上一篇
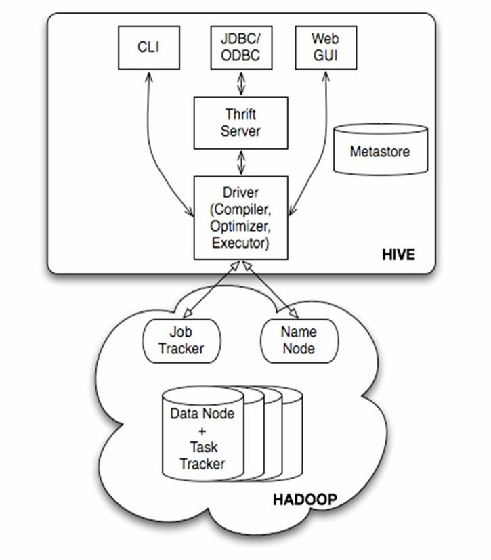
hive数据仓库数据接入模式
Hive数据仓库支持多种数据接入模式,包括批量导入(如LOAD DATA)、Sqoop同步关系库、Flume/Kafka实时流式采集,以及外部表关联多源数据,兼容 HDFS、RDBMS及日志等多样化数据源
Hive数据接入模式分类与详解
批量导入模式
- 技术实现:通过分布式文件系统(如HDFS)或专用工具(如Sqoop)将数据批量加载至Hive表。
- 典型工具:
- Sqoop:支持从关系型数据库(MySQL、Oracle等)导入数据,可并行导出至HDFS或直接加载至Hive。
- Load Data语句:直接从本地文件或HDFS路径加载数据至Hive。
- 适用场景:离线数据分析、历史数据迁移、周期性批量处理(如每日报表)。
- 优势:高吞吐量、资源利用率高、适合大规模数据。
- 局限:实时性差,需等待完整批次处理。
实时流式接入模式
- 技术实现:通过流处理框架(Kafka、Flume)将实时数据写入Hive。
- 典型工具:
- Kafka + Hive Integration:Kafka作为消息中间件,Hive通过
CREATE TABLE ... STORED BY 'org.apache.hive.hcatalog.data.provider'或第三方连接器(如Flume-Kafka)接收数据。 - Apache Flume:配置Source(如Kafka、Exec)、Channel(内存或文件)、Sink(Hive)实现日志流式写入。
- Kafka + Hive Integration:Kafka作为消息中间件,Hive通过
- 适用场景:实时监控、即时分析(如用户行为追踪、日志分析)。
- 优势:低延迟、支持持续数据流入。
- 局限:需额外维护流处理组件,资源消耗较高。
API接口模式
- 技术实现:通过Hive提供的JDBC/ODBC接口或REST API进行数据操作。
- 典型工具:
- JDBC/Thrift:允许外部应用(如BI工具、ETL工具)直接执行Hive SQL。
- REST API:通过HTTP请求提交查询或插入任务(需启用HiveServer2)。
- 适用场景:异构系统集成、临时查询、可视化工具对接。
- 优势:标准化接口、跨平台兼容。
- 局限:性能受限于网络传输,复杂操作效率较低。
消息队列集成模式
- 技术实现:结合消息队列(如RabbitMQ、Kafka)实现解耦与缓冲。
- 典型流程:
- 数据生产者将消息推送至队列。
- Hive通过消费者组件(如Kafka Connector)拉取消息并写入表。
- 适用场景:高并发数据写入、多源数据聚合。
- 优势:削峰填谷、提升系统容错性。
- 局限:需管理队列生命周期,可能引入数据延迟。
数据库同步工具模式
- 技术实现:使用Sqoop或自定义脚本同步RDBMS数据。
- 典型配置:
- 全量+增量同步:首次全量导入,后续通过时间戳或日志捕获增量数据。
- 并行导出:利用MapReduce拆分任务,加速导入。
- 适用场景:传统数据库迁移、跨库数据整合。
- 优势:支持多种数据库、自动化程度高。
- 局限:依赖源库日志或增量标识,复杂表结构处理困难。
日志采集模式
- 技术实现:通过Flume、Logstash等工具采集日志并写入Hive。
- 典型架构:
- Flume Agent:Tail日志文件 → 缓存至Channel → 写入HDFS/Hive。
