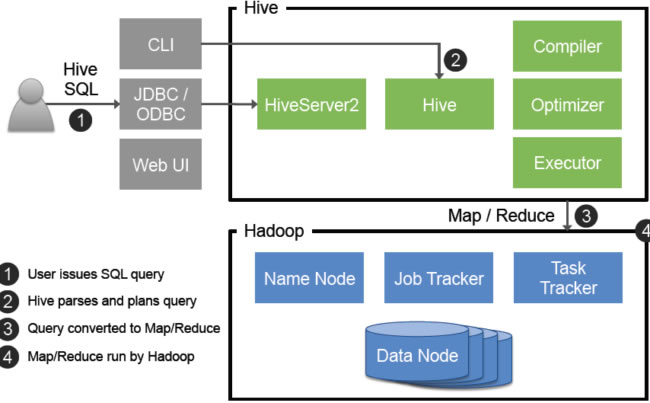
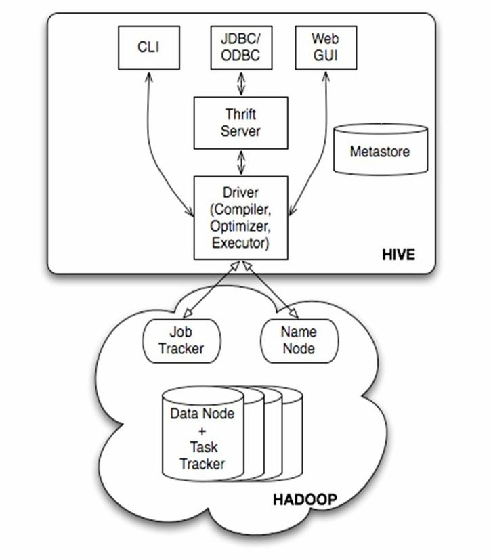
上一篇
hive数据仓库开发流程
Hive数据仓库开发流程:需求分析→数据建模→ETL设计→编写HiveQL脚本→测试与优化→部署与维护,涵盖从业务需求到数据存储查询的完整闭环
Hive数据仓库开发流程详解
Hive是基于Hadoop的数据仓库工具,其开发流程涵盖从需求分析到部署运维的全生命周期,以下是详细的开发流程及关键步骤说明:
需求分析与规划
业务需求收集
- 与业务部门沟通,明确数据分析目标(如用户行为分析、销售报表等)。
- 确定数据范围(数据源、时间跨度、粒度要求)。
- 输出《需求规格说明书》,包含核心指标、报表类型、查询频率等。
技术可行性评估
- 评估数据规模(日均增量、总量)、数据源类型(日志、数据库、API等)。
- 确定Hive版本及依赖组件(如HDFS、YARN、ZooKeeper)。
- 设计初步架构图,标注数据流向和存储层级。
资源规划
- 计算存储需求:根据数据量预估HDFS容量,设置分区策略以优化查询。
- 分配计算资源:基于作业复杂度设定YARN队列、内存及并发数。
| 需求阶段 | 关键输出 | 工具/方法 |
|---|---|---|
| 业务需求 | 需求规格说明书 | 访谈、用例分析 |
| 技术评估 | 技术选型报告 | 数据量测算、PoC测试 |
| 资源规划 | 集群资源配置表 | Hadoop容量规划工具 |
环境搭建与配置
Hadoop生态部署
- 安装Hadoop集群(HDFS+YARN),配置高可用(HA)模式。
- 部署Hive元数据服务(内嵌Derby或远程MySQL/PostgreSQL)。
- 安装Hive客户端,配置
hive-site.xml(如开启矢量化执行、优化JVM参数)。
数据源接入准备
- 创建HDFS目录结构,定义原始数据存储路径(如
/raw/logs/)。 - 配置数据导入工具(Sqoop用于关系库、Flume用于实时日志)。
- 创建HDFS目录结构,定义原始数据存储路径(如
权限管理

- 基于Linux用户和HDFS ACL设置目录权限。
- 在Hive中创建角色(如
analyst、etl_engineer),绑定权限。
数据建模与Schema设计
模型选型
- 维度建模:星型/雪花模型,适合OLAP分析(如用户-时间-地域维度)。
- 范式建模:3NF规范化表,适合事务型查询。
- 混合模型:核心事实表用维度建模,明细表用范式建模。
Schema设计原则
- 分区字段:按时间(
dt)、地域(region)等高频查询条件分区。 - 文件格式:优先ORC/Parquet(列式存储+压缩),避免Text/CSV。
- 字段类型:使用轻量类型(如
INT替代BIGINT),减少IO开销。
- 分区字段:按时间(
缓慢变化维(SCD)处理
- SCD Type 1:直接覆盖历史数据(适用于低变化维度)。
- SCD Type 2:新增版本记录,保留历史变更(如用户地址变更)。
