上一篇
hive数据仓库sql执行顺序
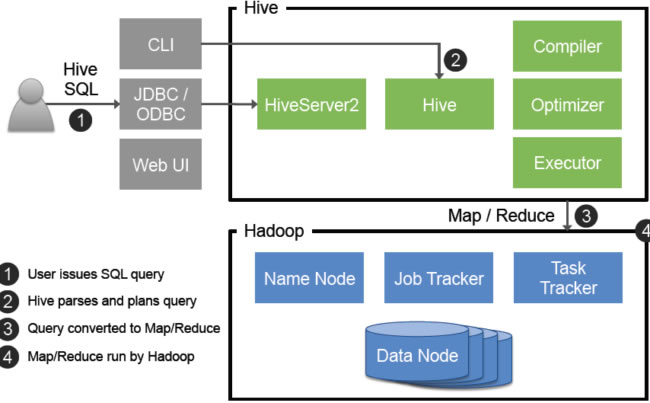
Hive SQL执行顺序:解析→语义分析→生成逻辑计划→优化器优化→生成物理计划→执行引擎运行,关键步骤包括解析、优化、计划生成及任务
Hive数据仓库SQL执行顺序详解
Hive作为基于Hadoop的数据仓库工具,其SQL执行过程与传统关系型数据库有显著差异,理解Hive SQL的执行顺序对优化查询性能、排查问题至关重要,本文将从执行流程、逻辑与物理顺序差异、优化策略等角度展开详细分析。
Hive SQL执行流程全解析
Hive SQL的执行分为多个阶段,每个阶段包含不同的操作,以下是完整的执行流程:
| 阶段序号 | 阶段名称 | 核心功能 |
|---|---|---|
| 1 | 语法解析(Parse) | 将SQL语句分解为抽象语法树(AST),检查语法正确性 |
| 2 | 语义分析(Analyze) | 验证对象存在性(表/列)、数据类型兼容性、权限校验 |
| 3 | 查询优化(Optimize) | 应用谓词下推、列裁剪、分区裁剪等优化规则生成逻辑执行计划 |
| 4 | 物理计划生成(Plan) | 将逻辑计划转换为MapReduce/Tez/Spark任务,确定数据倾斜处理策略 |
| 5 | 任务提交(Submit) | 将物理计划拆分为多个Stage,提交到资源调度系统(YARN/Mesos) |
| 6 | 数据读取(Fetch) | 从HDFS读取分区数据,根据文件格式(Text/Parquet/ORC)解析数据 |
| 7 | 计算执行(Execute) | 执行Map/Reduce任务,完成JOIN、聚合、排序等操作 |
| 8 | 结果合并(Merge) | 将多个Reducer输出合并为最终结果集,写入临时表或直接返回给用户 |
逻辑执行顺序与物理执行顺序对比
Hive SQL的逻辑执行顺序与物理执行顺序存在显著差异,这是由其分布式计算特性决定的。
逻辑执行顺序
逻辑顺序遵循SQL标准,FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
示例:
SELECT a, COUNT() FROM logs WHERE date='2023-01-01' GROUP BY a HAVING COUNT() > 10 ORDER BY a;
物理执行顺序
实际执行时,Hive会进行以下调整:

- 分区裁剪优先:根据
WHERE条件提前过滤分区(如date='2023-01-01') - 谓词下推:将过滤条件推送到数据扫描阶段
- 并行化处理:将
GROUP BY和COUNT操作分布到不同节点 - 排序阶段后置:
ORDER BY通常在最终阶段执行
关键差异:
| 逻辑阶段 | 物理执行特征 |
|—————-|———————————————|
| FROM | 可能延迟到分区裁剪之后 |
| WHERE | 可能被拆解到多个Stage(如分区过滤+文件过滤) |
| JOIN | 转换为Map端Shuffle或Reduce端Join |
| ORDER BY | 触发全局排序,产生额外Stage |
Hive SQL执行计划生成过程
通过EXPLAIN命令可查看执行计划,典型输出包含以下关键信息:
EXPLAIN SELECT FROM orders WHERE customer_id = 'C001';
输出示例:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan: orders (filter: customer_id = 'C001')
Filter Operator: customer_id = 'C001' (filter applied)
Reduce Operator Tree:
File Output Operator执行计划解析:
- Stage划分:每个Stage代表一个独立的MapReduce任务
- 操作符树:描述数据流动路径(如TableScan→Filter→Reduce)
- 过滤标记:显示谓词下推位置(如
Filter Operator在Map阶段) - 倾斜提示:标注可能存在数据倾斜的操作符
影响执行顺序的关键因素
Hive实际执行顺序受多种因素影响:
| 影响因素 | 作用机制 |
|---|---|
| 分区设计 | 分区字段在WHERE条件中可触发分区裁剪,减少扫描量 |
| 文件格式 | ORC/Parquet格式支持列式存储和索引,优化扫描效率 |
| JOIN类型 | 大表JOIN小表时,小表会被缓存(Broadcast)以减少数据倾斜 |
| 资源分配 | YARN队列配置决定并发度,影响Stage执行顺序 |
| 数据倾斜处理 | 启用hive.groupby.skewindata=true会自动添加分布式聚合阶段 |
性能优化与执行顺序关联
优化策略需结合执行顺序特点:
| 优化方向 | 具体措施 |
|---|---|
| 减少数据扫描量 | 利用分区裁剪(PARTITIONED BY)、文件格式优化(ORC+Snappy压缩) |
| 避免全局排序 | 用DISTRIBUTE BY替代ORDER BY,减少Reducer阶段 |
| 控制Stage数量 | 合并小查询为单一作业,避免过多Job启动开销 |
| 处理数据倾斜 | 对KEY倾斜字段使用RANDOM前缀打散数据,或启用倾斜检测阈值 |
| 内存配置 | 调整mapreduce.map.memory.mb和mapreduce.reduce.memory.mb提升执行效率 |
常见问题与解决方案
FAQs:
Q1:为什么Hive子查询性能比JOIN差?
A:子查询会生成独立Stage,导致多次数据扫描和中间结果落地,建议将子查询改写为JOIN,
-低效子查询 SELECT a FROM table1 WHERE a IN (SELECT a FROM table2); -优化为JOIN SELECT a FROM table1 JOIN table2 ON table1.a = table2.a;
Q2:如何查看Hive执行计划中的数据流向?
A:使用EXPLAIN EXTENDED命令并开启hive.explain.user=true,可查看详细的操作符依赖关系。
SET hive.explain.user=true; EXPLAIN EXTENDED SELECT /+ STREAMTABLE / a FROM table;
Hive SQL的执行顺序是逻辑规则与物理优化的结合体,开发者需理解:
- 逻辑顺序决定语义正确性
- 物理顺序影响性能表现
- 优化需从分区设计、文件格式、资源分配多维度入手
通过EXPLAIN分析执行计划、合理设计表结构、充分利用Hive优化特性,可显著提升复杂查询