上一篇
hive数据仓库工具的安装模式
Hive支持本地、内嵌、独立、远程及集群安装模式,适配不同部署场景
Hive数据仓库工具的安装模式详解
Hive与安装基础
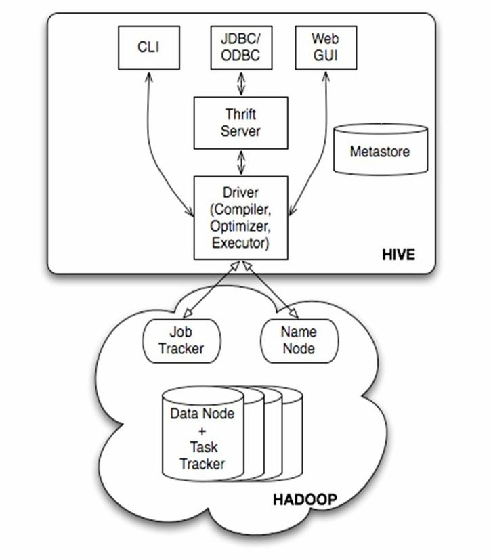
Apache Hive是基于Hadoop的数据仓库工具,支持通过SQL语法(HiveQL)查询和管理大规模数据,其核心功能依赖Hadoop生态系统(HDFS、YARN等),安装时需结合具体场景选择适配模式,以下从本地开发、生产环境、高可用架构等多维度解析Hive的安装模式。
Hive安装模式分类与对比
Hive的安装模式主要根据元数据存储方式和部署架构划分,常见模式如下表:
| 模式类型 | 元数据库 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 本地模式(Local) | 内嵌Derby数据库 | 单机学习、测试、快速验证 | 零配置,开箱即用;资源占用少 | 仅支持单用户,无法多客户端并发访问 |
| 远程模式(Remote) | 外部关系型数据库(如MySQL、PostgreSQL) | 生产环境、多用户协作 | 元数据持久化,支持多客户端共享 | 需手动配置JDBC驱动,维护成本较高 |
| 高可用模式 | ZooKeepr+MySQL/PostgreSQL | 企业级高可用集群 | 元数据自动故障转移,服务无中断 | 依赖ZooKeepr集群,配置复杂 |
| 云服务模式 | 云平台托管数据库(如AWS RDS、Azure SQL) | 云端部署、弹性扩展 | 无需运维数据库,快速集成云生态 | 依赖云服务商,成本与厂商绑定 |
各模式详细安装步骤与配置
本地模式(Local Mode)
适用场景:个人开发、功能测试、小规模数据处理。
特点:
- 使用Hive自带的嵌入式数据库Derby存储元数据。
- 数据存储依赖本地文件系统(非HDFS)。
安装步骤:
- 下载Hive二进制包(如
apache-hive-3.1.2-bin.tar.gz)。 - 解压后配置环境变量:
export HIVE_HOME=/path/to/hive export PATH=$PATH:$HIVE_HOME/bin
- 初始化元数据库:
schematool -initSchema -dbType derby
- 启动Hive CLI:
hive
局限性:

- 仅支持单节点访问,无法处理分布式数据。
- Derby数据库性能较低,不适合生产环境。
远程模式(Remote Mode with External DB)
适用场景:企业级生产环境,需多用户共享元数据。
特点:
- 元数据存储在外部关系型数据库(如MySQL、PostgreSQL)。
- 数据存储依赖HDFS,计算依赖YARN。
安装步骤:
- 准备外部数据库:
- 安装MySQL并创建数据库:
CREATE DATABASE hive_metastore;
- 授予权限:
GRANT ALL ON hive_metastore. TO 'hiveuser'@'%' IDENTIFIED BY 'password';
- 安装MySQL并创建数据库:
- 配置Hive连接外部数据库:
- 修改
hive-site.xml:<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hiveuser</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>password</value> </property>
- 修改
- 初始化元数据库:
schematool -initSchema -dbType mysql
- 启动Hive并验证连接:
hive -hiveconf hive.metastore.uris=thrift://localhost:9083
优势:
- 元数据持久化,支持多客户端并发访问。
- 可与Hadoop集群无缝集成,扩展性强。
高可用模式(HA Mode with ZooKeepr)
适用场景:大型企业集群,需保证元数据服务高可用。
特点:
- 通过ZooKeepr实现元数据服务的自动故障转移。
- 依赖至少3个ZooKeepr节点和2个Hive Metastore节点。
配置步骤:
- 部署ZooKeepr集群:
- 安装ZooKeepr并配置
zoo.cfg:tickTime=2000 initLimit=10 syncLimit=5 server.1=zk1:2888:3888 server.2=zk2:2888:3888 server.3=zk3:2888:3888
- 安装ZooKeepr并配置
- 配置Hive Metastore高可用:
- 修改
hive-site.xml启用HA:<property> <name>hive.metastore.ha.enabled</name> <value>true</value> </property> <property> <name>hive.metastore.ha.zookeeper.quorum</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://metastore1:9083,thrift://metastore2:9083</value> </property>
- 修改
- 启动Metastore节点:
- 在每个Metastore服务器上运行:
hive --service metastore &
优势:
- 在每个Metastore服务器上运行:
- 元数据服务无单点故障,提升集群可靠性。
- 支持动态扩缩容,适合大规模数据处理。
云服务模式(Cloud-Native Deployment)
适用场景:快速搭建Hive环境,无需自建基础设施。
特点:
- 使用云厂商提供的托管服务(如AWS EMR、Azure HDInsight)。
- 元数据存储在云数据库(如AWS RDS、Azure SQL)。
部署步骤(以AWS EMR为例):
- 创建EMR集群并勾选Hive组件。
- 配置元数据库为AWS RDS实例(如MySQL)。
- 通过AWS管理控制台或CLI提交Hive作业。
优势:
- 无需运维底层设施,降低人力成本。
- 弹性扩展资源,按需付费。
元数据库选型与切换策略
| 数据库类型 | 适用场景 | 切换注意事项 |
|---|---|---|
| Derby | 本地测试、临时环境 | 切换至MySQL/PostgreSQL需重新初始化元数据,需备份原有数据(仅表结构可迁移) |
| MySQL | 生产环境、中小型集群 | 确保字符集为UTF-8,版本建议5.7+,避免与Hive版本兼容性问题 |
| PostgreSQL | 高并发写入、复杂查询场景 | 需开启archive_mode并定期备份WAL日志,支持跨集群复制 |
| 云数据库 | 云端部署、弹性扩展 | 需配置公网访问或VPC私有网络,注意防火墙规则和存储容量限制 |
常见问题与解决方案(FAQs)
问题1:如何选择Hive的安装模式?
解答:
- 本地模式:适合个人学习或快速验证功能。
- 远程模式:推荐生产环境,需配合HDFS和YARN使用。
- 高可用模式:超大规模集群或关键业务场景必选。
- 云服务模式:追求快速部署且无运维资源时优先。
问题2:如何从Derby切换到MySQL作为元数据库?
解答:
- 备份原数据:导出Hive表结构(非数据)。
- 配置MySQL:创建数据库并授权用户。
- 修改Hive配置:更新
hive-site.xml中的JDBC连接参数。 - 重新初始化元数据:执行
schematool -initSchema -dbType mysql。 - 恢复表结构:通过SQL脚本重新创建Hive表。
注意:Derby数据无法直接迁移,需手动重建表