
上一篇
hdfs存储文件格式
HDFS采用块存储格式,默认块大小128MB,文件分块 存储,支持多副本机制,块信息由NameNode管理,数据由Data
HDFS存储文件格式深度解析与选型指南
HDFS存储格式核心特性
Hadoop分布式文件系统(HDFS)作为大数据存储基石,其文件格式直接影响数据读写性能、存储效率和计算兼容性,主流存储格式在数据组织方式、压缩能力、元数据处理等方面存在显著差异,需根据业务场景进行科学选型。
主流存储格式技术对比
| 格式 | 数据结构 | 压缩支持 | Schema支持 | 数据类型 | 适用场景 | 优点 | 缺点 |
|————-|——————-|—————-|————|—————|————————–|——————————-|——————————-|
| Text | 纯文本 | 无 | 无 | 字符串 | 日志文件、配置文件 | 人类可读,编辑方便 | 存储冗余,处理效率低 |
| SequenceFile| 二进制键值对 | 块/记录压缩 | 可选 | 基本数据类型 | 日志聚合、中间数据存储 | 空间占用小,支持压缩 | 无Schema约束,数据校验弱 |
| Avro | 带Schema的二进制 | 多种压缩编码 | 强制 | 复杂数据结构 | 数据交换、ETL处理 | 紧凑存储,跨语言兼容 | Schema演化成本高 |
| Parquet | 列式存储 | 高效压缩 | 强支持 | 嵌套数据结构 | OLAP分析、BI系统 | 查询效率高,压缩比优异 | 写入复杂度高,小文件不友好 |
| ORC | 优化列式存储 | 高效压缩 | 强支持 | 复杂数据类型 | Hive分析、实时计算 | 极致压缩,查询优化完善 | 生态绑定性强,跨系统兼容性差 |
| Protobuf | 协议缓冲二进制 | 可选压缩 | 动态生成 | 自定义消息 | RPC通信、服务间数据交换 | 空间利用率高,版本兼容好 | 学习成本高,调试困难 |
格式技术细节解析
Text格式特性
- 采用换行符分隔记录,UTF-8编码
- 适合非结构化/半结构化数据
- 典型应用:网站日志、爬虫结果
- 性能瓶颈:文本解析开销大(约占CPU消耗30%)
- 优化方案:结合CombineFileInputFormat减少寻址
SequenceFile深度解析
- 二进制存储键值对(Key/Value)
- 支持压缩类型:RECORD/BLOCK/NONE
- 压缩比对比:
压缩类型 | 典型压缩比 | 解压开销
———|————|———-
RECORD | 1:1 | 低
BLOCK | 1:3 | 中
NONE | 1:1 | 无 - 适用场景:MapReduce中间结果传递
- 性能特征:顺序读写速度达500MB/s+
Avro技术架构
- 基于Schema的自描述数据格式
- 支持三种数据类型:Primitive/Complex/Logical
