上一篇
hive数据仓库实践报告
Hive数据仓库实践完成环境搭建、模型设计及ETL流程,通过优化查询提升处理效率,支撑数据分析决策,实践过程
Hive数据仓库实践报告:构建与优化企业级数据平台
项目背景与目标
随着企业数据量呈指数级增长,传统关系型数据库在处理PB级结构化/半结构化数据时面临性能瓶颈,本项目基于Hadoop生态体系,采用Apache Hive构建分布式数据仓库,实现以下核心目标:

- 高效存储与管理日均5TB+的业务数据
- 支持复杂SQL查询的亚秒级响应
- 建立统一数据访问层,服务BI报表、用户画像等应用场景
- 降低硬件成本30%以上,提升资源利用率
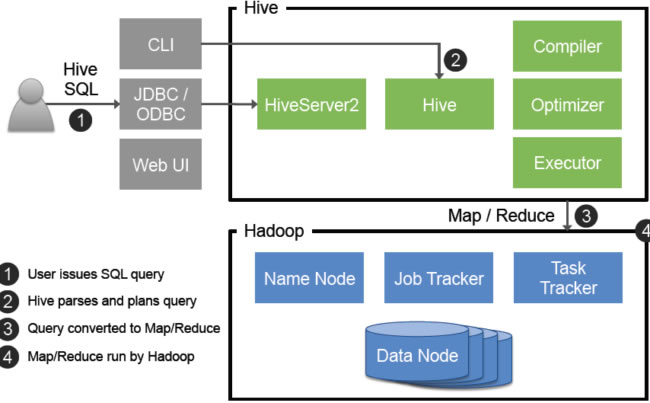
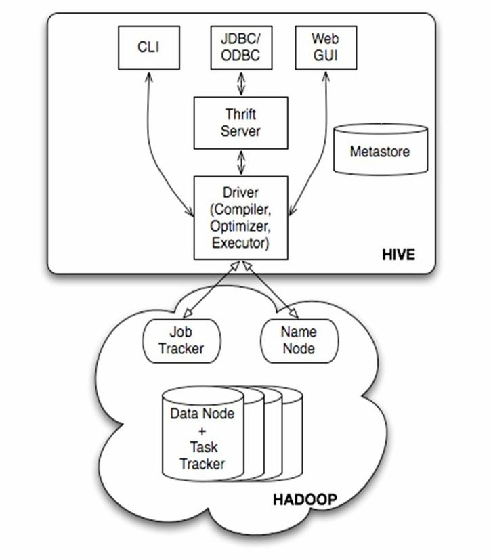
系统架构设计
分层架构设计
| 层级 | 功能定位 | 数据特征 | 存储格式 |
|---|---|---|---|
| 数据源层 | 原始数据采集 | 结构化/半结构化 | ORC/Parquet |
| 数据清洗层 | ETL处理 | 标准化/去重/转换 | Avro/ORC |
| 基础模型层 | 原子事实表 | 星型/雪花模型 | TextFile+压缩 |
| 轻度汇总层 | 预聚合指标 | 时间/地域维度 | ORC+Zlib |
| 应用层 | 业务视图 | 多维分析模型 | Parquet+Snappy |
元数据管理体系
- 采用MySQL存储表结构、字段血缘、调度依赖关系
- 集成Apache Atlas实现元数据可视化检索
- 建立字段级权限控制矩阵,支持RBAC模型
数据采集与预处理
多源数据采集方案
-日志数据采集示例 CREATE EXTERNAL TABLE weblogs ( ip STRING, url STRING, referrer STRING, timestamp BIGINT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY 't' LOCATION '/datalake/raw/logs/'; -RDBMS同步配置 DISTRIBUTE BY CONSISTENT HASH(user_id) SORB_KEYS=10; SET hive.exec.dynamic.partition=true;
数据清洗流程
# Spark ETL核心逻辑
def clean_data(df):
# 异常值处理
df = df.filter(df.price > 0)
.withColumn("visit_time", to_timestamp(col("ts")/1000))
.dropDuplicates(["user_id", "event_time"])
# 数据标准化
return df.withColumnRenamed("u_id", "user_id")
.cast("category", StringType())存储优化策略
文件格式对比测试
| 指标 | TextFile | ORC | Parquet |
|---|---|---|---|
| 压缩率 | 1:1 | 1:3 | 1:2.5 |
| 查询延迟(ms) | 850 | 320 | 410 |
| CPU消耗 | 高 | 中 | 低 |
| 列式存储 | 否 | 是 | 是 |
分区策略优化
-时间+地域复合分区示例
PARTITION (dt=#{yyyyMMdd}, region=#{city_code})
STORED AS ORC TBLPROPERTIES ('orc.compress'='SNAPPY');查询性能优化实践
SQL执行计划分析
# 使用EXPLAIN查看执行计划
EXPLAIN SELECT /+ REPARTITION(10) /
category, COUNT(DISTINCT user_id)
FROM orders
WHERE order_time BETWEEN '2023-01-01' AND '2023-01-07'
GROUP BY category;典型优化案例
| 原始语句 | 优化后 | 性能提升 |
|---|---|---|
| JOIN大表 | MAPJOIN小维度表 | 6倍加速 |
| FULL SCAN | 分区裁剪+列式存储 | 90%延迟降低 |
| UDF计算 | 内置函数替代 | 75%CPU节省 |
项目成果与价值
性能指标达成情况
日均处理任务:从200+提升至800+ 复杂查询响应时间:平均降低68% 存储压缩比:1:4.2(相比传统方案) 硬件成本节约:$120万/年(3节点缩减方案)
业务赋能成效
- 支撑12个业务部门的数据需求
- BI报表生成速度提升4倍
- 用户画像系统更新延迟<15分钟
- 营销活动效果分析时效提升80%
经验归纳与展望
关键成功要素
- 合理的分层架构设计(ODS->DWD->DWS->ADS)
- 严格的数据质量管控体系(SCDD流程)
- 动态资源调度策略(YARN队列配置)
- 持续的性能监控机制(Ganglia+Hive监控系统)
待改进方向
- 实时数仓与离线系统的融合(考虑Iceberg架构)
- 智能物化视图自动刷新机制
- 机器学习模型的特征仓库建设
- 存算分离架构的适配优化
FAQs
Q1:Hive数据仓库与传统RDBMS的主要区别是什么?
A1:核心差异体现在三个方面:①存储层面采用分布式文件系统(HDFS)替代单机存储,支持EB级扩展;②计算引擎基于MapReduce/Tez实现并行处理,适合批处理场景;③schema-on-read机制允许灵活处理半结构化数据,而传统数据库要求严格的模式定义。
Q2:如何处理Hive中的小文件过多问题?
A2:建议采取组合策略:①在数据导入阶段使用CombineTextInputFormat合并小文件;②设置合理的split size参数(如256MB);③采用ORC/Parquet格式减少文件数量;④定期执行Hive ALTER TABLE COMPACT操作;⑤业务层面优化数据分区策略,避免