上一篇
hive数据仓库计算引擎的答案
Hive是基于Hadoop的数据仓库计算引擎,支持类SQL的HiveQL语言,通过将查询转换为MapReduce任务实现批处理,适用于PB级 数据存储与离线分析,具备高扩展性,但延迟较高且不支持事务,与传统关系型数据库形成
Hive数据仓库计算引擎深度解析
Hive核心架构与组件
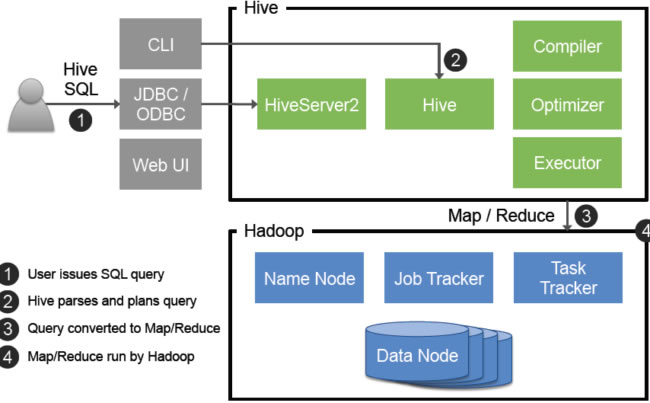
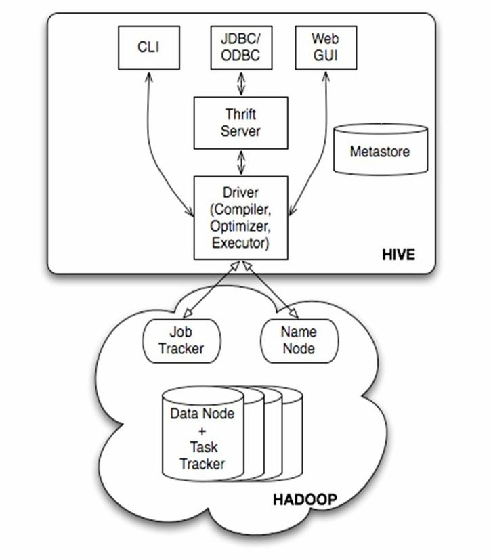
Hive是基于Hadoop的数据仓库工具,其核心架构包含以下关键组件:
| 组件 | 功能描述 |
|---|---|
| Metastore | 元数据存储系统,管理表结构、分区信息、权限等(通常依赖MySQL/PostgreSQL) |
| Driver | 客户端接口,负责解析SQL、生成执行计划、协调执行 |
| Compiler | 将SQL转换为抽象语法树(AST),进行语法分析、语义分析和优化 |
| Execution Engine | 执行引擎(如MapReduce/Tez/Spark),负责物理计划执行 |
| HDFS/Storage | 底层存储系统(如HDFS),存储实际数据文件 |
| User Interface | Beeline/CLI/JDBC等接口,供用户提交查询和管理任务 |
Hive工作流程详解
SQL解析与编译
- 用户通过SQL接口提交查询(如
SELECT FROM logs WHERE date='2023-10-01') - Compiler进行词法/语法分析,生成抽象语法树(AST)
- 元数据服务验证表/列存在性,检查权限
- 逻辑优化器转换AST为逻辑执行计划(如谓词下推)
- 用户通过SQL接口提交查询(如
物理计划生成
- 根据表存储格式(ORC/Parquet)、分区策略生成扫描计划
- 选择执行引擎(MapReduce/Tez/Spark)并生成物理执行计划
- 示例:
MAPJOIN操作会将小表加载到内存避免Shuffle
任务执行与优化
- 执行引擎拆分作业为多个Stage(如Map阶段+Reduce阶段)
- 动态优化策略:
- 倾斜数据检测:识别Key分布不均,自动启用
skew join优化 - 资源自适应:根据集群负载动态调整并行度
- 中间结果缓存:复用前序Stage的输出避免重复计算
- 倾斜数据检测:识别Key分布不均,自动启用
结果输出
- 最终结果可写入HDFS、本地文件或通过ResulfSet返回给客户端
- 支持多种文件格式(ORC/Parquet/Avro)和压缩算法(Snappy/Zlib)
Hive核心特性对比
| 特性 | Hive优势 | 局限性 |
|---|---|---|
| SQL兼容性 | 支持90%标准SQL,扩展UDTF/UDAF函数 | 复杂业务逻辑需自定义脚本 |
| 扩展性 | 水平扩展至数千节点,PB级数据处理 | MapReduce引擎在小文件场景效率较低 |
| 数据治理 | 基于ACL的细粒度权限控制,支持Kerberos认证 | 元数据管理依赖外部RDBMS性能 |
| 生态集成 | 原生兼容HDFS/YARN,支持Spark/Presto加速查询 | 与传统BI工具集成需额外适配层 |