- 序列化机制:二进制编码+JSON Schema
- 压缩算法:Deflate/Snappy/BZ2/LZ4
- 版本兼容:通过字段默认值实现向前兼容
- 典型应用:跨语言数据传输(Java/Python/C++)
Parquet存储原理

- 基于Apache Drill项目发展而来
- 列式存储引擎支持三种编码:
- Plain:原始存储
- Dictionary:字典编码(重复值多时压缩率提升40%)
- Run-Length:游程编码(连续数据压缩)
- 页式存储结构:
Header | RowGroup | ColumnChunk | Page - 支持嵌套结构(Repeated/Optional字段)
- 典型压缩比:Snappy压缩下可达1:8
ORC存储优化
- 专为Hive优化的列式存储
- 创新技术:
• Lightweight Index(索引开销降低60%)
• Bloom Filter(查询加速30%)
• Hybrid Compression(混合压缩策略) - 存储单元:Stripe(默认HDFS块大小)
- 统计信息存储:Histogram/MinMax
- Hive集成优势:自动识别分区/桶信息
格式选型决策树
结构化数据处理流程
原始日志(Text)→ 清洗转换(SequenceFile)→ 中间存储(Parquet)→ 分析计算(ORC)关键选型要素矩阵
| 评估维度 | Text | SeqFile | Avro | Parquet | ORC |
|—————|————|————|———–|————|———–|
| 存储效率 | | | | | |
| 查询性能 | | | | | |
| 压缩能力 | 无 | 中等 | 强 | 极强 | 极强 |
| Schema灵活性 | 无 | 弱 | 中 | 强 | 强 |
| 生态兼容性 | 广 | 中 | 广 | 分析生态 | Hive生态 |
| 写入复杂度 | 低 | 低 | 中 | 高 | 高 |
典型应用场景方案
实时日志处理管道
LogCollector → Text → Kafka → SequenceFile → Spark → Parquet → HiveETL数据仓库建设
源数据(CSV)→ Avro → Hive ORC → Impala分析 → Superset可视化机器学习特征存储
Raw Data → TFRecord → Parquet → XGBoost训练 → Model持久化
性能优化实践
Parquet文件优化技巧
- 设置合理RowGroup大小(建议128MB)
- 启用字典编码(dic_encoding=”dictionary”)
- 调整最大页尺寸(page_size=1MB)
- 开启统计信息收集(enable_statistics=true)
ORC文件压缩策略
- SNAPPY压缩:平衡压缩比和速度
- ZLIB压缩:最高压缩比(CPU消耗增加20%)
