上一篇
hdfs对于小文件存储
HDFS存储小文件会导致元数据开销大,性能下降;建议合并小文件或使用其他存储
HDFS(Hadoop Distributed File System)作为大数据存储的基石,其设计初衷是优化大规模数据处理场景下的存储效率与吞吐量,当面对海量小文件(通常指小于128MB的文件)时,HDFS的存储与计算性能会显著下降,以下从原理、问题、解决方案、实践案例及未来方向五个维度展开分析。
HDFS设计原理与大文件优化
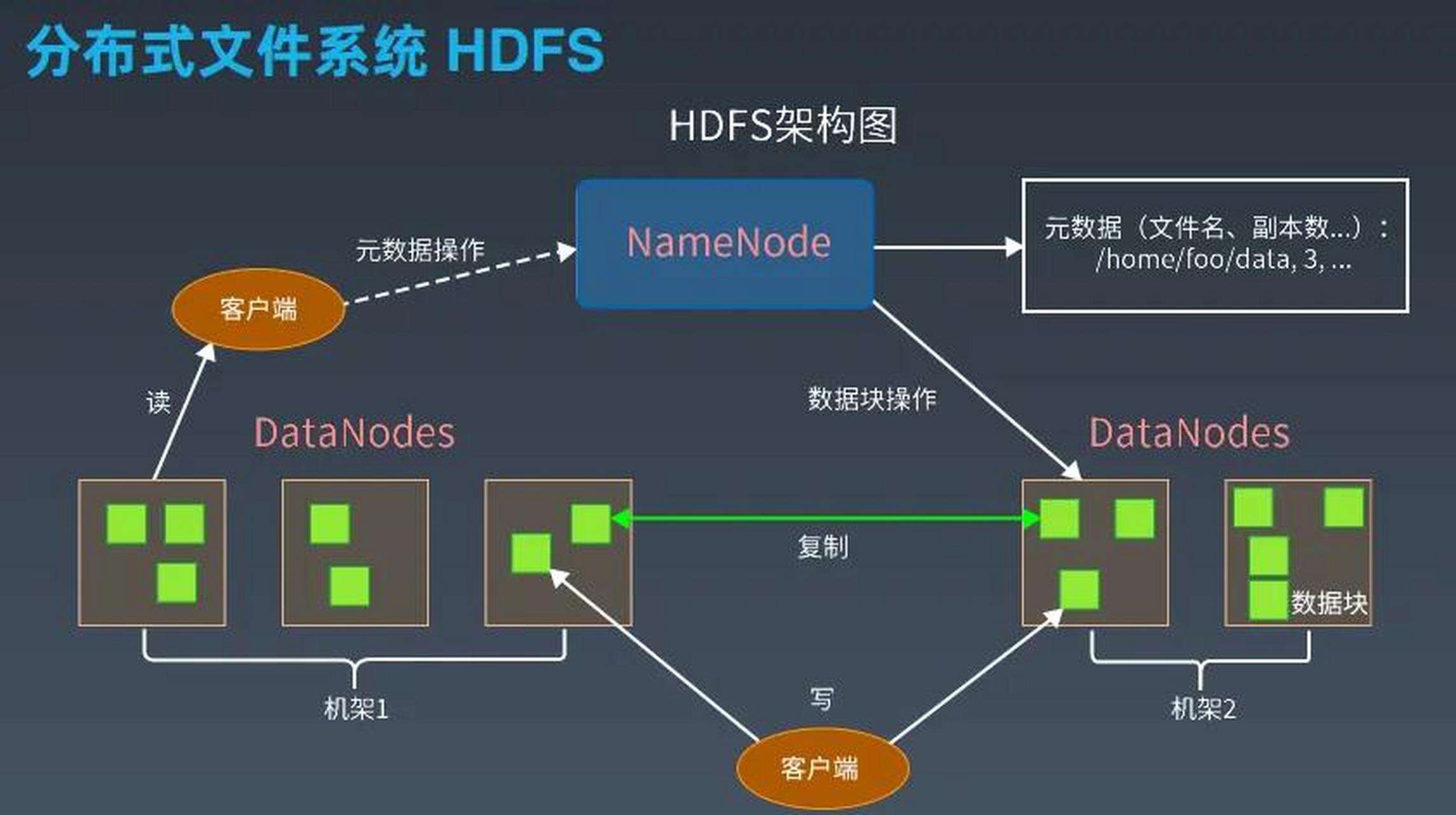
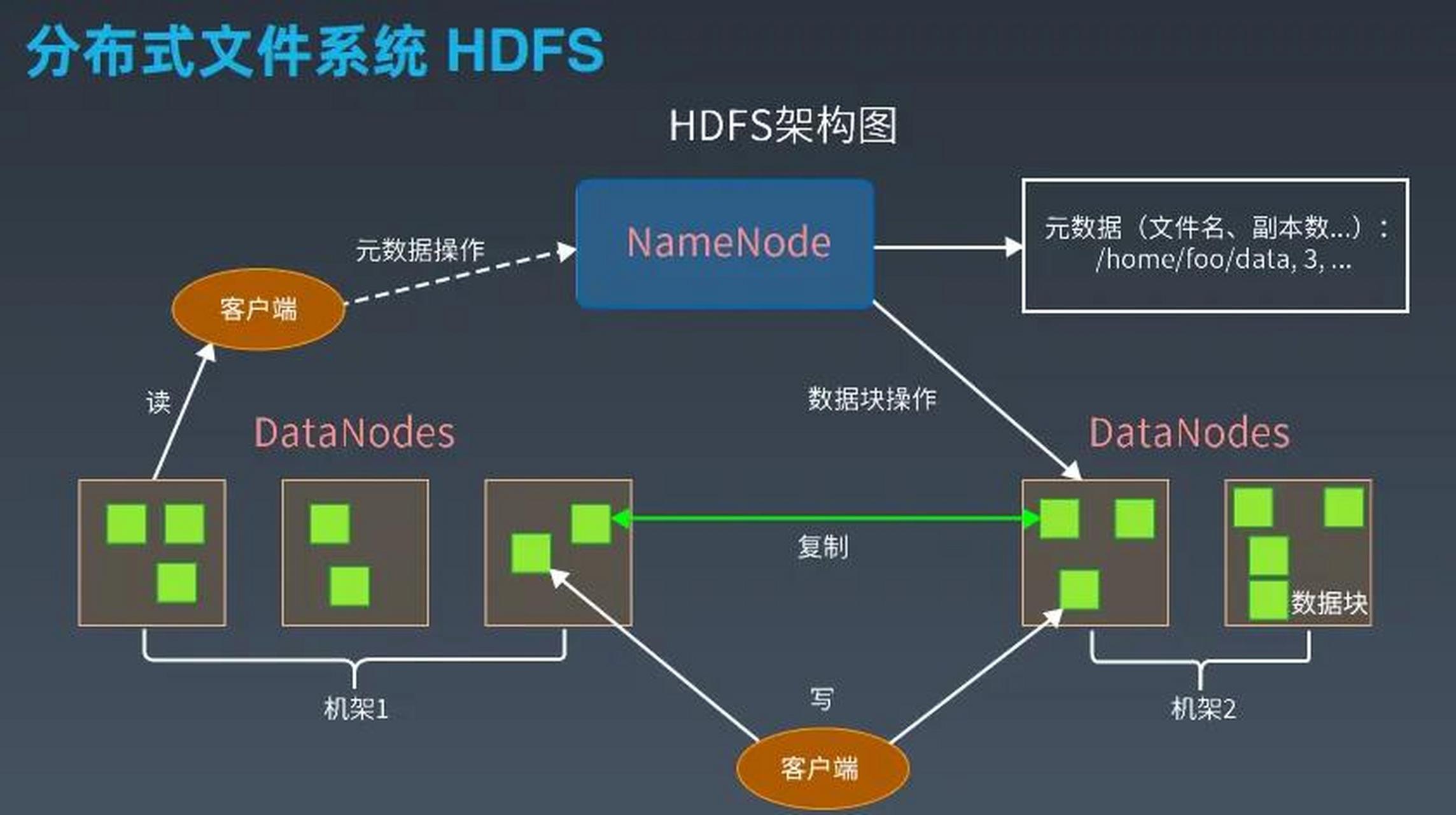
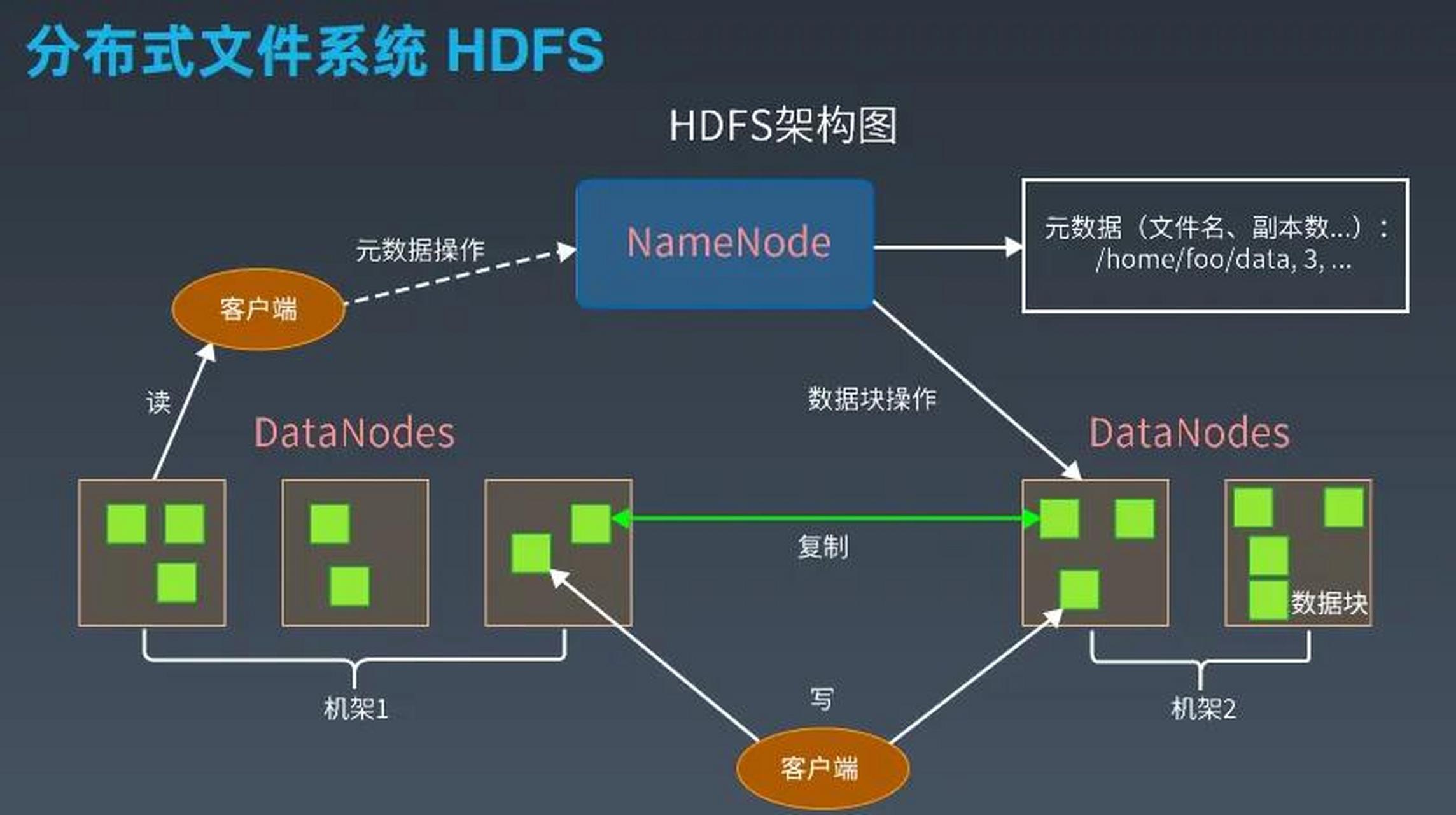
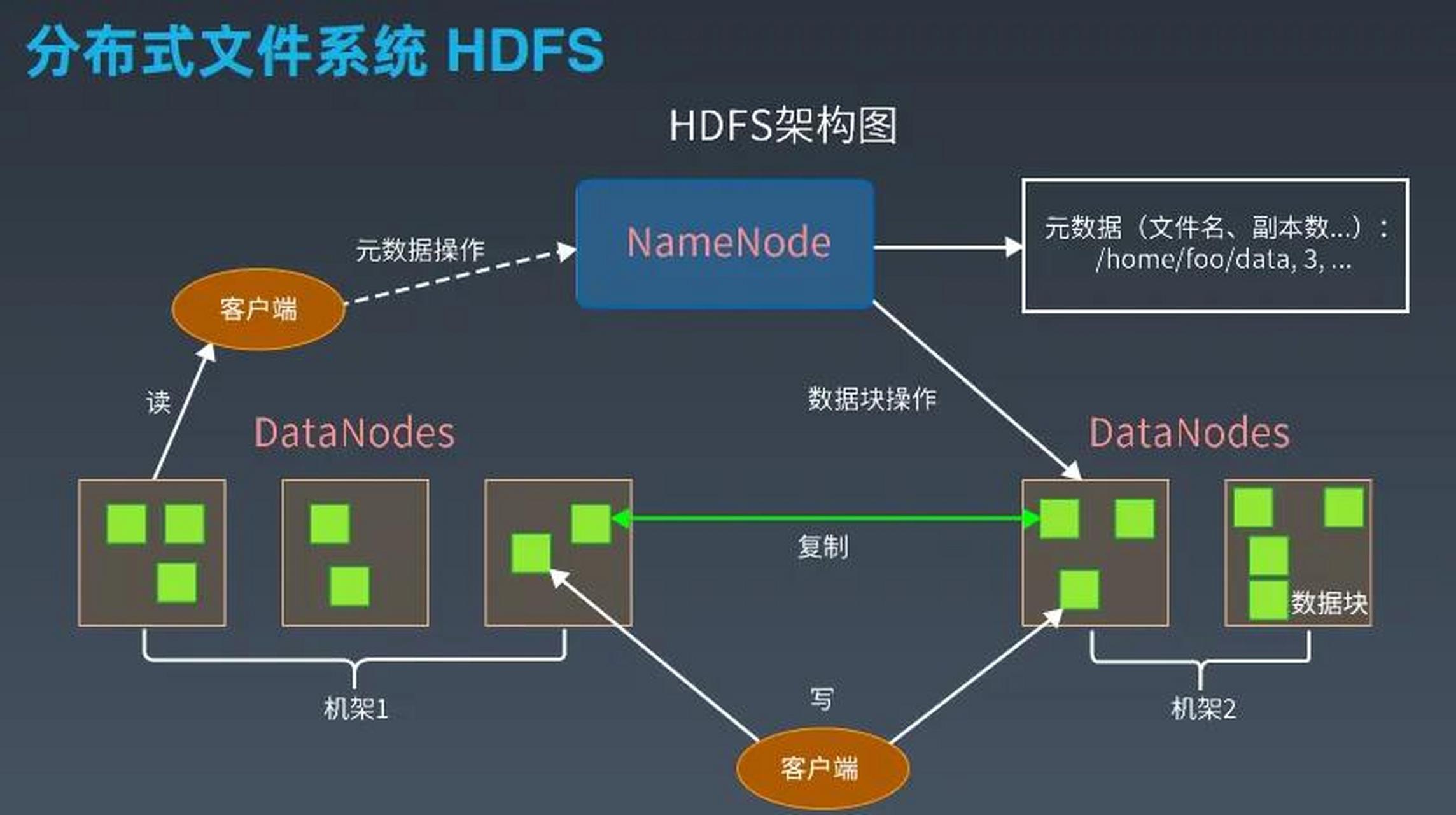
HDFS采用主从架构,核心组件包括NameNode(元数据管理)和DataNode(数据存储),其核心设计目标围绕大文件存储展开:
- 数据块存储:文件被拆分为固定大小(默认128MB)的数据块,分散存储在不同DataNode上,支持并行读写。
- 元数据集中管理:NameNode维护文件系统的元数据(如文件路径、所有权、块位置等),所有元数据加载到内存中以提升访问速度。
- 高容错性:通过数据块复制(默认3份)保证数据可靠性。
这种设计对大文件非常高效,例如一个1GB文件仅需10个数据块(128MB/块),元数据开销极低,但对于小文件(如1KB日志文件),每个文件独立存储会导致以下问题:
小文件存储的挑战
| 问题类型 | 具体表现 | 影响 |
