上一篇
分布式文件存储系统hdfs
HDFS是分布式文件系统,将数据分块存储,采用主从架构,通过数据副本机制保障可靠性,具备高容错和可扩展性,适用于
分布式文件存储系统HDFS详解
HDFS
Hadoop Distributed File System(HDFS)是Apache Hadoop生态系统的核心组件,专为大规模数据存储和高吞吐量访问设计,其核心目标是通过分布式架构实现海量数据的可靠存储,并支持MapReduce等批处理框架的高效运行,HDFS采用主从架构,将元数据管理和数据存储分离,具备高容错性和可扩展性。
核心架构与组件
HDFS的架构由以下关键组件构成:
| 组件 | 功能描述 |
|---|---|
| NameNode | 主节点,负责管理文件系统的元数据(如目录结构、文件块位置)。 |
| DataNode | 从节点,负责存储实际的数据块并执行读写操作。 |
| Secondary NameNode | 辅助节点,用于定期合并NameNode的编辑日志,减轻主节点负载。 |
| Client | 用户接口,发起文件操作请求。 |
NameNode
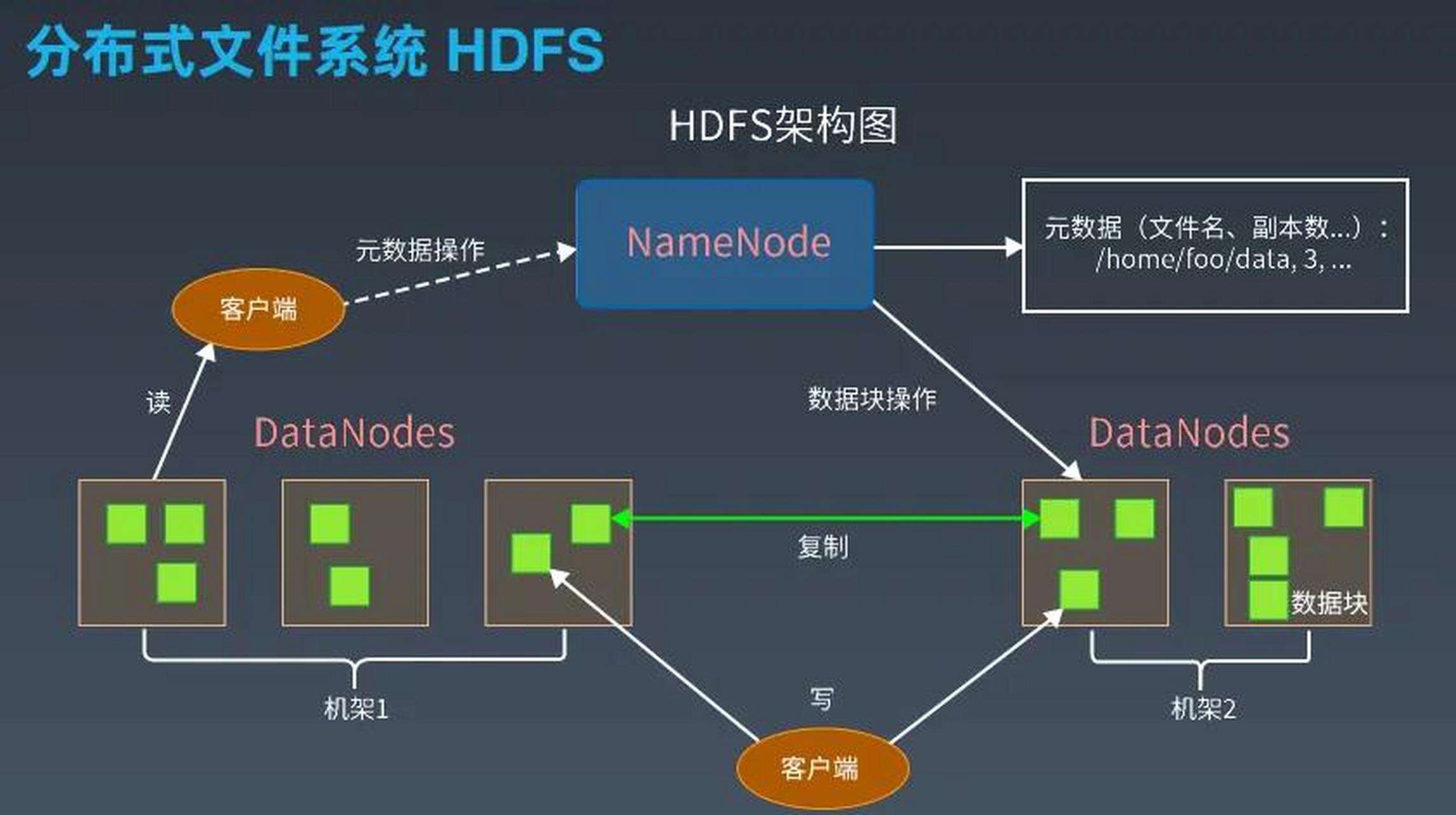
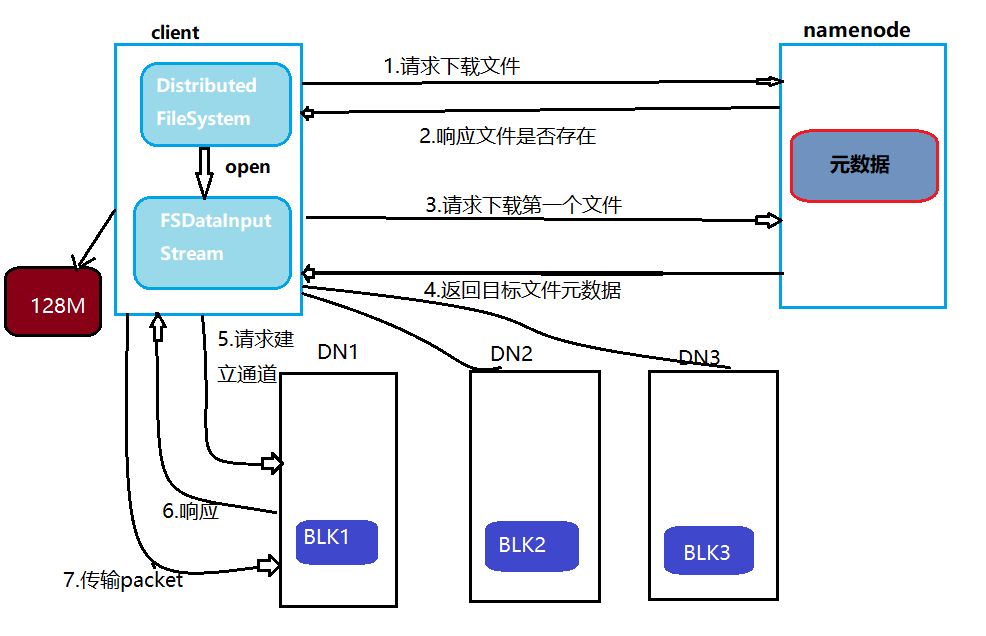
- 元数据管理:维护文件系统的树状目录结构、文件与数据块的映射关系。
- 数据块分配:决定数据块在DataNode上的存储位置。
- 单点故障风险:元数据存储在内存中,需通过Hadoop Federation或外部存储(如ZooKeeper)实现高可用。
DataNode
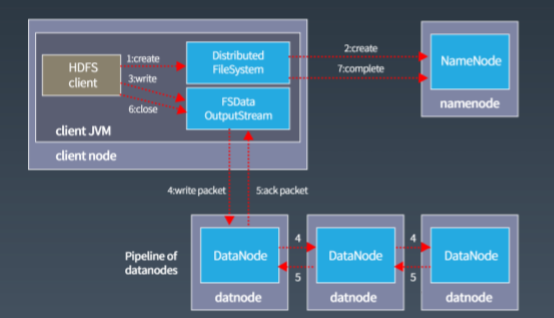
- 数据存储:将文件切分为固定大小的数据块(默认128MB),并在本地磁盘存储。
- 心跳机制:定期向NameNode发送心跳包,报告存储状态和数据块列表。
- 数据复制:根据NameNode指令执行数据块的复制(默认3副本)。
Secondary NameNode
- 日志合并:定期将NameNode的编辑日志(记录元数据变更)合并到FsImage中,减少主节点重启时的恢复时间。