- 混合策略:前10%数据用ZLIB,后续用SNAPPY
跨格式转换损耗控制
转换路径 | 注意事项
————–|———————————–
Text→Avro | 确保字段类型严格匹配
SeqFile→Parquet | 处理NULL值填充策略
ORC→Parquet | 重建统计信息元数据
常见误区辨析
误区1:追求极致压缩比总最优
真相:高压缩比带来CPU消耗增加,需权衡IO/CPU资源比例,建议生产环境压缩比控制在1:5以内。
误区2:所有场景都应使用列式存储
真相:频繁更新的场景(如事务处理)仍适合行式存储,列式存储在OLAP场景优势明显。
误区3:Schema定义越严格越好
真相:过度严格的Schema会导致数据适配困难,建议核心字段严格定义,扩展字段保持灵活。
FAQs:
Q1:如何判断业务场景应该选择哪种存储格式?
A1:首先评估数据特征:①结构化程度(是否包含嵌套字段)②访问模式(随机访问频率)③更新需求(是否频繁修改),其次考虑系统生态:①是否需要Hive集成②跨平台数据交换需求,最后进行性能测试,重点关注三个方面:存储空间占用、查询延迟、写入吞吐,建议建立测试基准,使用真实数据样本进行压力测试。
Q2:从Text格式迁移到Parquet格式需要注意哪些技术细节?
A2:迁移过程需分三步走:①Schema设计阶段,需明确字段类型映射规则(如Text的字符串转为Parquet的String类型),处理缺失值填充策略;②数据转换阶段,建议使用Spark DataFrame API进行转换,注意空值处理和字符编码转换;③验证阶段,需比对原始数据和转换后数据的行数、校验和、抽样内容,特别注意处理Text格式中的特殊字符转义问题,以及Parquet的嵌套结构设计,迁移后建议保留原始数据作为备份
相关文章
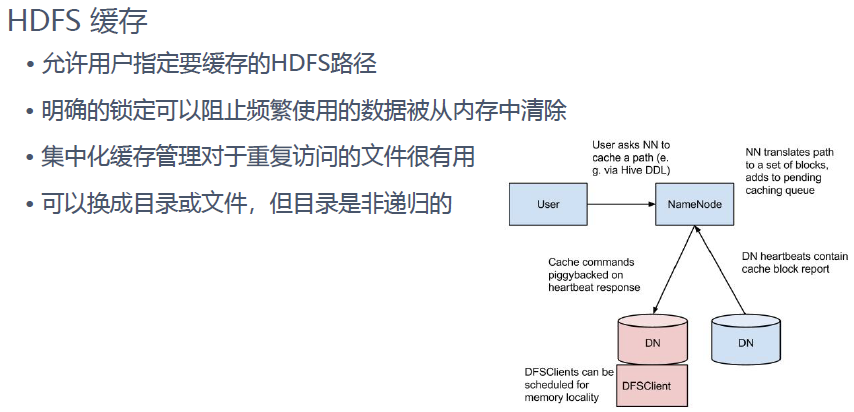
hdfs的存储文件格式
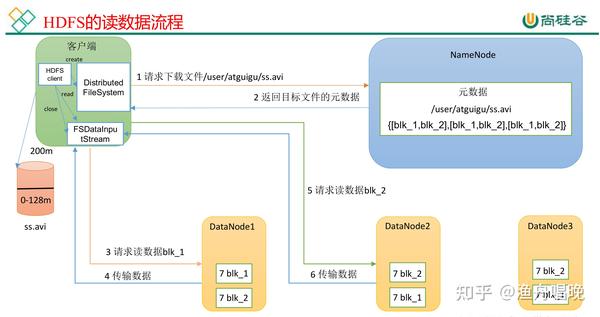
爬虫数据存储hdfs_HDFS数据
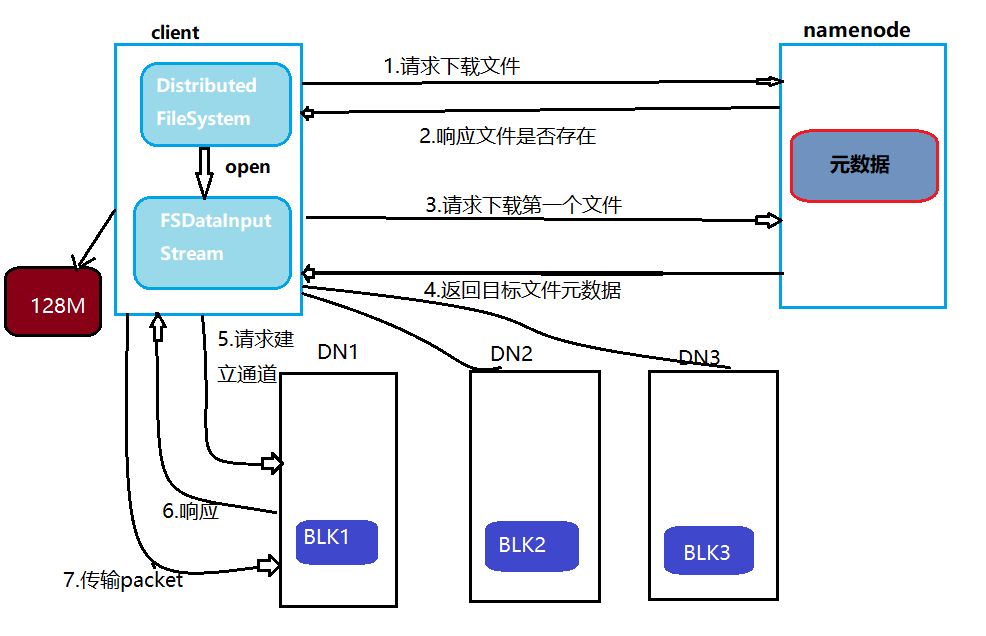
DFS挂载文件存储HDFS

包含图像文件的文件格式有哪些,下列文件扩展中,不是常用的图像文件格式的词条
格式化一词在计算机领域通常指的是对存储设备(如硬盘、USB驱动器等)进行的一种操作,该操作会删除设备上的所有数据,并设置一个全新、干净的文件系统。这个过程通常用于清理干扰、修复文件系统错误或准备将设备出售或赠与其他人。,原创疑问句标题,,格式化操作究竟意味着什么?,为何我们需要对存储设备执行格式化?,格式化后的数据能否恢复?,格式化过程中发生了什么技术变化?,如何安全地进行格式化以避免数据泄露?

MySQL数据库文件格式揭秘,文件格式介绍中的奥秘是什么?
客户端向服务器存文件格式_文件格式介绍
mkv文件格式「mkv文件格式用什么播放器」

hdfs存储机制是什么







