
上一篇
hdfs的存储文件格式
HDFS采用块存储,文件分块后多副本分布存储,由NameNode管理元数据,DataNode存储数据,支持高
HDFS(Hadoop Distributed File System)作为大数据存储的核心组件,其存储文件格式直接影响数据处理的效率、存储成本和系统性能,本文将从HDFS支持的存储格式分类、典型格式特性对比、应用场景分析及最佳实践建议等方面展开详细阐述。
HDFS存储文件格式分类
HDFS支持多种文件存储格式,主要分为文本类格式、二进制序列化格式和列式存储格式三大类,具体分类如下:
| 类别 | 典型格式 |
|---|---|
| 文本类格式 | Text、CSV、JSON |
| 二进制序列化格式 | SequenceFile、Avro、Protobuf |
| 列式存储格式 | Parquet、ORC、RCFile |
| 压缩格式 | Snappy、GZIP、BZIP2、LZO(常与其他格式结合使用) |
典型存储格式特性对比
以下是HDFS中常用存储格式的关键特性对比:

| 特性 | Text | SequenceFile | Avro | Parquet | ORC | CSV/JSON |
|---|---|---|---|---|---|---|
| 数据结构 | 纯文本 | Key-Value二进制 | Schema-less | 列式+Schema | 列式+复杂类型 | 无Schema |
| 压缩支持 | 差(可外部压缩) | 内置(可选) | 内置 | 高效压缩 | 高效压缩 | 差 |
| 随机访问 | 差 | 中等(需解码) | 中等 | 优秀 | 优秀 | 差 |
| 读写性能 | 慢(解析开销大) | 较快 | 快 | 快(向量化) | 快(向量化) | 慢 |
| 存储空间 | 大 | 中等 | 小 | 小(列式压缩) | 小(列式压缩) | 大 |
| Schema兼容性 | 无 | 弱 | 强(动态演化) | 强(严格校验) | 强(严格校验) | 弱 |
| 适用场景 | 日志、配置文件 | MapReduce中间结果 | 通用数据交换 | OLAP分析 | OLAP分析 | 简单数据导入 |
核心存储格式深度解析
Text格式
- 原理:按行存储纯文本数据,每行以分隔。
- 优点:人类可读,兼容任何文本编辑器。
- 缺点:无数据结构定义,解析开销高,存储空间大(如JSON/CSV需大量引号和分隔符)。
- 典型应用:日志文件(如Nginx日志)、临时配置文件。
SequenceFile
- 原理:二进制键值对结构,支持压缩(默认采用Block压缩)。
- 组成:Header(元数据)+ Key(排序字段)+ Value(数据体)。
- 优势:支持Splitable(按Key分片),适合MapReduce任务;压缩后存储节省空间。
- 局限:需手动管理Key设计,不适合复杂嵌套数据。
- 适用场景:MapReduce中间结果存储、小文件合并。
Avro
- 原理:基于Schema的二进制序列化,支持动态Schema演化。
- 核心特性:
- 无Schema时自动推导
- 兼容新旧字段(新增字段默认填充默认值)
- 支持复杂数据类型(数组、Map、Union)
- 优势:解决JSON的冗余问题,读写性能优于文本格式。
- 典型应用:跨系统数据交换(如Kafka与HDFS交互)、ETL临时存储。
Parquet与ORC
共同特性:
- 列式存储,按需读取列数据
- 支持复杂数据类型(嵌套结构、数组)
- 高效压缩(如Snappy压缩比达3:1)
- 向量化读写(CPU缓存友好)
差异对比:
| 特性 | Parquet | ORC |
|—————-|————————–|————————–|
| 起源 | Twitter/Cloudera | Hortonworks |
| 压缩算法 | Snappy/LZ4/ZSTD | Optimized ORC压缩 |
| 索引支持 | 3级目录(RowGroup→Column Chunk→Page) | 更细粒度索引 |
| 适用场景 | 通用数据分析 | 高并发OLAP查询(如Hive) |优势:
- 存储节省50%-80%(相比Text/CSV)
- 查询性能提升10倍+(仅需读取必要列)
- 支持谓词下推(Predicate Pushdown)
局限:写入时需预定义Schema,修改成本高。
存储格式选择策略
| 决策因素 | 建议方案 |
|---|---|
| 数据类型 | 结构化→Parquet/ORC;半结构化→Avro;非结构化→Text/SequenceFile |
| 读写模式 | 批量分析→列式格式;实时流→Avro;小文件合并→SequenceFile |
| 压缩需求 | 高压缩比→ORC+Zlib;平衡性能→Parquet+Snappy |
| 计算引擎兼容性 | Spark→Parquet;Hive→ORC;Flink→Avro |
| Schema稳定性 | 频繁变更→Avro;固定Schema→Parquet/ORC |
最佳实践与常见误区
最佳实践
- 列式格式优先:对分析型业务(如BI、机器学习),优先选择Parquet/ORC以降低存储和计算成本。
- 混合存储策略:原始数据用Avro/SequenceFile存储,加工后转为列式格式。
- 压缩算法匹配:对CPU敏感场景用Snappy,存储优先场景用Zlib。
- 版本控制:通过Avro的Schema演化或Parquet的
writer版本管理应对数据变更。
常见误区
- 误区1:认为所有数据都应转成Parquet。
纠正:日志等非结构化数据用Text/SequenceFile更高效。 - 误区2:忽略文件大小与Split关系。
纠正:HDFS Block大小(默认128MB)应与文件Split粒度匹配,避免过多小文件。 - 误区3:过度追求压缩比。
纠正:高压缩算法(如BZIP2)会增加CPU开销,需权衡计算资源。
FAQs
Q1:如何判断是否应该将数据从Text转换为Parquet?
