每日订单金额,并关联用户画像表
SELECT
o.province,
o.dt,
SUM(o.amount) AS total_sales,
u.user_level,
COUNT(DISTINCT u.id) AS active_users
FROM orders o
JOIN user_profile u ON o.user_id = u.id
WHERE o.dt BETWEEN '2023-10-01' AND '2023-10-07'
GROUP BY o.province, o.dt, u.user_level
DISTRIBUTE BY o.province, o.dt -确保相同分区数据进入同一Reducer优化点:
- 使用
MAPJOIN提示将用户画像表加载到内存 - 对
dt字段建立分区避免全表扫描 DISTRIBUTE BY保证相同分组键数据集中处理
性能监控与调优
| 指标 | 监控方法 |
|---|---|
| 执行耗时 | YARN ResourceManager查看Job历史 |
| Map/Reduce阶段倾斜 | 检查Task时长分布,超过平均时长3倍视为异常 |
| IO吞吐量 | HDFS UI查看Block读写速率 |
| 内存消耗 | Yarn日志中查看Container内存使用峰值 |
典型问题诊断:
- 小文件过多:启用
CombineTextInputFormat合并输出文件 - 数据倾斜:使用
hive.groupby.skewindata=true自动负载均衡 - 内存溢出:调整
mapreduce.map.memory.mb和yarn.nodemanager.vmem-pmem-ratio
FAQs
Q1:Hive与关系型数据库的核心区别是什么?
A1:Hive专为离线分析设计,采用分布式存储(HDFS)、列式存储优化查询性能,而关系型数据库侧重事务处理(ACID特性),适用于实时业务系统,Hive不支持行级更新和事务,但可通过分区实现近似更新。
Q2:如何优化包含JOIN操作的HiveQL?
A2:优先使用广播JOIN(MAPJOIN)处理小表,大表关联时确保JOIN键已建立分区,对于超大表关联,可采用分步计算:先将一方结果预聚合后再JOIN,或使用INSERT OVERWRITE替代