上一篇
hive数据仓库定义作用
Hive是基于Hadoop的数据仓库工具,支持类SQL查询,用于存储、分析大规模结构化/半结构化数据,适合离线处理,广泛应用于数据挖掘与商业智能
Hive数据仓库定义与作用详解
Hive是由Apache基金会开发的一款基于Hadoop生态系统的数据仓库工具,其核心目标是为大规模数据存储和分析提供高效的解决方案,Hive通过类SQL语言(HiveQL)实现对数据的查询和管理,底层依赖Hadoop的分布式文件系统(HDFS)存储数据,并通过MapReduce或Tez等计算框架执行任务,以下从定义、核心功能、技术架构、应用场景及优缺点等方面展开详细分析。
Hive的核心定义
| 特性 | 描述 |
|---|---|
| 数据存储层 | 基于HDFS构建,支持PB级数据存储,天然具备高容错性和扩展性。 |
| 查询引擎 | 通过HiveQL(类似SQL)实现数据查询,编译为MapReduce任务提交到Hadoop集群。 |
| 数据模型 | 支持传统数据库中的表、分区、桶等概念,但采用“无模式”设计(Schema on Read)。 |
| 生态兼容性 | 与Hadoop生态深度集成,可结合Spark、Pig、Zeppelin等工具完成数据分析流程。 |
Hive的核心作用
统一数据存储与管理
- 结构化数据处理:将分散的日志、业务数据按主题分类存储,通过外部表(External Table)支持多数据源关联分析。
- 数据治理:通过分区(Partition)和桶(Bucket)优化数据组织,提升查询效率,按时间分区存储日志数据,按用户ID哈希分桶实现均匀分布。
高效批量分析
- 复杂查询支持:支持JOIN、GROUP BY、窗口函数等操作,适用于报表生成、用户行为分析等场景。
- 离线计算优化:通过MapReduce或Tez引擎实现资源调度,适合处理小时级、天级延迟的批量任务。
降低开发门槛

- SQL化接口:业务人员无需掌握Java或Scala,通过HiveQL即可完成数据分析,降低学习成本。
- UDF扩展:支持自定义函数(如字符串处理、机器学习模型调用),灵活应对复杂需求。
数据湖与数仓的桥梁
- 多格式兼容:支持JSON、CSV、ORC、Parquet等文件格式,适配不同数据源。
- 元数据管理:通过Metastore(元数据服务)统一管理表结构、分区信息,避免“数据孤岛”。
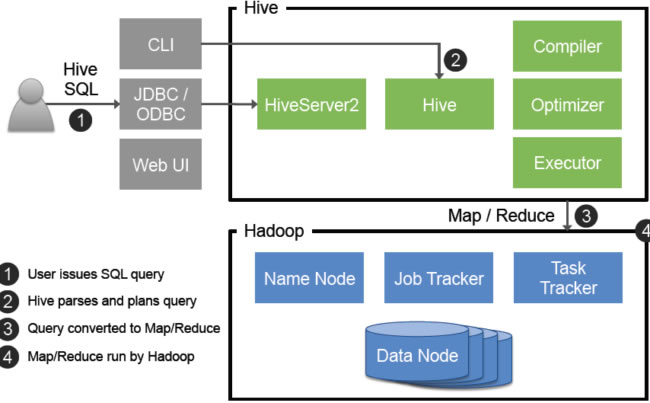
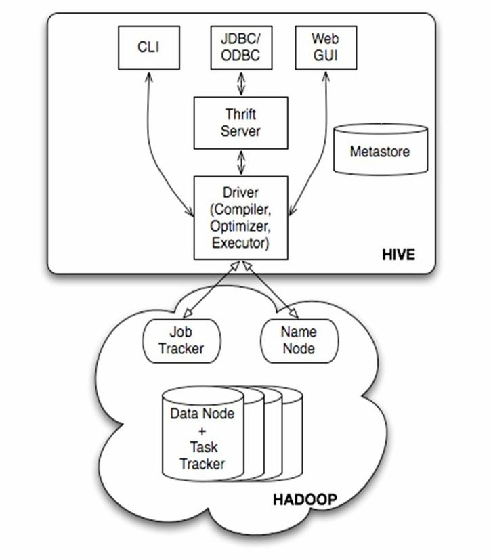
技术架构解析
Hive的架构分为以下核心组件:
| 组件 | 功能 |
|————————-|————————————————————————–|
| Metastore | 存储元数据(表结构、分区信息、权限等),通常由关系数据库(如MySQL)实现。 |
| Driver | 解析HiveQL语句,生成执行计划并提交到Hadoop集群。 |
| Execution Engine | 执行MapReduce或Tez任务,完成数据扫描、过滤、聚合等操作。 |
