上一篇
hdfs的文件存储机制
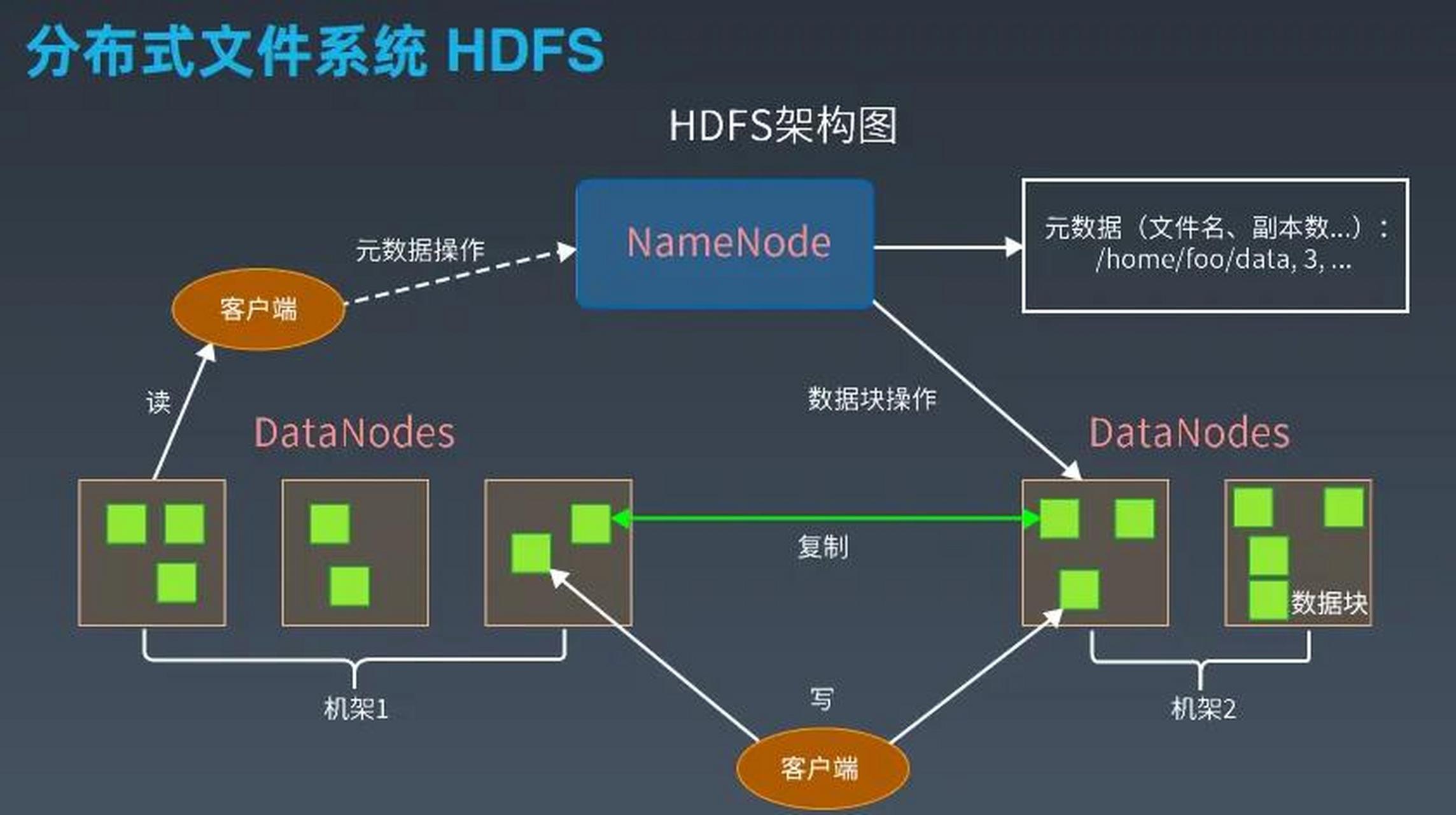
HDFS将文件分块存储,多副本冗余,分布式架构,元数据由NameNode集中
HDFS(Hadoop Distributed File System)是Hadoop生态系统的核心组件,专为大规模数据存储设计,其文件存储机制围绕高容错、高吞吐量和可扩展性展开,以下从存储架构、数据分块、元数据管理、副本策略等角度详细解析其工作机制。
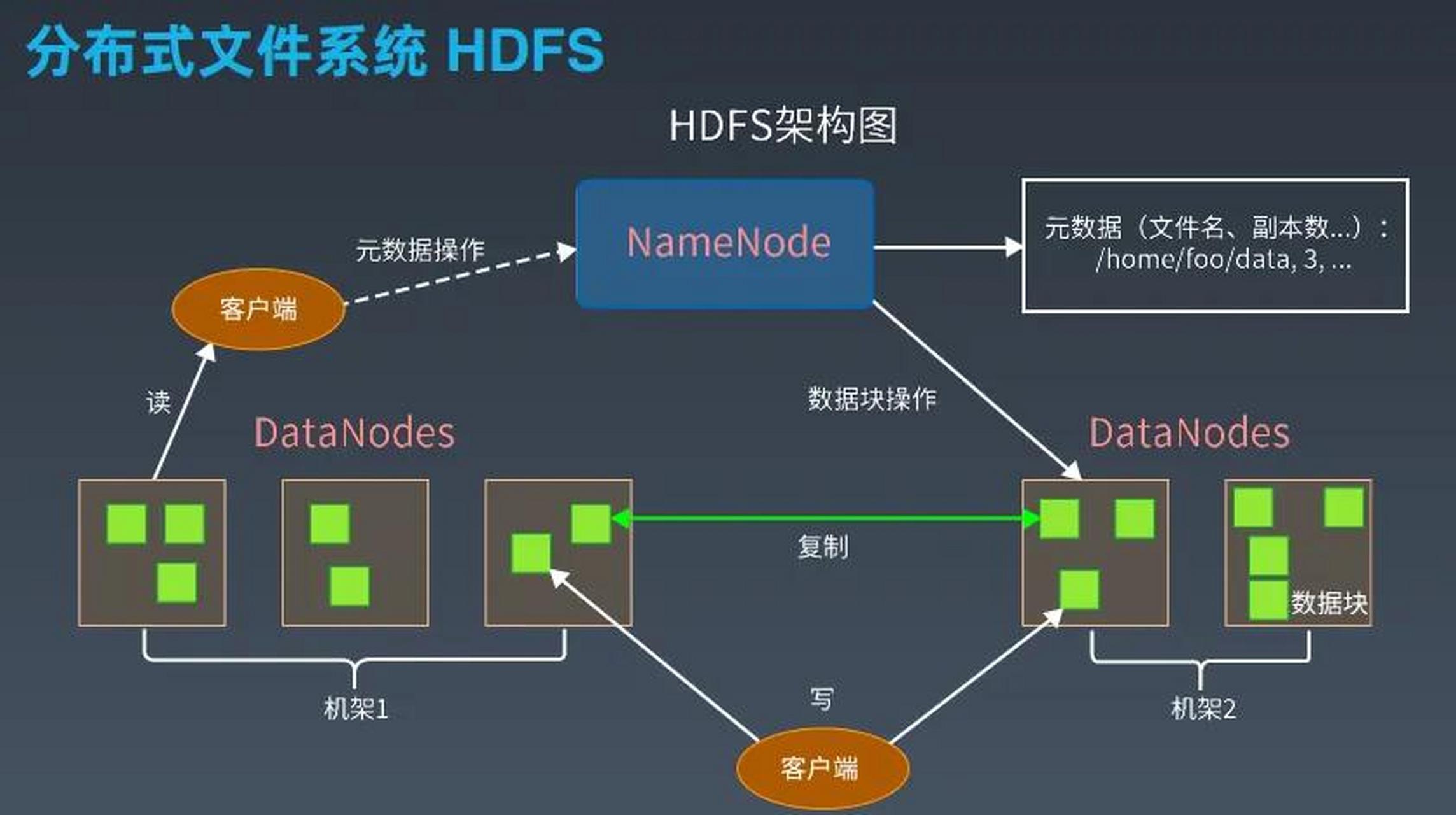
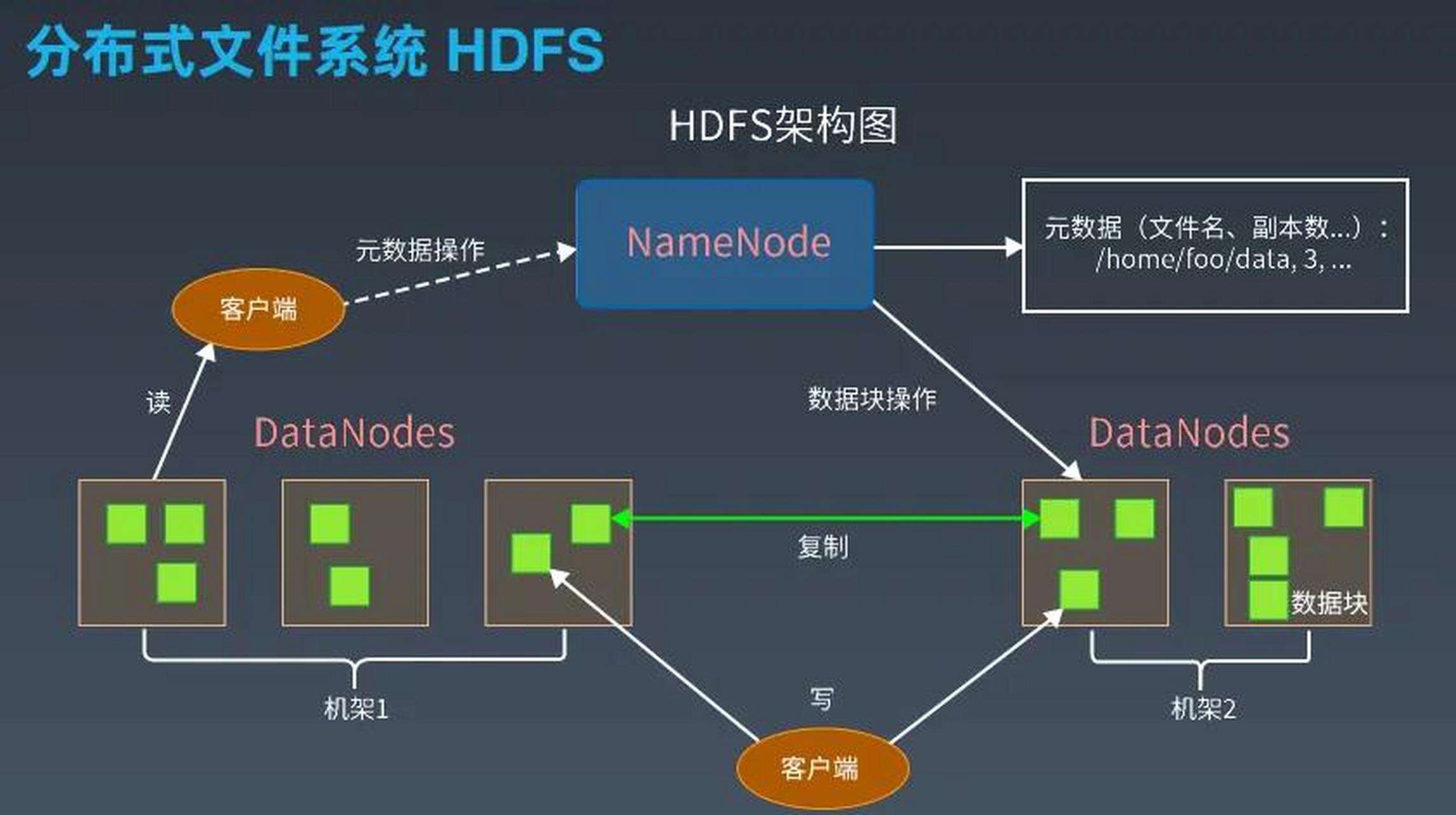
HDFS存储架构
HDFS采用主从架构(Master-Slave),核心角色包括:
- NameNode:负责管理文件系统的元数据(如文件目录结构、块位置信息),是集群的“大脑”。
- DataNode:负责存储实际的数据块,并定期向NameNode发送心跳和块报告。
- Secondary NameNode:辅助NameNode进行元数据检查点,不参与实时请求处理。
架构对比表
| 特性 | 传统文件系统(如NTFS) | HDFS |