| 模型类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 维度建模 | BI报表、多维分析 | 查询高效、易于理解 | 存储冗余 |
| 范式建模 | 事务处理、精确查询 | 数据冗余低 | 关联查询复杂 |
ETL开发与数据加载
数据抽取(Extract)
- 批量抽取:Sqoop导入MySQL/Oracle数据,支持增量同步(
--incremental)。 - 实时抽取:Flume+Kafka采集日志,写入HDFS临时目录。
- 批量抽取:Sqoop导入MySQL/Oracle数据,支持增量同步(
数据转换(Transform)
- 清洗规则:空值填充、去重、格式标准化(如时间戳转换)。
- 数据合并:使用
INSERT OVERWRITE聚合多文件,减少小文件。 - 自定义函数:开发Hive UDF处理复杂逻辑(如IP转地域)。
数据加载(Load)
- 静态分区:
PARTITION (dt)按日期加载数据。 - 动态分区:启用
hive.exec.dynamic.partition=true,自动创建分区。 - 索引优化:对高频查询字段建立Compacted/Bitmap索引。
- 静态分区:
测试与验证
单元测试
- 编写Hive SQL测试用例,验证ETL逻辑(如
COUNT对比源系统)。 - 使用框架(如Testcontainers)模拟Hive环境。
- 编写Hive SQL测试用例,验证ETL逻辑(如
性能测试
- 测试复杂查询响应时间(如
EXPLAIN分析执行计划)。 - 调整参数(
mapreduce.job.reduces、hive.auto.convert.join)优化性能。
- 测试复杂查询响应时间(如
数据校验
- 一致性检查:对比Hive表与源系统的关键指标(如订单总额)。
- 抽样验证:随机抽取记录检查转换逻辑正确性。
部署与运维
作业调度
- 使用Airflow/Oozie编排ETL任务,设置依赖关系和重试策略。
- 监控作业日志(如
/var/log/hive/),捕获异常(如数据倾斜、内存溢出)。
数据维护
- 分区管理:定期删除过期分区(
ALTER TABLE DROP IF EXISTS)。 - 文件合并:使用
Hive Concat或CombineHiveTables工具合并小文件。
- 分区管理:定期删除过期分区(
监控与优化
- 性能监控:通过HiveServer2日志分析慢查询,添加/调整索引。
- 存储优化:开启BZ2/Snappy压缩,设置
orc.compress为ZLIB。
FAQs
Q1:Hive数据仓库与传统关系型数据库的区别?
- 存储层:Hive基于HDFS分布式存储,传统数据库依赖本地磁盘。
- 计算模型:Hive使用MapReduce/Tez引擎,适合批处理;传统数据库采用索引+并行查询。
- 事务支持:Hive默认不支持ACID事务,需开启事务表;传统数据库强一致性。
Q2:如何处理Hive中的小文件过多问题?
- 合并文件:在ETL后使用
INSERT OVERWRITE DIRECTORY合并输出。 - 开启合并参数:设置
hive.merge.mapfiles=true和hive.merge.mapredfiles=true。 - 动态分区调整:减少分区粒度(如按月而非