典型应用场景
离线数据分析
- 日均处理TB级日志数据(如网站访问日志分析)
- 示例:按小时粒度统计UV/PV,生成留存报告
数据仓库建设
- 构建星型/雪花模型数据集市(如电商订单分析)
- 支持事实表与维度表关联查询,实现多维分析
ETL管道核心
- 每日定时抽取MySQL增量数据到Hive分区表
- 通过
INSERT OVERWRITE实现数据覆盖更新
机器学习特征工程
- 预处理原始数据生成训练样本(如特征拼接/归一化)
- 输出Avro格式数据集供Spark MLlib训练
性能优化策略
| 优化方向 | 具体措施 | 效果提升 |
|---|---|---|
| 数据存储优化 | 按业务字段设计分区(如date_id/country_id) | 减少全表扫描,提升查询并发能力 |
| 计算引擎调优 | 启用Tez替代MapReduce,配置Cogroup优化 | 降低任务延迟30%-50% |
| 资源配置调整 | 设置mapreduce.job.reduces=XX | 平衡Map/Reduce阶段资源利用率 |
| SQL写法改进 | 避免SELECT ,显式指定需要的列 | 减少IO开销,提升网络传输效率 |
Hive vs 其他计算引擎对比
| 对比维度 | Hive(Tez引擎) | Spark SQL | Presto |
|---|---|---|---|
| 最佳场景 | 大规模批处理、固定周期ETL任务 | 混合负载(批+流)、迭代式算法 | 交互式分析、低延迟查询 |
| 资源消耗 | 每个作业独立启动YARN容器 | 复用SparkExecutor节省启动时间 | 无持久化资源,纯内存计算 |
| 开发复杂度 | SQL语法接近标准,生态工具丰富 | 支持DataFrame API,学习曲线较平缓 | 纯SQL接口,无复杂API负担 |
| 实时性 | 分钟级延迟(依赖调度频率) | 亚秒级延迟(Streaming模式) | 秒级延迟(无数据落地) |
常见问题解答(FAQs)
Q1:Hive是否支持实时数据分析?
A1:Hive本质是批处理引擎,常规查询延迟在分钟级,对于实时需求,建议结合以下方案:
- 使用Kafka+Spark Streaming处理实时流
- 通过Hive外部表映射Impala/Presto实时查询
- 配置
Tez引擎并启用LLAP(Low Latency Abstraction Plan)加速查询
Q2:如何诊断Hive查询性能瓶颈?
A2:可按照以下步骤排查:
- 查看执行计划:启用
EXPLAIN命令检查是否产生全表扫描 - 监控资源使用:通过YARN ResourceManager观察Map/Reduce阶段耗时
- 分析数据分布:使用
ANALYZE TABLE统计分区数据量,识别倾斜Key - 检查配置参数:验证
mapreduce.job.queuename等YARN调度配置合理性 - 采样调试:对小数据集测试SQL,排除复杂逻辑导致的性能问题
本文深入解析了Hive作为数据仓库计算引擎的核心架构、工作原理及优化实践,通过对比分析帮助读者理解其在大数据生态中的定位,建议结合业务场景选择合适引擎,例如将Hive用于历史数据归档分析,搭配Presto处理即时查询