|---|---|---|
| 核心设计目标 | 低延迟读写 | 高吞吐量、容错 |
| 数据分块大小 | 固定或动态(通常较小) | 固定(默认128MB) |
| 元数据管理 | 单节点集中式 | NameNode集中管理,支持扩展 |
| 副本机制 | RAID或软件层面冗余 | 多副本存储(默认3份) |
数据分块与存储
文件分块(Block Splitting)
- 文件被拆分为固定大小的块(默认128MB),即使最后一个块可能小于该值。
- 分块目的是支持并行处理和分布式存储,例如一个1GB文件会被分为8个块(128MB×8)。
块存储规则
- 每个块会被复制多份(默认3份),存储在不同DataNode上,以实现容错。
- 副本分布遵循机架感知(Rack Awareness)策略,优先在同一机架内存储副本,减少跨机架带宽消耗。
数据块分布示例
| 块编号 | 原始文件位置 | 副本1(DataNode) | 副本2(DataNode) | 副本3(DataNode) |
|---|---|---|---|---|
| Block1 | /user/data/file1 | NodeA(机架1) | NodeB(机架1) | NodeC(机架2) |
| Block2 | /user/data/file1 | NodeD(机架2) | NodeE(机架2) | NodeF(机架1) |
元数据管理
NameNode职责

- 维护文件系统的树状目录结构(如
/user/data/)。 - 记录每个块的ID、存储位置(DataNode列表)、副本状态。
- 不存储实际数据,仅依赖内存和磁盘持久化元数据(通过Edit Log和FsImage)。
- 维护文件系统的树状目录结构(如
元数据持久化
- FsImage:元数据的快照文件,定期保存到磁盘。
- Edit Log:记录元数据的增量变更(如文件创建、删除)。
- Secondary NameNode定期合并FsImage和Edit Log,生成新的FsImage,防止NameNode重启时数据丢失。
文件写入流程
- 客户端请求
用户发起文件上传请求,客户端将文件切分为多个块。
- NameNode分配存储位置
- NameNode根据负载和副本策略,为每个块分配DataNode列表(如
[NodeA, NodeB, NodeC])。
- NameNode根据负载和副本策略,为每个块分配DataNode列表(如
