上一篇
分布式文件存储系统设计方案
分布式文件存储系统可采用多节点架构,数据分块存储并冗余备份,通过元数据管理文件位置,保障数据可靠与读写
分布式文件存储系统设计方案
系统架构设计
分布式文件存储系统的核心目标是实现海量数据的可靠存储、高效访问和弹性扩展,系统架构通常由以下模块组成:

| 模块 | 功能描述 |
|---|---|
| 客户端(Client) | 提供文件操作接口(上传、下载、删除、修改),支持文件分块与合并。 |
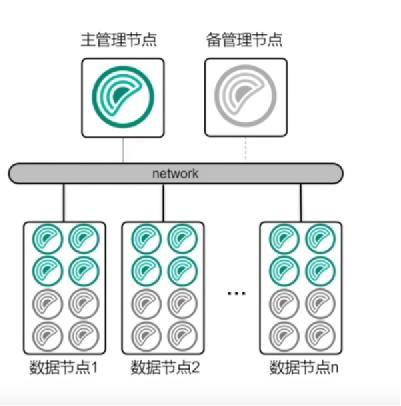
| 元数据服务(Metadata Service) | 管理文件元信息(目录结构、文件名、分块位置、权限等),协调数据节点分配。 |
| 存储节点(Storage Node) | 负责实际数据存储,支持数据分片、副本复制、纠删码等冗余策略。 |
| 监控与协调模块 | 监控系统状态(节点健康、负载、网络延迟),协调故障恢复与数据均衡。 |
核心设计要点
数据分片与冗余策略
- 数据分片:将大文件拆分为固定大小的数据块(如64MB/128MB),采用一致性哈希算法分配到不同存储节点,避免单点负载过高。
- 冗余策略:
- 副本机制:每个数据块保存多个副本(如3副本),分布在不同机架或数据中心,提升容灾能力。
- 纠删码(Erasure Coding):将数据块编码为多个冗余片段,节省存储空间(如HDFS的EC模式),但计算复杂度较高。
元数据管理
- 集中式元数据服务(如HDFS的NameNode):
- 优点:实现简单,元数据强一致。
- 缺点:单点故障风险,需通过主备切换或联邦架构解决。
- 分布式元数据服务(如Ceph的CRUSH算法):
- 通过分布式哈希表(DHT)管理元数据,支持动态扩展。
- 结合共识算法(如Raft)保证元数据一致性。
数据一致性模型
- 强一致性:写操作需等待所有副本确认(如分布式事务),适用于金融、订单等场景。
- 最终一致性:允许短暂数据不一致,通过后台同步保证最终一致(如DNS解析),适用于日志、音视频等场景。
- CAP定理权衡:在分区容忍(Partition Tolerance)前提下,需根据业务选择CP(一致性+分区容忍)或AP(可用性+分区容忍)。
扩展性与弹性设计
- 横向扩展:支持动态添加/移除存储节点,通过一致性哈希实现数据自动迁移。
- 数据均衡:当节点扩容或缩容时,触发数据再平衡(Rebalancing),可采用异步迁移或实时迁移策略。
- 异构存储支持:兼容SSD、HDD、对象存储等介质,根据数据冷热分层存储。
容错与恢复机制
- 节点故障检测:通过心跳机制(如每5秒检测一次)识别失效节点。
- 副本自动恢复:当副本数低于阈值时,自动在其他节点重建副本。
- 数据校验:定期进行数据完整性校验(如MD5/SHA-256),修复损坏数据。
关键技术实现
元数据服务高可用
- 主备模式:主节点处理写请求,备节点同步数据,故障时自动切换。
- 联邦架构:将元数据分片,多个NameNode共同管理(如HDFS HA模式)。
数据读写流程
- 写流程:
- 客户端将文件分块,请求元数据服务分配存储节点。
- 按冗余策略将数据块写入多个存储节点。
- 元数据服务记录块位置,返回写入成功状态。
- 读流程:
- 客户端查询元数据服务获取数据块位置。
- 直接从存储节点读取数据块,并行下载加速。
一致性协议
- Raft/Paxos:用于元数据服务的分布式一致性。
- Quorum NWR:写操作需W个副本确认,读操作需R个副本确认(如W=3, R=2)。
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 带宽优化 | 数据压缩(如Zstd/Snappy)、并行传输、就近读取(CDN式缓存)。 |
| 延迟优化 | 本地缓存(LRU/LFU策略)、预热热点数据、减少元数据服务跳转。 |
| 负载均衡 | 基于存储节点负载动态调整数据分布,避免热点节点。 |
安全性设计
- 权限控制:基于ACL(访问控制列表)或RBAC(角色权限)管理文件访问。
- 加密传输:使用TLS/SSL加密客户端与存储节点间的通信。
- 加密存储:对敏感数据采用AES-256加密,密钥由KMS(密钥管理系统)统一管理。
典型场景与案例对比
| 系统名称 | 架构特点 | 适用场景 | 缺点 |
|---|---|---|---|
| HDFS | 主从架构,块存储,强依赖NameNode | 大数据分析(如Hadoop) | 元数据单点故障,扩展性有限 |
| Ceph | 分布式元数据,CRUSH算法 | 云存储、混合云 | 配置复杂,性能依赖硬件 |
| GlusterFS | 对等节点,无中心元数据 | 中小规模集群,开发测试环境 | 元数据分散,一致性较低 |
监控与运维
- 监控指标:节点CPU/内存/磁盘利用率、网络延迟、请求成功率、数据复制延迟。
- 告警机制:基于Prometheus+Grafana实现实时监控,阈值触发自动告警(如邮件、短信)。
- 日志管理:集中收集存储节点与元数据服务日志,支持异常追踪与故障排查。
FAQs
问题1:如何确定数据块的副本数量?
解答:
副本数量需综合考虑以下因素:
- 容灾等级:跨机架或数据中心部署可提升容灾能力。
- 读写性能:更多副本可加速并行读取,但会增加写开销。
- 存储成本:副本越多,存储资源消耗越大。
建议对热数据(高频访问)设置高副本(如3副本),冷数据采用纠删码或低副本(如2副本)。
问题2:存储节点故障后如何恢复数据?
解答:
恢复流程如下:
- 故障检测:通过心跳超时标记节点失效。
- 副本重建:元数据服务从其他健康节点读取数据块,重新分配至新节点。
- 数据校验:校验重建后的数据块完整性(如比对哈希值)。
- 负载均衡:触发数据再平衡,避免