上一篇
hive数据仓库开发
Hive是基于 Hadoop的数据仓库工具,通过类SQL的HiveQL将查询转为MapReduce任务,支持多格式数据存储与分区/分桶优化,适用于大规模数据离线分析,并
Hive数据仓库开发核心要点与实践指南
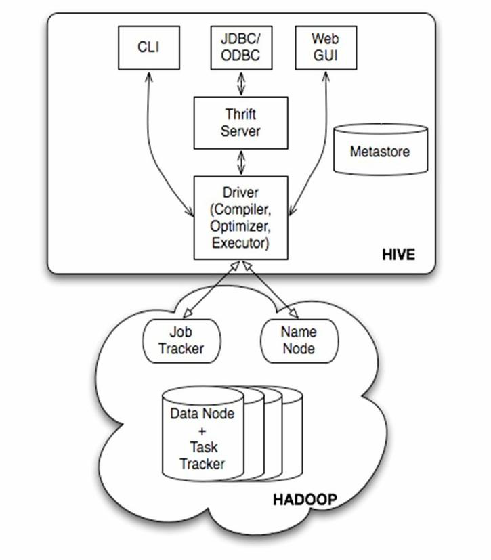
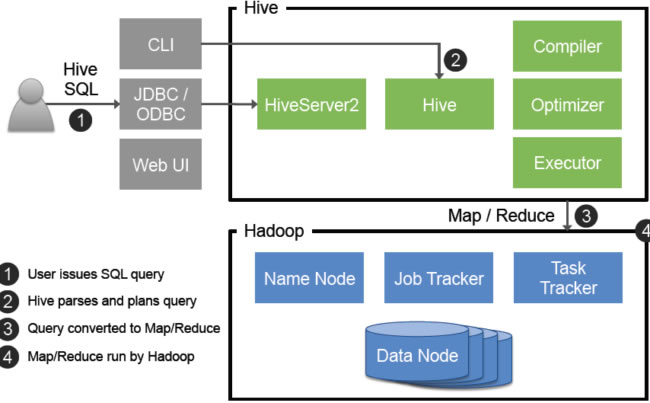
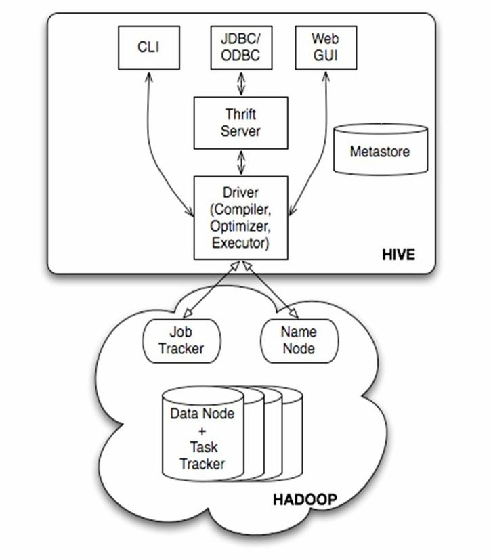
Hive基础架构与核心组件
Hive是基于Hadoop的分布式数据仓库工具,采用类SQL语法(HiveQL)实现批量数据处理,其核心架构包含以下组件:
| 组件 | 功能描述 | 技术实现 |
|---|---|---|
| Metastore | 元数据管理(表结构、分区信息等) | 关系型数据库(MySQL/PostgreSQL) |
| Driver | 编译执行计划 | Hive CLI/Beeline/JDBC接口 |
| Compiler | 语法解析与优化查询计划 | Antlr语法解析器+CBO优化器 |
| Executor | 任务分发与执行 | Hadoop MapReduce/Tez/Spark |
| Metadata Cache | 元数据缓存加速访问 | 本地内存缓存机制 |
典型工作流程:
- 客户端提交HiveQL语句
- Compiler解析生成执行计划(包含MapReduce/Tez任务)
- Executor将任务拆分为Stage并行执行
- 结果通过HDFS存储并返回给用户
数据仓库开发关键步骤
需求分析与建模
- 范式选择:星型模型(事实表+维度表) vs 雪花模型
- 分层设计:建议采用ODS→DWD→DWS→ADS四层架构
- 示例模型:电商数据仓库中的订单事实表(含订单ID、金额、时间戳)与用户/商品/商户维度表
表结构设计规范
| 设计原则 | 具体措施 |
|—————–|———————————————|
| 分区粒度控制 | 按时间(日/小时)、地域等业务维度分区 |
| 文件格式选择 | ORC(列式存储+压缩)优先于TEXT/PARQUET |
| 字段类型优化 | 使用INT而非BIGINT,DECIMAL替代DOUBLE |
| 空值处理 | 启用SKIP_NULL_DATA参数提升查询性能 |
数据加载策略
- 动态分区插入:
SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; INSERT INTO TABLE sales_partitioned PARTITION(dt) SELECT , FROM_UNIXTIME(ts/1000,'yyyy-MM-dd') AS dt FROM raw_sales;
- 增量导入:利用
INSERT OVERWRITE配合WHERE $sk_max > last_load_sk实现增量更新
高级功能开发实践
自定义函数(UDF)开发

- Java UDF示例:
public class IPAddressParser extends UDF { public String evaluate(String ip) { return InetAddress.getByName(ip).getHostName(); } } // 注册方式:ADD JAR /path/to.jar; CREATE TEMPORARY FUNCTION parseIP AS 'com.example.IPAddressParser'; - 适用场景:复杂数据清洗(如IP转地域、电话号码分段解析)
窗口函数应用
SELECT
user_id,
SUM(order_amount) OVER(PARTITION BY user_id ORDER BY order_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total
FROM orders_fact- 典型用途:用户行为路径分析、滚动计算指标
事务表与ACID支持
- 开启事务:
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; - 典型操作:
INSERT INTO TABLE customer_dim VALUES(...); -自动获取写锁 UPDATE customer_dim SET phone='xxx' WHERE id=123; -基于行级锁更新 DELETE FROM customer_dim WHERE status=0; -删除标记处理
性能优化策略矩阵
| 优化方向 | 具体措施 | 效果预期 |
|---|---|---|
| 数据存储层 | 启用BZ2/Snappy压缩,采用ORC文件格式 | 存储节省30%-50%,IO降低 |
| 查询执行层 | 设置hive.vectorized.execution=true | Map端处理速度提升2-3倍 |
| 资源配置 | 调整mapreduce.map.memory.mb至8G+ | 大作业执行时间减少40% |
| SQL优化 | 替换COUNT(1)为COUNT(),避免全表扫描 | 小表查询提速50%以上 |
典型案例:某金融风控查询优化
原始SQL:SELECT FROM transactions WHERE user_id=123 AND transaction_time > '2023-01-01'
优化方案:
- 添加组合索引(user_id+transaction_time)
- 改写为分区剪裁查询:
WHERE user_id=123 AND transaction_date >= '2023-01-01' - 结果:查询耗时从12分钟降至1.2秒
运维监控体系搭建
健康检查指标
| 指标类别 | 关键指标 | 阈值建议 |
|—————–|———————————————|————————-|
| 元数据层面 | Metastore连接延迟、Catalog同步状态 | <500ms/query, 实时同步 |
| 作业运行 | Map/Reduce任务失败率、Stage重试次数 | 失败率<1%, 重试<3次/天 |
| 存储系统 | HDFS块丢失率、NameNode负载 | 块丢失率<0.1% |
日志分析方案
- 错误日志采集:配置YARN/MapReduce的stderr重定向至ELK系统
- 慢查询捕获:启用
hive.log.queries.plan=true记录执行计划 - 异常检测:通过Prometheus+Alertmanager实现作业超时告警
安全与权限管理
授权模型配置
- 基于角色的访问控制(RBAC):
CREATE ROLE data_scientist; GRANT SELECT ON table sales_fact TO ROLE data_scientist;
- 动态掩码:对敏感字段(如手机号)实施
MASK('--')处理
Sentry集成方案
- 安装步骤:
- 部署Sentry服务并配置
sentry-site.xml - 同步Hive元数据:
sentry-init-hms.sh - 创建策略:
CREATE RESOCRCE TAG tag1 FOR RESOURCE 'hdfs:///user/hive/warehouse'
典型应用场景实战
场景1:用户画像计算
- 数据流:原始行为日志→DWD层聚合→DWS层标签计算→ADS层可视化看板
- 关键技术:
- 使用
LATERAL VIEW展开JSON格式的用户属性 - 通过
CUBE运算生成多维交叉报表
- 使用
场景2:实时数仓构建
- 架构方案:Kafka(源)→Flume(采集)→Hive(存储) + Spark Streaming(实时处理)
- 注意事项:
- 设置
hive.exec.parallel=true启用并行执行 - 采用
MERGE语句实现实时数据upsert
- 设置
FAQs
Q1:Hive与传统关系型数据库的核心区别是什么?
A1:主要差异体现在三点:
- 存储引擎:Hive基于HDFS分布式存储,传统数据库使用本地磁盘
- 处理模式:Hive适合批量处理(10秒~分钟级延迟),传统数据库支持毫秒级OLTP
- 扩展方式:Hive通过增加DN节点横向扩展,传统数据库依赖纵向扩容
Q2:如何解决Hive小文件过多导致的性能问题?
A2:推荐四步综合治理:
- 合并预处理:使用
Hadoop combiner或Hive CONCATENATE命令合并小文件 - 调整分区策略:将过细粒度分区(如小时分区)调整为日分区+二级目录结构
- 开启自动合并:配置
hive.merge.mapfiles=true和hive.merge.mapredfiles=true - 采用压缩编码:设置`orc.compress=