| User Interfaces | 提供CLI、JDBC、Web UI等多种访问方式,支持BI工具(如Tableau)连接。 |
数据流程示例:
用户提交HiveQL查询 → 2. Driver解析为执行计划 → 3. Execution Engine拆分任务为MapReduce Job → 4. HDFS读取数据 → 5. 结果写入HDFS或返回客户端。
核心功能与典型场景
| 功能/场景 | 实现方式与价值 |
|---|---|
| 分区表(Partitioning) | 按时间、地域等维度划分数据,减少全表扫描,日志分析按dt分区,查询特定日期数据时仅需扫描对应分区。 |
| 动态分区插入 | 支持批量加载数据时自动创建分区,适用于日志流式写入场景。 |
| ORC/Parquet列式存储 | 压缩比高(比文本格式节省70%空间)、支持谓词下推(Predicate Pushdown),加速查询。 |
| ETL管道 | 结合Apache Sqoop(导入MySQL数据)、Oozie(调度任务)构建完整数据处理链路。 |
| 机器学习支持 | 通过Hive调用Python UDF或Spark MLlib模型,实现特征工程与预测结果存储。 |
Hive vs 传统数据库 vs 其他引擎
| 对比维度 | Hive | 传统数据库(如MySQL) | Impala/Spark SQL |
|---|---|---|---|
| 数据规模 | PB级(依赖HDFS) | GB~TB级(受限于单机存储) | PB级(内存计算优化) |
| 延迟 | 高(分钟级) | 低(毫秒级) | 低(秒级) |
| 灵活性 | 无模式设计,支持半结构化数据 | 强模式约束 | 中等(需预先定义Schema) |
| 计算模型 | 批处理(MapReduce) | OLTP事务处理 | 内存计算(DAG调度) |
适用场景与局限性
最佳场景:
- 离线分析(如用户画像、A/B测试)
- 历史数据归档与查询
- 数据湖核心组件(与Kafka、Flume结合)
局限性:
- 实时性差:无法满足秒级响应需求,需结合Kafka+Spark Streaming。
- 调优复杂:需手动优化分区、文件大小、并行度等参数。
- 事务支持弱:仅支持ACID属性的部分场景(如插入更新),不适合高频交易。
FAQs
问题1:Hive与MySQL的主要区别是什么?
答:
- 定位不同:Hive是面向批量分析的数仓工具,MySQL是面向事务的OLTP数据库。
- 数据量:Hive处理PB级数据,MySQL适合GB~TB级。
- 延迟:Hive查询延迟高(分钟级),MySQL可实现毫秒级响应。
- 扩展性:Hive横向扩展(依赖Hadoop集群),MySQL纵向扩展(依赖单机性能)。
问题2:如何用Hive实现近实时分析?
答:
- 方案1:结合Kafka+Spark Streaming进行实时数据处理,结果写入Hive作为历史存档。
- 方案2:启用Hive的增量查询功能(如
INSERT OVERWRITE动态分区),配合调度工具(如Airflow)定时刷新数据。 - 注意:需优化Hive分区粒度(如按小时分区而非天分区),并启用ORC/