
上一篇
如何利用GREENPLUM文档快速解决数据库性能优化难题?
Greenplum文档全面介绍了其分布式数据库架构、功能特性及操作方法,涵盖安装部署、数据存储、并行查询优化、扩容运维等内容,提供详细指南与最佳实践,助力用户高效管理海量数据分析任务,适用于企业级大数据处理场景。
GREENPLUM文档:全面指南与核心资源解析
GREENPLUM作为一款开源的大规模并行处理(MPP)数据库,凭借其高性能、可扩展性和对复杂分析任务的支持,已成为企业级数据仓库和数据分析的热门选择,其官方文档是开发者、数据分析师及运维人员高效使用GREENPLUM的核心工具,以下从文档结构、核心内容、应用场景及学习路径等维度,系统解析GREENPLUM文档的价值与使用方法。
GREENPLUM文档的核心模块
入门指南
- 安装与部署:提供从环境准备到集群搭建的详细步骤,涵盖硬件配置、操作系统兼容性及分布式架构设计。
- 快速上手:通过示例演示数据加载、SQL查询及结果导出,帮助用户快速实现“Hello World”级操作。
架构与原理
- MPP架构解析:详解数据分片、并行计算及节点通信机制,适合需要优化查询性能的进阶用户。
- 存储引擎:介绍行存储、列存储及外部表(如与Hadoop集成)的适用场景与配置方法。
管理与运维
- 日常监控:内置工具(如gpcheck、gpstate)的使用说明,涵盖资源利用率、查询性能及故障检测。
- 备份与恢复:提供逻辑备份(gp_dump)与物理备份(文件系统级)的操作指南,确保数据高可用。
高级功能