A:若数据用于分析且包含多列,且满足以下条件之一,建议转换:
- 查询仅涉及部分列(如只分析”年龄”和”收入”字段)
- 需要压缩存储(如原始CSV占用10GB,Parquet可压缩至2GB)
- 频繁执行聚合、过滤等操作
转换步骤:
- 定义Parquet Schema(与CSV头对应)
- 使用
spark.read.csv().write.parquet()或HiveCREATE TABLE语句转换 - 验证数据一致性和查询性能提升
Q2:Avro和Parquet能否混合使用?如何保证兼容性?
A:可以混合使用,但需注意:
- 读写顺序:Avro→Parquet需先解析Schema,Parquet→Avro需提取Schema信息
- 兼容性处理:
- Avro允许新增字段(默认填充null),而Parquet要求严格Schema匹配
- 通过中间格式(如JSON)或统一Schema工具(如
avro-tools)转换
- 推荐场景:Avro用于数据采集层,Parquet用于存储层,通过ETL工具(如Spark)完成转换。
相关文章
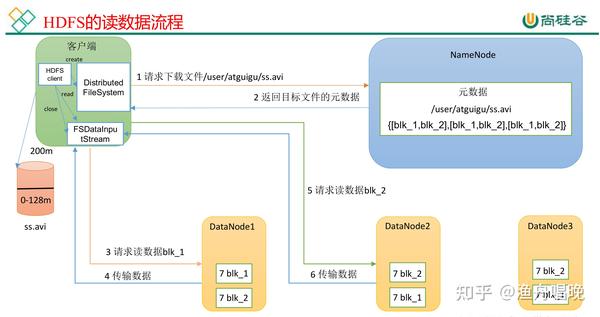
爬虫数据存储hdfs_HDFS数据
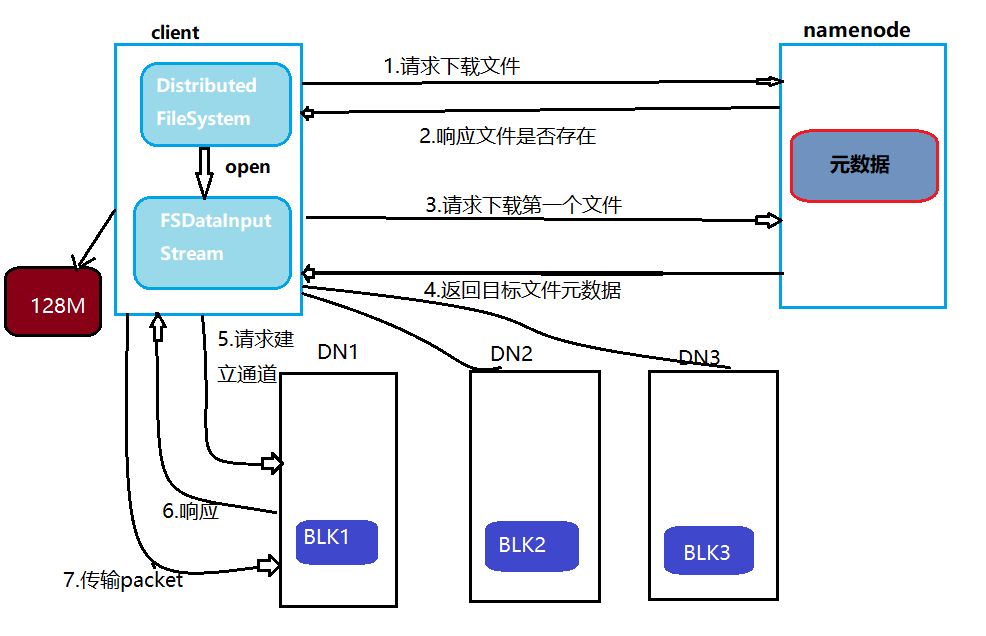
DFS挂载文件存储HDFS

包含图像文件的文件格式有哪些,下列文件扩展中,不是常用的图像文件格式的词条
格式化一词在计算机领域通常指的是对存储设备(如硬盘、USB驱动器等)进行的一种操作,该操作会删除设备上的所有数据,并设置一个全新、干净的文件系统。这个过程通常用于清理干扰、修复文件系统错误或准备将设备出售或赠与其他人。,原创疑问句标题,,格式化操作究竟意味着什么?,为何我们需要对存储设备执行格式化?,格式化后的数据能否恢复?,格式化过程中发生了什么技术变化?,如何安全地进行格式化以避免数据泄露?
