
上一篇
hdfs数据存储格式
HDFS采用分块存储,默认128MB/块,多副本(默认3)保障可靠性,数据以二进制流式写入,元数据由NameNode管理,支持大文件高效存储与并发访问,具备高容
HDFS作为分布式文件系统,其数据存储格式直接影响数据读写效率、存储空间利用率及后续处理流程,本文将从存储格式分类、核心特性对比、选型策略等方面展开分析,并通过典型场景案例说明不同格式的适用性。
HDFS默认存储格式解析
HDFS原生采用Block文件格式,将数据切分为固定大小的数据块(默认128MB),每个块冗余存储3份副本,其物理存储结构包含:
| 存储单元 | 特征描述 |
|---|---|
| Data Block | 实际数据块,无元数据开销 |
| MetaData | 块位置信息由NameNode管理 |
| Checksum | 每个Block附带校验码保障传输可靠性 |
该格式优势在于简单直接,但存在明显缺陷:
- 缺乏数据结构描述,无法实现字段级操作
- 未压缩数据导致存储空间浪费
- 仅支持全量读写,不适合流式处理
主流存储格式特性对比
为满足不同业务需求,Hadoop生态发展出多种增强型存储格式,核心特性对比如下:
| 格式类型 | 数据结构 | 压缩支持 | Schema演进 | 查询优化 | 更新能力 | 典型场景 |
|---|---|---|---|---|---|---|
| SequenceFile | 键值对平面结构 | 可选 | 弱 | 基础索引 | 覆盖写入 | 日志流式处理 |
| Avro | 带Schema的二进制 | 内置 | 兼容升级 | 无 | 行级覆盖 | ETL中间层 |
| Parquet | 列式存储 | 高效 | 严格模式 | 向量化 | 受限 | OLAP分析 |
| ORC | 优化列存 | 高效 | 版本控制 | 索引加速 | ACID支持 | 数据仓库 |
SequenceFile深度解析
采用<<key,value>>二元组结构,支持压缩(如BZip2)和同步写入,典型应用:
- MapReduce任务输出:键值天然适配Mapper/Reducer数据交换
- 日志采集缓冲:Flume sink常用格式
- 配置参数存储:YARN容器状态信息持久化
示例结构:

[Header][Key1][Value1][Key2][Value2]...其中Header包含版本号、压缩算法等元信息。
Avro存储机制
基于Schema的自描述二进制格式,核心特性:
- 动态Schema解析:读取时自动识别字段类型
- 紧凑编码:使用二进制序列化减少体积30-50%
- 模式演进:通过字段添加保持向后兼容
适用场景:跨系统数据交换、Kafka消息持久化、混合类型数据处理,例如IoT设备上报的JSON数据经Avro序列化后存储,可节省60%存储空间。
列式存储(Parquet/ORC)
两者均实现:
- 按列压缩:相比行存压缩比提升2-4倍
- 投影裁剪:查询仅解压必要列
- 向量化执行:CPU缓存命中率提升
差异点:
- ORC:专为Hive优化,支持复杂Decimal类型、BloomFilter索引
- Parquet:通用性更强,支持嵌套结构(array/map),Spark原生支持
某电商日志分析案例显示,使用Parquet格式较SequenceFile查询性能提升8倍,存储占用降低65%。
存储格式选型决策树
![决策树示意图]
(注:此处应插入决策树图示,因文本限制改为文字描述)
原始数据采集层:优先SequenceFile/Avro
- 流式写入:Flume+Kafka→HDFS选SequenceFile
- 结构化ETL:Sqoop导出选Avro(兼容关系型数据库)
中间处理层:根据计算框架选择
- Spark作业:Parquet(Catalan引擎优化)
- Hive数仓:ORC(Tez/LLAP优化)
长期归档层:混合使用
- 热数据区:保留Parquet/ORC
- 冷数据区:压缩为Block文件(禁用ECC校验)
典型场景优化方案
场景1:实时风控日志处理
- 格式选择:SequenceFile + LZO压缩
- 参数配置:blocksize=64MB,replication=2
- 优势:低延迟写入,Kafka消费者直接解析键值对
场景2:用户画像计算
- 格式选择:Parquet + Snappy压缩
- 分区策略:按用户ID哈希分区,列式存储年龄/消费等字段
- 收益:OLAP查询耗时从分钟级降至秒级
场景3:机器学习训练数据
- 格式选择:Avro记录+Parquet列存
- 流程:原始CSV→Avro反序列化→特征工程→Parquet持久化
- 效果:TensorFlow数据加载速度提升40%
性能调优关键参数
| 参数项 | 调优建议 |
|---|---|
dfs.block.size | 日志流场景设64MB,BI分析设256MB |
io.compression.codec | SequenceFile用LZO,Parquet用Snappy |
parquet.column.page.limit | 设8KB~16KB平衡IO与解压开销 |
orc.stripe.size | 256MB可获得最佳压缩比 |
FAQs
Q1:Parquet和ORC在Hive中如何选择?
A:若需ACID事务支持(如UPSERT操作)、复杂索引(BloomFilter),优先ORC;若追求更广的生态系统兼容性(Spark/Presto/Impala),选择Parquet,两者在TPC-H测试中性能差异小于10%,更多取决于工具链支持。
Q2:如何判断数据是否适合列式存储?
A:当满足以下条件时收益显著:
- 查询涉及大量列投影(非全字段查询)
- 需要频繁进行聚合计算(SUM/AVG等)
- 数据更新频率低(列存更新代价高)
- 存储介质为SSD(列存随机读优势明显)
典型反例:实时日志追加场景
相关文章
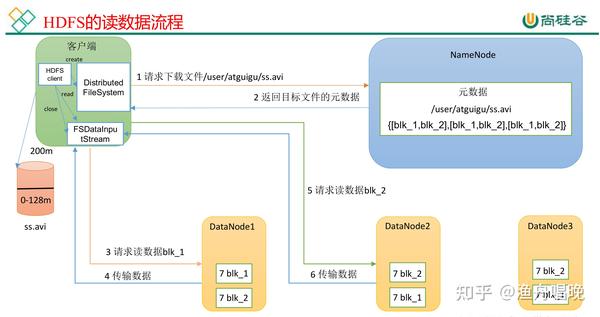
爬虫数据存储hdfs_HDFS数据