- 机器学习库(MADlib):集成算法示例与调参建议,支持直接在数据库内完成数据挖掘。
- GPU加速:通过Greenplum与Apache MADlib的GPU插件提升复杂计算效率。
文档的典型应用场景
- 数据分析团队:通过文档中的SQL优化章节(如索引策略、分区表设计),缩短查询响应时间。
- 运维工程师:参考故障排查手册,快速定位节点宕机、磁盘空间不足等常见问题。
- 开发者集成:利用PL/Python、PL/Java扩展指南,实现自定义函数与外部系统对接。
高效学习路径建议
新手阶段
- 重点阅读《快速入门》和《基础SQL语法》,配合Docker镜像快速实验。
- 使用
gpadmin用户实践数据导入(如COPY命令)与简单聚合查询。
进阶提升
- 学习《查询优化器原理》和《执行计划解读》,通过EXPLAIN ANALYZE诊断慢查询。
- 实践分区表、资源队列(Resource Queue)配置,优化多租户环境下的资源分配。
专家级应用
- 研究《分布式事务管理》与《高并发锁机制》,设计低延迟高吞吐的OLAP方案。
- 参考《Greenplum与Kafka集成》,构建实时数据管道。
文档使用的最佳实践
- 精准检索:官方文档支持PDF/HTML多版本下载,建议本地部署全文搜索工具(如Elasticsearch)实现快速定位。
- 版本匹配:GREENPLUM 6.x与7.x的语法差异较大,需根据实际部署版本选择对应文档。
- 社区联动:结合官方论坛(Greenplum Discourse)的案例讨论,补充文档未覆盖的边界场景。
常见问题解答(FAQ)
Q1:文档是否提供中文版本?
- 官方文档以英文为主,但社区贡献了部分中文翻译,可通过GitHub仓库获取非官方译本。
Q2:如何获取最新更新?
- 订阅Greenplum官方博客或GitHub Release通知,及时获取版本发布与文档修订信息。
Q3:文档中的代码示例能否直接复用?
- 示例代码需根据实际环境调整参数(如内存配置、路径设置),建议先在测试集群验证。
权威引用与扩展资源
官方资源
- Greenplum官方文档库
- GitHub代码仓库
第三方指南
- Pivotal《Greenplum最佳实践白皮书》(PDF)
- VMware博客专栏《Greenplum性能调优实战》
认证培训
Greenplum官方认证课程(涵盖管理员与开发者双路径)
通过系统化学习文档并结合实际场景实践,用户可充分释放Greenplum在数据分析、实时处理与机器学习领域的潜力,为企业构建高效的数据驱动决策体系。
相关文章
GREENPLUM文档质量如何?这份全面解析值得一读!
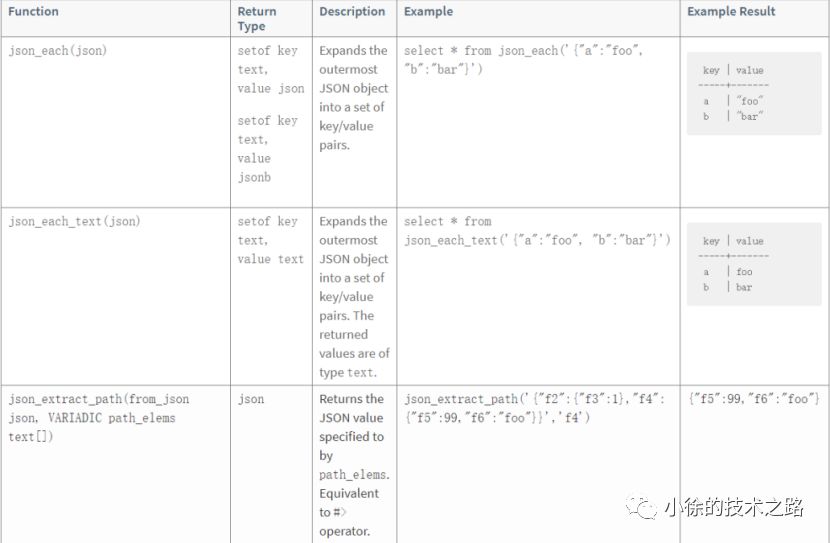
GREENPLUM文档瞬秒技巧你真的掌握了吗?
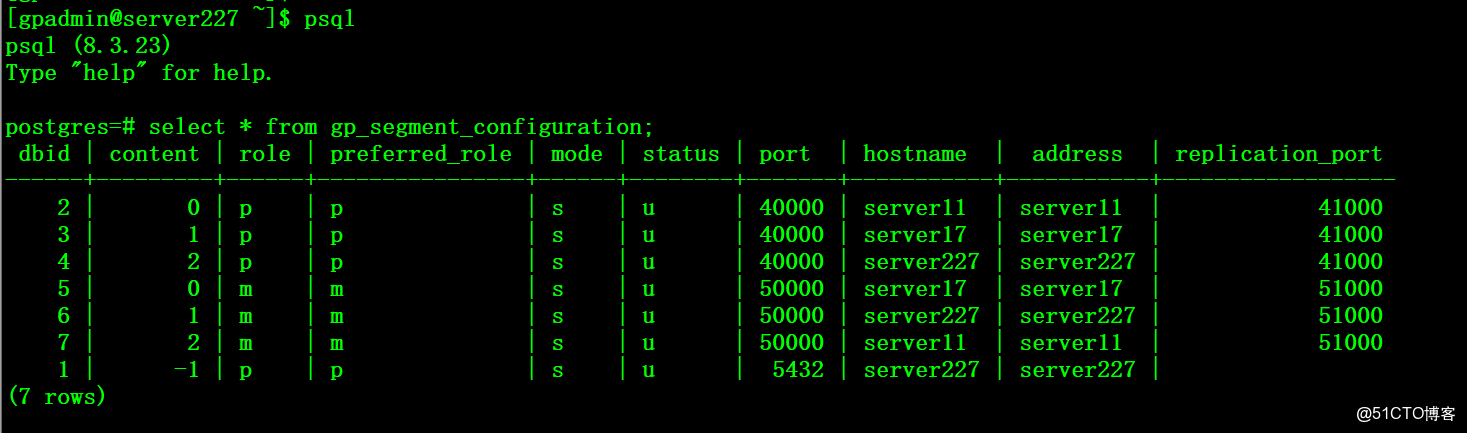
Greenplum数据库连接失败如何快速解决?
greencloudvps:10Gbps超大带宽年付国外VPS促销(greencloudvps优惠码)(greencloud vps)
如何高效购买GREENPLUM官方文档?

Greenplum数据库查询被锁如何高效解决?
如何利用d3jstree官方文档快速构建交互式树形结构?
Greenplum数据库视频如何助力企业高效处理海量数据?

Aggre 一词在英语中并不常见,它可能是一个拼写错误或特定领域的术语。如果这是一个关于法语单词 agréer(意为同意或承认)的文章,那么原创的疑问句标题可以是,,如何有效运用 agréer 来提升沟通效率?,如果 aggre 是某个专业术语或概念的缩写,请提供更多上下文,以便我能够提供一个更准确的标题。