|---|---|---|
| 元数据压力 | 每个小文件需独立占用NameNode内存(约150字节/文件),10亿文件需15GB内存 | NameNode内存耗尽,集群扩展性受限 |
| 数据块利用率低 | 1KB文件占用128MB数据块,实际存储效率仅0.78% | 浪费存储空间,增加网络传输开销 |
| 客户端性能瓶颈 | 大量小文件的并发访问导致NameNode元数据操作成为性能瓶颈 | 查询延迟升高,吞吐量下降 |
| MapReduce任务低效 | 每个小文件生成一个Map Task,任务启动与调度开销占比过高 | 计算资源浪费,任务执行时间延长 |
示例:存储100万个1KB文件,HDFS需占用约15GB内存(NameNode元数据),而实际数据量仅约1GB,存储效率不足0.1%。
解决方案分类与实践
文件合并(Application-Level Optimization)
原理:将多个小文件合并为大文件,减少元数据数量。
实现方式:
- 日志场景:使用
Hadoop CombineFileInputFormat将小文件合并为逻辑大文件,Map阶段按原始文件边界处理。 - 工具支持:Apache Sqoop的
--merge-file参数可将导入的小文件自动合并。 - 代码示例:
// 使用SequenceFile合并小文件 Path outputPath = new Path("/merged/data.seq"); Job job = Job.getInstance(conf); job.setInputFormatClass(CombineFileInputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(BytesWritable.class); job.setOutputFormatClass(SequenceFileOutputFormat.class); job.waitForCompletion(true);
优缺点:
| 优点 | 缺点 |
|————————|——————————|
| 显著降低元数据压力 | 合并后文件不可独立访问 |
| 提升MapReduce任务效率 | 需业务层解析合并后的文件格式 |
序列化文件格式(File Format Optimization)
适用格式:SequenceFile、Avro、Parquet
原理:以记录为单位存储数据,而非独立文件,将100万个小文件写入一个SequenceFile,元数据仅需记录单一文件的元信息。
对比:
| 格式 | 支持随机访问 | 压缩效率 | Schema演进 |
|—————|——————|————–|—————-|
| Text/Binary | 是 | 低 | 无 |
| SequenceFile | 否(需全量扫描) | 中 | 支持 |
| Avro | 否 | 高 | 支持 |
| Parquet | 否 | 高 | 支持 |
实践建议:
- 日志数据优先使用SequenceFile或Parquet。
- 结合压缩(如Snappy)减少存储空间。
Hadoop Archives(HAR,Storage-Level Optimization)
原理:将小文件打包为Hadoop Archive(类似ZIP),在NameNode层面视为单一文件,但内部保留文件目录结构。