- 数据流水线传输
客户端按顺序将块数据推送到第一个DataNode(如NodeA),NodeA接收后转发给NodeB,NodeB再转发给NodeC,形成管道传输。
- ACK确认与元数据更新
所有副本存储完成后,DataNode向客户端返回成功消息,客户端通知NameNode更新元数据。
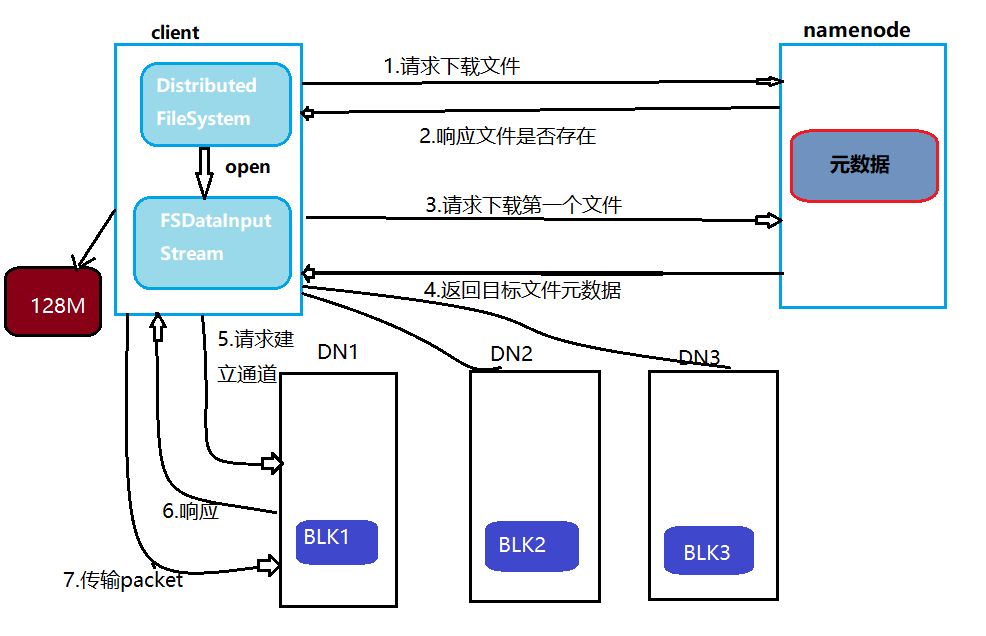
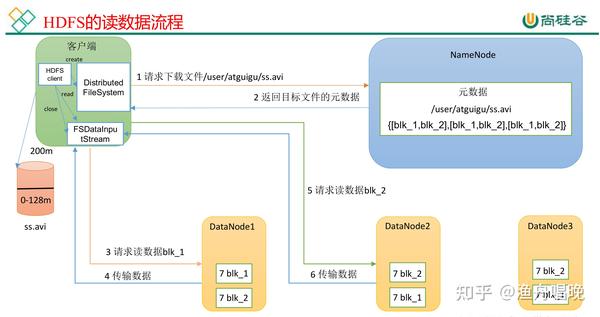
文件读取流程
- 客户端查询元数据
- 客户端向NameNode请求文件的块位置信息(如
Block1 -> [NodeA, NodeB, NodeC])。
- 客户端向NameNode请求文件的块位置信息(如
- 就近读取数据
客户端直接从最近的DataNode(如NodeA)读取块数据,减少网络延迟。
- 块合并与返回
客户端按顺序读取所有块并合并,最终返回完整文件内容。
副本策略与容错
副本因子(Replication Factor)
- 默认值为3,可通过配置调整(如关键数据设为更高值)。
- 副本分布需满足:同一机架内不超过2个副本,避免机架级故障导致数据丢失。
故障检测与恢复
- DataNode通过心跳机制定期向NameNode报告状态。
- NameNode发现副本缺失时,自动触发新副本创建(从现有副本复制)。
性能优化参数
| 参数 | 默认值 | 作用 |
|---|---|---|
dfs.blocksize | 128MB | 影响分块数量和MapReduce任务粒度 |
dfs.replication | 3 | 副本数量,平衡存储成本与容错性 |
dfs.namenode.rpc-port | 8020 | NameNode与客户端/DataNode的通信端口 |
常见问题(FAQs)
Q1:为什么HDFS默认块大小是128MB?
A:块大小直接影响MapReduce任务的效率,较大的块(如128MB)适合连续读取的大数据分析场景,减少任务启动次数;而小文件过多会导致NameNode内存压力增大,因此HDFS更适用于大文件存储。
Q2:如果某个DataNode故障,HDFS如何保证数据不丢失?
A:NameNode会通过心跳机制检测失效的DataNode,并查询该节点存储的块列表,若某块的副本数低于设定值(如3→2),NameNode会自动在其他健康节点上创建新副本,确保数据冗余度。