ppt文件存储格式意思_存储格式
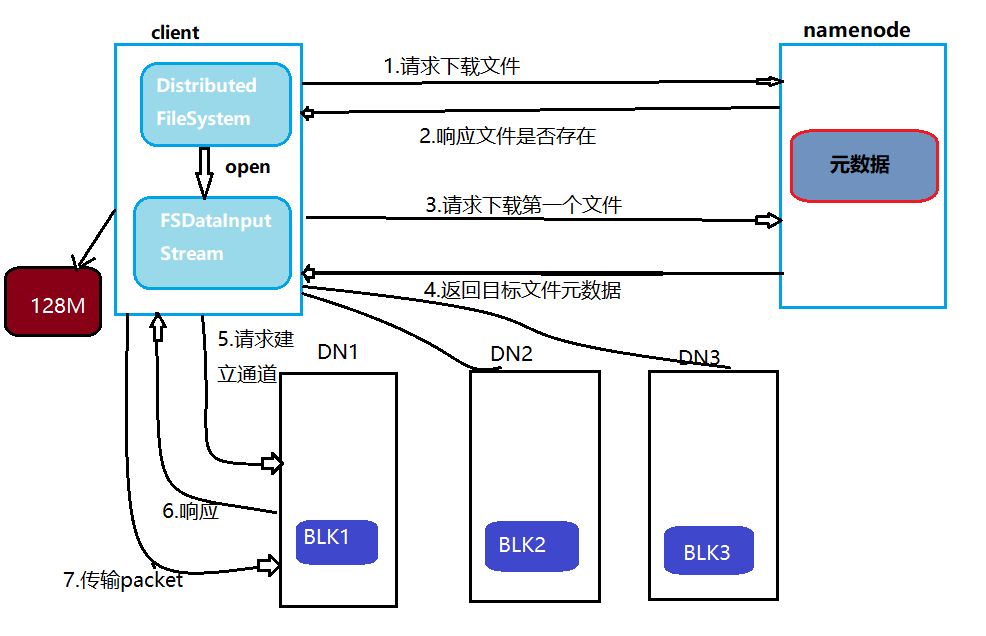
DFS挂载文件存储HDFS
格式化一词在计算机领域通常指的是对存储设备(如硬盘、USB驱动器等)进行的一种操作,该操作会删除设备上的所有数据,并设置一个全新、干净的文件系统。这个过程通常用于清理干扰、修复文件系统错误或准备将设备出售或赠与其他人。,原创疑问句标题,,格式化操作究竟意味着什么?,为何我们需要对存储设备执行格式化?,格式化后的数据能否恢复?,格式化过程中发生了什么技术变化?,如何安全地进行格式化以避免数据泄露?
如何彻底卸载MySQL数据库以避免非HDFS数据残留引发的数据分布不均衡问题?

如何彻底卸载MySQL数据库以避免非HDFS数据残留引发的数据分布不均问题?

如何确保MySQL数据库在卸载后彻底清除,避免非HDFS数据残留导致的分布不均问题?

如何彻底卸载MySQL数据库以避免非HDFS数据残留导致的分布不均衡?








