上一篇
hive数据仓库是什么意思
Hive是基于Hadoop的数据仓库工具,通过HiveQL实现大规模数据存储、管理和分析,支持离线处理与商业智能,简化复杂
Hive数据仓库是一种基于Hadoop生态系统构建的大数据存储与处理工具,专为海量结构化数据处理设计,它通过类SQL语言(HiveQL)实现数据查询,底层依赖HDFS存储数据,并利用MapReduce或Tez等计算框架执行任务,以下从核心概念、技术架构、应用场景等维度展开详细说明:

Hive数据仓库的核心特性
| 特性 | 说明 |
|---|---|
| 扩展性 | 支持PB级数据存储,横向扩展能力依赖HDFS集群规模 |
| 离线批处理 | 适合高延迟容忍场景,复杂查询需分钟至小时级响应时间 |
| Schema-On-Read | 数据写入时无严格模式限制,读取时按指定模式解析 |
| 成本优化 | 使用廉价PC服务器集群,存储计算分离降低硬件门槛 |
| 兼容性 | 与SQL语法高度兼容,支持JDBC/ODBC连接,降低传统数据人员学习成本 |
Hive技术架构解析
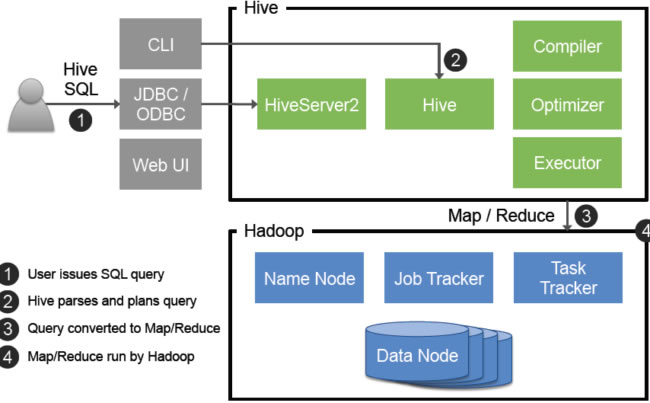
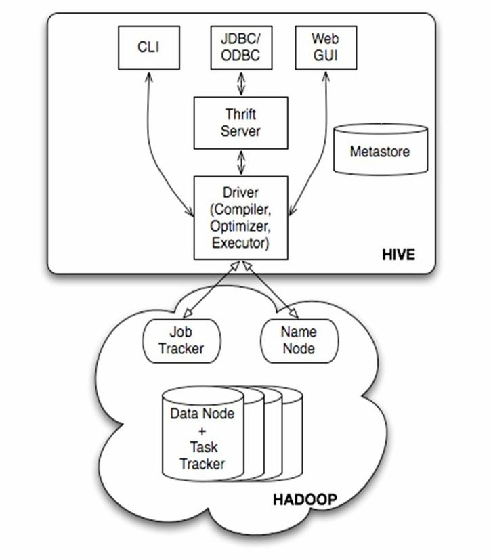
核心组件
| 组件 | 功能描述 |
|---|---|
| Metastore | 元数据管理系统,存储表结构、分区信息、权限等,默认使用MySQL/PostgreSQL |
| Driver | 编译HiveQL为执行计划,提交任务到YARN或直接启动MapReduce |
| Execution Engine | 实际执行引擎,可配置为MR、Tez或Spark |
| CLI/Beeline | 命令行/Web交互界面,提供查询入口 |
数据存储机制
- 文件格式:支持Text、SequenceFile、ORC、Parquet等,ORC/Parquet提供列式存储优化
- 分区策略:按时间/地域等维度分区,减少全表扫描
- 文件压缩:采用Snappy/Zlib压缩减小存储空间,提升IO效率
- 索引机制:支持Compacted和Bitmap索引加速查询
执行流程示例
graph TD
A[Client提交HiveQL] --> B[Parser解析语法]
B --> C[Semantic Analyzer语义分析]
C --> D[Query Planner生成执行计划]
D --> E[Optimizer优化计划]
E --> F[Execution Engine执行]
F --> G[HDFS读取数据]
G --> H[MapReduce/Tez计算]
H --> I[结果返回客户端]Hive与传统数据仓库对比
| 维度 | Hive | 传统数仓(如Oracle/Teradata) |
|---|---|---|
| 硬件成本 | 廉价PC集群 | 专用高端服务器 |
| 扩展方式 | 水平扩展 | 垂直扩展 |
| 数据处理延迟 | 分钟级(批处理) | 亚秒级(MPP架构) |
| 灵活性 | Schema-On-Read | 严格的Schema-On-Write |
| 生态整合 | 天然集成Hadoop生态 | 依赖ETL工具接入大数据源 |
典型应用场景
- 日志分析:处理网站访问日志、应用日志,进行UV/PV统计、用户行为分析
- 数据仓库构建:整合多源数据(如MySQL、MongoDB、Kafka),构建企业级数据湖
- 报表生成:支撑BI工具(Tableau/PowerBI)的底层数据查询
- 历史数据分析:处理TB-PB级归档数据,如金融交易记录、传感器监测数据
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 数据存储优化 | 使用ORC格式+Snappy压缩,创建合理分区(如按天/小时) |
| 查询优化 | 开启CBO(成本优化器),避免全表扫描,使用LIMIT限制结果集 |
| 资源配置优化 | 调整MapReduce并行度,设置合理的Memory/CPU配额,使用Tez替代MR提升速度 |
| 索引优化 | 对高频查询字段建立Compacted索引 |
技术局限与应对方案
| 痛点 | 解决方案 |
|---|---|
| 实时性差 | 结合Kafka+Spark Streaming处理实时需求,Hive处理历史数据 |
| 小文件问题 | 设置合理BlockSize,使用CombineHinter合并小文件 |
| 更新延迟 | 采用Delta Lake/Apache Hudi实现近实时更新 |
| 权限管理薄弱 | 集成Ranger/Sentry实现细粒度权限控制 |
FAQs
Q1:Hive是否支持实时数据处理?
A1:Hive本质是批处理系统,单次查询延迟通常在分钟级,对于实时需求,建议结合Kafka(消息队列)+ Spark Streaming(流计算)处理即时数据,Hive则用于存储和分析历史全量数据。
Q2:如何提升Hive复杂查询的执行效率?
A2:可采取以下措施:
- 将频繁作为过滤条件的字段设置为分区键
- 对JOIN操作的小表启用内存缓存(LATERAL VIEW)
- 使用Vectorization优化(SET hive.vectorized.execution=true)
- 将宽表拆分为星型/雪花模型,减少单次扫描数据量
- 优先选择Tez作为执行引擎替代