- Logstash Pipeline:输入插件(Filebeat)→ 过滤(Grok解析)→ 输出至Hive。
- 适用场景:服务器日志分析、应用行为审计。
- 优势:灵活解析非结构化数据、支持实时/批量处理。
- 局限:需配置复杂的Parser规则,存储格式需与Hive表匹配。
文件系统直接对接模式
- 技术实现:将数据文件(CSV、ORC、Parquet)直接上传至HDFS,由Hive加载。
- 典型操作:
- HDFS命令:
hadoop fs -put上传文件至指定路径。 - Hive外部表:通过
EXTERNAL TABLE引用已有HDFS数据,避免数据复制。
- HDFS命令:
- 适用场景:静态数据加载、第三方数据源集成。
- 优势:操作简单、无需额外工具。
- 局限:需手动管理文件生命周期,元数据与数据易不一致。
自定义UDF/SerDe模式
- 技术实现:通过用户自定义函数(UDF)或序列化/反序列化(SerDe)扩展数据解析能力。
- 典型场景:
- 复杂数据格式:如JSON、Avro、Protobuf需自定义SerDe。
- 特殊计算逻辑:UDF实现数据清洗、转换。
- 优势:高度灵活,适应复杂需求。
- 局限:开发成本高,需熟悉Hive内部机制。
Hive数据接入模式对比表
| 模式名称 | 技术工具 | 数据类型支持 | 延迟水平 | 吞吐量 | 适用场景 |
|---|---|---|---|---|---|
| 批量导入 | Sqoop、Load Data | 结构化数据 | 高(分钟级) | 高 | 离线分析、历史数据迁移 |
| 实时流式 | Kafka、Flume | 日志、实时事件 | 低(秒级) | 中 | 实时监控、即时分析 |
| API接口 | JDBC/Thrift/REST | 结构化查询结果 | 中(秒~分钟) | 低 | 异构系统对接、临时查询 |
| 消息队列集成 | Kafka、RabbitMQ | 多源异构数据 | 中(分钟级) | 高 | 高并发写入、数据聚合 |
| 数据库同步 | Sqoop、自定义脚本 | 关系型数据库表 | 中(小时级) | 中 | 传统数据库迁移、跨库同步 |
| 日志采集 | Flume、Logstash | 非结构化日志 | 低~中 | 中 | 日志分析、行为审计 |
| 文件系统对接 | HDFS命令、外部表 | 静态文件(CSV等) | 高(人工干预) | 高 | 静态数据加载、第三方数据集成 |
| 自定义UDF/SerDe | Java UDF、SerDe插件 | 复杂格式(JSON等) | 依赖实现 | 依赖实现 | 特殊格式解析、复杂计算 |
常见问题解答(FAQs)
问题1:如何选择Hive的数据接入模式?
解答:需综合以下因素:

- 数据时效性要求:实时性高的场景(如监控)选择流式接入(Kafka/Flume),离线分析可选批量导入。
- 数据源类型:关系型数据库优先Sqoop,日志文件适用Flume,多源异构数据可结合消息队列。
- 系统复杂度:简单静态数据可直接上传HDFS,复杂格式或计算需自定义UDF/SerDe。
- 资源与性能:高吞吐量优先批量导入,低延迟场景需流式处理。
问题2:如何保障实时流式接入与批量导入的数据一致性?
解答:
- 时间戳对齐:流式数据添加摄入时间字段,批量数据同步时按时间窗口补齐。
- 分区策略:按日期或小时分区,确保两类数据写入相同分区路径。
- 事务管理:启用Hive ACID特性,结合Kafka偏移量提交机制,避免数据重复或丢失。
- 校验机制:通过Checksum或数据计数比对,定期核查流批数据