上一篇
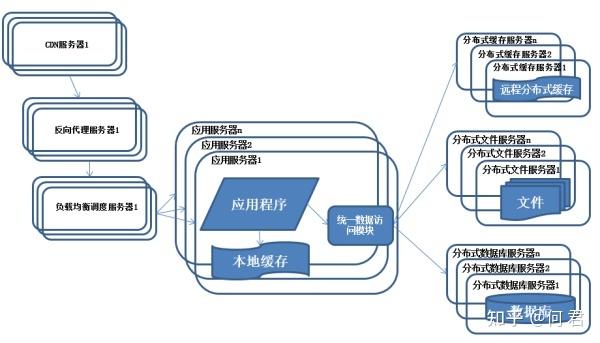
分布式文件存储系统框架
分布式文件存储系统采用主从架构,客户端通过元数据服务器定位数据,数据分块存储于多个数据节点,通过冗余备份和一致性哈希实现高可用,支持动态
分布式文件存储系统框架详解
核心架构与设计目标
分布式文件存储系统通过将数据分散存储在多个节点上,实现高可用性、可扩展性和高性能,其核心设计目标包括:
- 数据冗余与容错:通过数据副本或纠删码保证数据可靠性
- 水平扩展能力:支持动态添加/移除节点不影响服务
- 负载均衡:智能数据分布算法实现存储资源优化
- 元数据管理:高效处理文件目录结构和权限控制
- 性能优化:数据本地化访问与并行处理机制
主流框架对比分析
| 框架名称 | 架构类型 | 数据一致性模型 | 扩展性 | 典型应用场景 |
|---|---|---|---|---|
| HDFS | 主从架构 | 强一致性(写) | 横向扩展 | 大数据分析(Hadoop生态) |
| Ceph | 无中心架构 | 最终一致性 | 线性扩展 | 云存储/块存储 |
| GlusterFS | 对等架构 | 异步复制 | 弹性扩展 | 企业NAS/媒体存储 |
| MooseFS | 混合架构 | 可调一致性 | 中等扩展 | 中小规模文件共享 |
| MinIO | 对象存储架构 | 事件驱动一致性 | 容器化扩展 | 云原生应用/AI训练数据 |
核心组件解析
元数据服务层
- 功能:管理文件目录树、权限、索引
- 实现方式:
- HDFS采用单一NameNode(单点瓶颈)
- Ceph使用MON集群(Paxos协议)
- GlusterFS采用分布式哈希表
数据存储层
- 数据分片策略:
- 固定大小分块(HDFS默认128MB)
- 动态自适应分块(Ceph对象存储)
- RAID式条带化(GlusterFS)
- 数据分片策略:
客户端交互层
- 访问协议:
- POSIX兼容(Ceph/GlusterFS)
- HDFS自有API
- S3标准接口(MinIO)
- 访问协议:
关键技术实现
数据分布算法

- 哈希取模:简单但存在负载不均问题
- 一致性哈希:解决节点变动时的数据迁移
- 拓扑感知:考虑网络延迟的智能分布
副本管理机制
- HDFS:3副本策略(1个本机+2个远程)
- Ceph:CRUSH算法动态计算存储位置
- MinIO:Erasure Code纠删码(节省存储空间)
故障恢复流程
graph TD A[节点故障检测] --> B{副本缺失?} B -->|是| C[触发数据重建] B -->|否| D[维持正常服务] C --> E[选择新节点] E --> F[数据复制/重构] F --> G[校验完整性]
性能优化策略
- 数据本地化:优先读取本机数据副本
- 缓存机制:
- 客户端缓存(MinIO)
- 热点数据预加载(Ceph)
- 并行处理:
- 多线程并发读写
- MapReduce任务拆分
典型架构对比
| 特性 | HDFS | Ceph | MinIO |
|---|---|---|---|
| 部署复杂度 | 中等 | 较高 | 低 |
| 存储效率 | 300%(3副本) | 150%(EC) | 120%(EC) |
| 元数据性能 | 10k/秒文件操作 | 100k+/秒 | 依赖外部数据库 |
| 容器支持 | 差 | 优秀(Kubernetes) | 原生支持 |
| 对象存储兼容性 | 无 | RBAC模型 | S3完全兼容 |
选型建议矩阵
根据业务需求选择框架时应重点考虑:
数据规模:
- <10PB:MooseFS/GlusterFS
- 10PB-100PB:HDFS
-
100PB:Ceph
访问模式:
- 频繁小文件:Ceph/MinIO
- 大文件顺序读写:HDFS
- 混合型负载:GlusterFS
成本控制:
- 硬件成本:Ceph > HDFS > MinIO
- 运维成本:MinIO < GlusterFS < Ceph
FAQs
Q1:如何判断业务是否需要分布式文件系统?
A1:当出现以下情况时需要考虑:
- 单节点存储容量超过RAID阵列极限(gt;100TB)
- 年数据增长率超过50%
- 需要7×24小时不间断服务
- 存在多数据中心部署需求
- 并发访问量超过千级客户端
Q2:Ceph和MinIO能否混合部署?
A2:可以组合使用发挥各自优势:
- 底层存储使用Ceph提供块存储
- 上层通过MinIO网关暴露S3接口
- 利用Ceph的CRUSH算法进行数据分布
- 通过MinIO实现对象存储标准化访问
这种架构既保持了Ceph的存储能力,又获得了云原生接口