上一篇
hive数据仓库工具简介
Hive是基于Hadoop的数据仓库工具,支持SQL-like查询,将SQL转换为MapReduce任务,适用于大规模数据存储、
Hive数据仓库工具详解
Hive是由Apache基金会开发的一款基于Hadoop的数据仓库工具,专为处理大规模结构化数据设计,它通过类SQL的查询语言(HiveQL)实现对分布式存储数据的分析和计算,底层依赖Hadoop的HDFS存储和MapReduce计算框架,以下从核心概念、架构设计、功能特性、应用场景等角度展开详细介绍。
Hive的核心概念
| 概念 | 说明 |
|---|---|
| HiveQL | Hive的查询语言,语法与SQL高度兼容,支持SELECT、JOIN、GROUP BY等操作。 |
| Metastore | 元数据存储系统,用于管理表结构、分区、权限等信息,默认基于关系型数据库(如MySQL)。 |
| SerDe(Serializer/Deserializer) | 数据序列化与反序列化接口,支持多种数据格式(如Text、JSON、Avro、ORC)。 |
| UDF(User-Defined Function) | 用户自定义函数,用于扩展HiveQL的功能(如复杂字符串处理、时间计算)。 |
| Partitioning | 分区表功能,按业务维度(如日期、地区)划分数据,提升查询效率。 |
| Bucketing | 分桶表功能,将数据按哈希分配到不同桶中,优化特定场景下的查询性能。 |
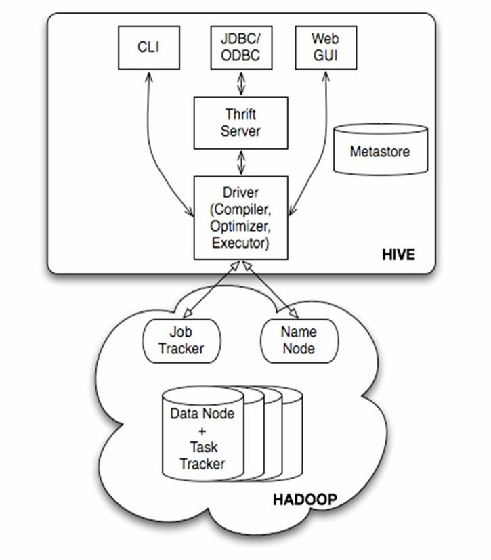
Hive架构解析
Hive采用典型的“客户端-服务端”架构,核心组件包括:
Client(客户端)
- 提交HiveQL脚本或命令,触发查询任务。
- 支持CLI、JDBC、Thrift等多种接口。
Driver(驱动层)
- 编译HiveQL为MapReduce任务,生成执行计划。
- 管理资源调度(可集成YARN或Tez优化资源分配)。
Metastore(元数据服务)
- 存储表结构、分区、权限等元数据,通常由独立数据库(如MySQL)支撑。
- 支持单点部署或高可用集群模式。
Execution Engine(执行引擎)
- 默认基于MapReduce,也可替换为Tez或Spark以提高执行效率。
- 负责实际的数据扫描、过滤、聚合等操作。
HDFS(存储层)
数据以文件形式存储在HDFS中,支持文本、列式存储(如ORC/Parquet)等格式。
架构图示
+------------------+ +-----------------------+ +-------------+
| Client | ----> | Driver | ----> | Metastore |
+------------------+ +-----------------------+ +-------------+
|
v
+--------------------------------------------+ +--------------------+
| | | |
| Execution Engine | | HDFS |
| (MapReduce/Tez/Spark) | | (Data Storage) |
| | | |
+--------------------------------------------+ +--------------------+ Hive的核心特性
SQL兼容性
- 支持大部分标准SQL语法,降低学习成本。
- 提供窗口函数、CTE(公共表表达式)等高级特性(Hive 3.0+)。
存储与计算分离
数据存储在HDFS,计算任务由Hadoop集群处理,天然支持横向扩展。
分区与分桶优化
- 分区:按业务维度(如
dt分区)减少全表扫描。 - 分桶:按字段哈希分桶,提升JOIN和聚合效率。
- 分区:按业务维度(如
多样化存储格式
| 格式 | 特点 | 适用场景 |