- 非实时同步:不参与实时元数据管理,仅作为辅助节点。
数据存储机制
HDFS通过以下策略实现高效存储:

| 特性 | 说明 |
|---|---|
| 数据块存储 | 文件被拆分为固定大小的数据块,分布存储在不同DataNode上。 |
| 副本策略 | 每个数据块默认保存3个副本,分布在不同机架以实现容错。 |
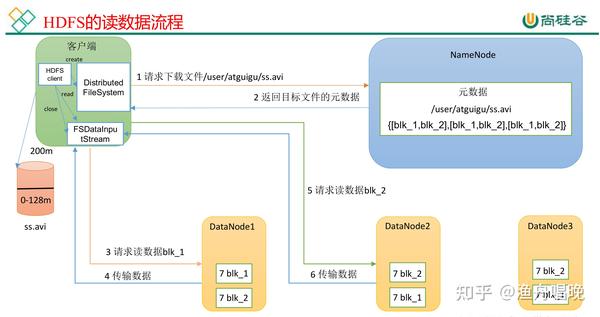
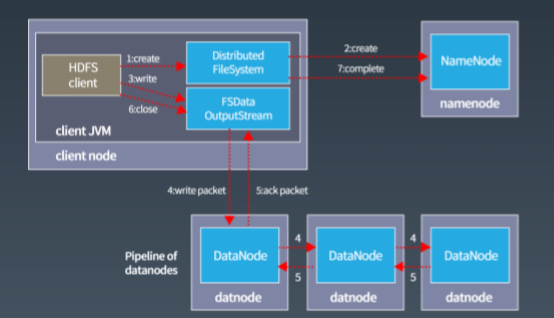
| 写入流程 | 客户端将数据分割为块→NameNode分配存储节点→DataNode执行实际写入。 |
| 读取流程 | 客户端从NameNode获取数据块位置→直接从DataNode读取数据。 |
数据块分配算法示例:
# 伪代码:NameNode选择DataNode的逻辑
def select_datanodes(block):
# 优先选择剩余空间充足的节点
candidates = [node for node in all_datanodes if node.free_space > block_size]
# 跨机架分布
racks = get_unique_racks(candidates)
return sorted_racks[:replication_factor]容错与恢复机制
HDFS通过以下机制保证数据可靠性:
| 机制 | 作用 |
|---|---|
| 数据块副本 | 任意两个副本失效时仍可恢复数据。 |
| 心跳检测 | NameNode通过心跳包监控DataNode状态,超时则标记节点失效。 |
| 数据完整性校验 | 使用Checksum验证数据块传输过程中的完整性。 |
| 元数据备份 | FsImage+EditLog组合实现元数据持久化。 |
HDFS与传统文件系统对比
| 特性 | HDFS | 传统文件系统(如NTFS/EXT4) |
|---|---|---|
| 设计目标 | 海量数据批处理 | 低延迟随机读写 |
| 数据块大小 | 128MB(可配置) | 4KB-64KB |