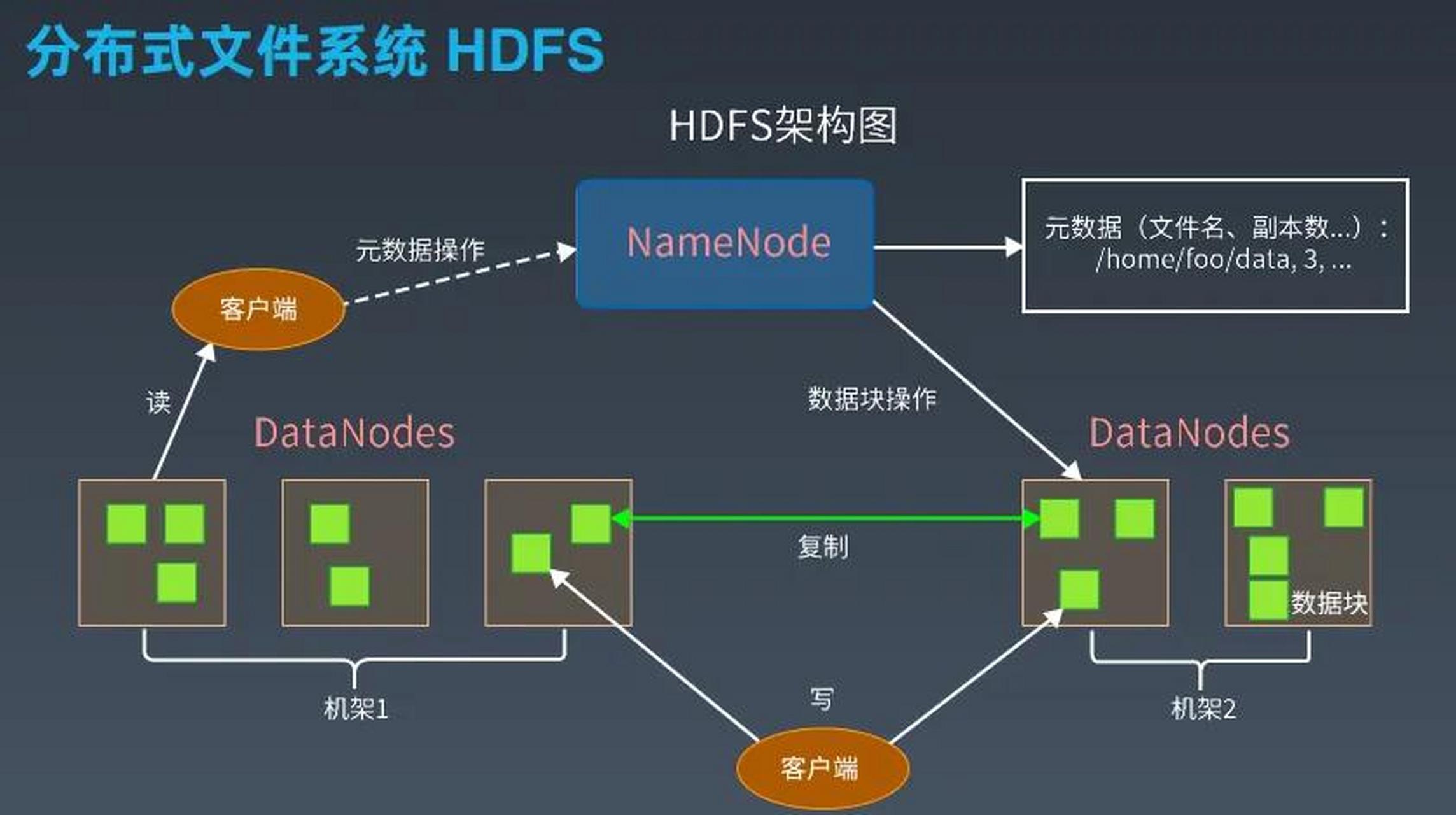
hdfs的存储机制

MySQL数据库文件格式揭秘,文件格式介绍中的奥秘是什么?
客户端向服务器存文件格式_文件格式介绍
mkv文件格式「mkv文件格式用什么播放器」