|———|—————————————|————————-|
| Text | 纯文本存储,无压缩 | 小规模数据或临时测试 |
| ORC | 列式存储,高效压缩与向量化读取 | 大数据分析(推荐) |
| Parquet | 列式存储,广泛兼容其他大数据工具(如Spark) | 跨引擎数据共享 |
| Avro | Schema演化友好,适合动态数据结构 | 日志流式处理 |UDF扩展能力
支持Java/Python编写自定义函数,解决内置函数无法满足的需求。
Hive的优势与局限性
优势
- 海量数据处理:依托HDFS,可轻松处理PB级数据。
- 低成本:基于开源Hadoop生态,硬件扩展灵活。
- 生态兼容:与Sqoop(数据导入)、Oozie(工作流调度)、Superset(可视化)等工具无缝集成。
局限性
- 实时性不足:适合批处理,分钟级延迟场景需结合流处理工具(如Kafka+Flink)。
- 功能受限:某些复杂SQL语法(如子查询)支持不完善,需依赖HiveQL特性。
- 依赖Hadoop:需配置HDFS和YARN,运维复杂度较高。
典型应用场景
日志分析
示例:Web服务器日志按日期分区存储,通过HiveQL统计UV/PV、错误率等指标。
数据仓库建设
示例:将多源数据(如MySQL、Kafka)导入Hive,构建星型/雪花模型,支撑BI报表。
ETL任务
示例:每日定时清洗用户行为数据,生成宽表供下游分析。
Hive安装与快速入门
环境准备
- Hadoop集群(HDFS + YARN)。
- Metastore数据库(如MySQL)。
- JDK 8+、Maven(编译源码时需要)。
部署步骤
- 下载Hive二进制包并解压。
- 配置
hive-site.xml(连接Metastore和HDFS)。 - 初始化Metastore:
schematool -initSchema。 - 启动Hive CLI,创建第一个表:
CREATE TABLE user_log ( uid STRING, action STRING, ts TIMESTAMP ) STORED AS ORC;
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 数据存储 | 使用ORC/Parquet格式,开启压缩(SNAPPY/ZLIB)。 |
| 分区设计 | 按高频查询字段(如日期)分区,避免过度分区。 |
| 执行引擎 | 替换MapReduce为Tez或Spark,提升任务并行度。 |
| 资源配置 | 调整MapReduce的mapreduce.job.reduces参数,控制并发数。 |
| 索引与缓存 | 对热数据创建本地索引(COMPACTED格式),启用LLD(Last Level Directory)缓存。 |
Hive vs 传统数据库对比
| 维度 | Hive | 传统数据库(如MySQL) |
|---|---|---|
| 数据规模 | PB级(依赖HDFS) | GB~TB级 |
| 扩展性 | 横向扩展(加节点即可) | 纵向扩展(依赖硬件升级) |
| 实时性 | 批处理(分钟级延迟) | 低延迟(毫秒级) |
| 成本 | 低成本(开源软件+普通PC服务器) | 高成本(商业授权+高端硬件) |
| 适用场景 | ETL、离线分析、历史数据归档 | 在线事务处理(OLTP)、实时查询 |
FAQs
Q1:Hive与SQL数据库的主要区别是什么?
A1:Hive专为批量处理设计,依赖HDFS存储和MapReduce计算,适合PB级数据分析;而SQL数据库(如MySQL)面向在线事务处理,强调低延迟和ACID特性,适用于高并发读写场景。
Q2:如何优化Hive查询性能?
A2:可通过以下方式优化:
- 数据存储优化:使用列式存储(如ORC)、开启压缩、合理设计分区。
- 执行引擎优化:替换MapReduce为Tez/Spark,减少任务耗时。
- 资源配置调整:根据集群资源动态分配Mapper/