| 容错性 | 多副本+自动恢复 | RAID依赖硬件 |
| 扩展性 | 线性扩展至数千节点 | 受限于单节点性能 |
性能优化策略
HDFS的性能调优需关注以下维度:
| 优化方向 | 具体措施 |
|---|---|
| 数据本地性 | 将计算任务调度到存储数据的节点,减少网络传输。 |
| 副本策略调整 | 根据数据热度动态调整副本数量(如冷数据降为2副本)。 |
| 内存缓存 | 使用Tachyon/Alluxio等内存缓存系统加速频繁访问的小文件。 |
| 参数调优 | 调整dfs.replication(副本数)、dfs.blocksize(块大小)等核心参数。 |
典型应用场景
HDFS适用于以下场景:
- 大数据分析:支撑MapReduce、Spark等框架的海量数据处理。
- 日志归档:集中存储分布式系统的日志文件(如Web服务器日志)。
- 音视频存储:流媒体服务的原始视频素材长期归档。
- 科学计算:天文、基因测序等产生的TB/PB级数据集。
局限性与改进方向
尽管HDFS广泛应用,但仍存在一些限制:
- 低延迟场景不适:不适合毫秒级响应的实时应用。
- 单点故障风险:NameNode的单点问题需通过HA(高可用)架构解决。
- 小文件效率低:大量小文件会占用过多NameNode内存,需通过HFile等技术优化。
当前改进方向包括:
- 集成容器化存储(如Kubernetes CSI驱动)
- 支持纠删码(Erasure Coding)替代三副本存储
- 混合存储层级(热温冷数据分层)
FAQs
Q1:HDFS的NameNode出现故障会怎样?如何预防?
A1:NameNode故障会导致整个文件系统不可用,预防措施包括:
- 部署高可用集群(Active/Standby模式)
- 使用ZooKeeper进行主备切换协调
- 定期备份FsImage和EditLog
Q2:HDFS如何处理小文件存储问题?
A2:小文件会占用过多NameNode内存且降低存储效率,解决方案:
- 使用Hadoop Archive(HAR)合并小文件
- 采用SequenceFile格式压缩存储
- 引入异构存储(如对象