操作步骤:
# 创建HAR档案 hadoop archive -archiveName myhar.har -p /input/smallfiles /output/myhar.har # 访问时按普通文件路径读取 hadoop fs -cat /output/myhar.har/smallfiles/file1.txt
优缺点:
| 优点 | 缺点 |
|————————|——————————|
| 减少NameNode元数据压力 | 不支持透明压缩 |
| 兼容现有API | 归档后文件不可独立修改 |
参数调优(Configuration Tuning)
| 参数 | 默认值 | 优化建议 | 作用 |
|---|---|---|---|
dfs.blocksize | 128MB | 增大至256MB(需权衡大文件效率) | 减少数据块数量 |
dfs.namenode.fs-limit | 10亿文件 | 根据集群内存调整(如100亿) | 提升NameNode可承载文件数 |
dfs.client.block.write.locations.timeout | 15秒 | 调至5秒 | 加速客户端寻址,缓解小文件并发写入压力 |
实际应用案例
案例1:互联网公司日志存储
- 场景:每日生成数百万1KB日志文件。
- 方案:
- 使用Flume将日志流式写入Kafka,批量导出为Parquet文件。
- 设置
mapreduce.input.fileinputformat.split.maxsize为500MB,确保单个Task处理足够数据。
- 效果:NameNode元数据减少90%,Map Task数量降低75%。
案例2:物联网设备数据存储
- 场景:传感器每秒上传1KB数据,日增86400个文件。
- 方案:
- 采用Apache Arrow格式将数据按小时合并。
- 开启HDFS透明压缩(
dfs.compress=zlib)。
- 效果:存储空间节省80%,查询延迟降低60%。
未来改进方向
Hadoop社区已提出多项优化提案:
- HDFS-14390:支持异构数据块大小(如小文件使用64MB块,大文件保持128MB)。
- NameNode元数据分级存储:冷热元数据分离,频繁访问的元数据驻留内存,冷数据持久化至磁盘。
- 融合对象存储:通过Interoperability with S3协议,将小文件直接存储至S3,仅索引信息保存在HDFS。
FAQs
Q1:如何判断文件是否属于“小文件”?
A:需结合业务场景与HDFS配置综合判断:
- 存储层标准:文件大小 <
dfs.blocksize(默认128MB)的5%(即6.4MB)时,存储效率显著下降。 - 计算层标准:单个Map Task处理文件总大小应大于HDFS块大小,否则任务启动开销占比过高,建议最小合并单元为64MB。
Q2:合并后的文件如何保证业务可读性?
A:通过以下方式平衡合并与可用性:
- 目录结构保留:使用HAR或SequenceFile时,保留原始文件路径作为记录键(如
key=/path/to/file.txt)。 - 元数据索引:构建二级索引表(如HBase),映射合并文件偏移量与原始文件名。
- 分层存储:将高频访问的小文件单独存储于对象存储(如S3),HDFS仅