
上一篇
hdfs的存储机制
HDFS将文件分块存储,多副本分布于不同节点,由NameNode管理元数据,DataNode
HDFS(Hadoop Distributed File System)作为大数据领域的核心存储引擎,其存储机制围绕高可靠性、高扩展性和高吞吐量设计,以下从架构设计、数据分块、副本策略、元数据管理等维度展开详细分析:
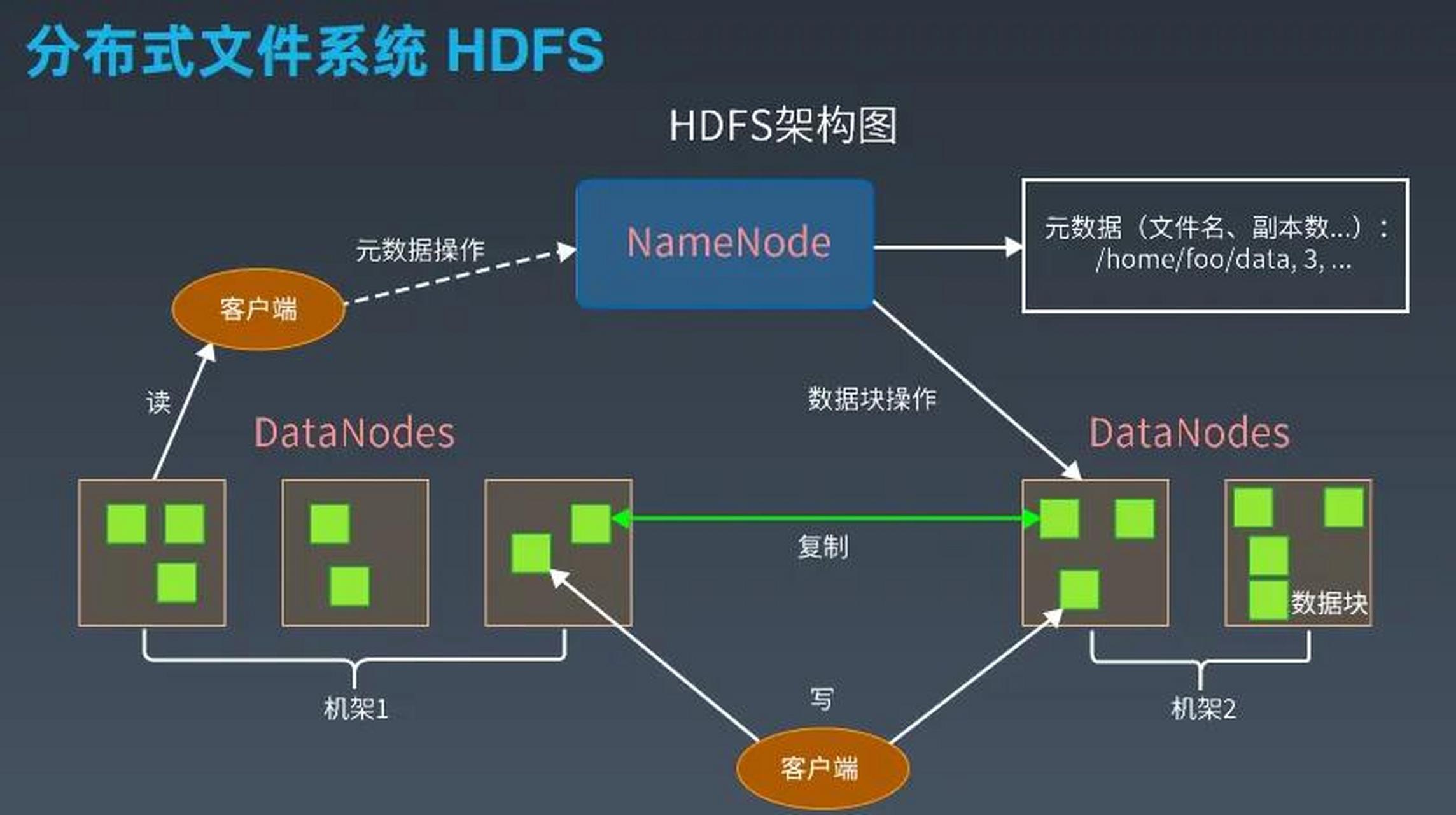
HDFS架构与存储角色划分
| 组件 | 功能定位 | 数据存储位置 |
|---|---|---|
| NameNode | 管理文件系统元数据(目录结构、文件块映射)、协调客户端访问 | 内存存储元数据(热备份机制) |
| DataNode | 存储实际数据块、执行数据读写操作、定期向NameNode发送心跳和块报告 | 本地磁盘(多副本分散存储) |
| SecondaryNameNode | 辅助NameNode进行元数据持久化(非必需组件,Hadoop 2.x后被HA方案替代) | 共享存储或独立存储 |
核心特点:
- 主从架构:NameNode为单点控制中心,DataNode负责物理存储
- 松耦合设计:DataNode故障不影响系统整体可用性
- 无共享存储:所有节点通过网络通信,避免单点存储瓶颈
数据分块存储机制
固定块大小划分
- 默认块大小:128MB(可配置)
- 设计原理:
- 平衡寻址效率与存储粒度(过大导致小文件占用过多元数据,过小增加管理开销)
- 适配MapReduce任务处理单元(单个块可被单个Task处理)
- 示例:500MB文件会被分割为4个128MB块+1个剩余块(实际按512字节对齐)
数据块存储策略
| 存储阶段 | 操作流程 |
|---|---|
| 写入阶段 | 客户端将文件切分为多个块 → NameNode分配块ID → 按策略选择DataNode存储节点 |
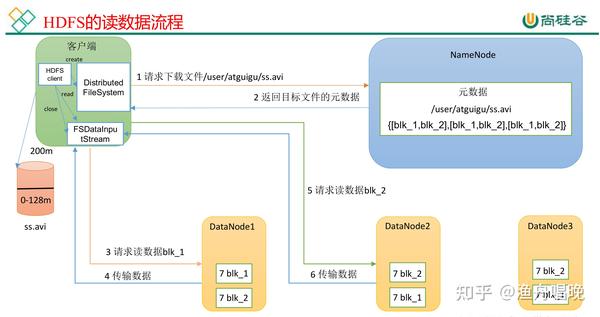
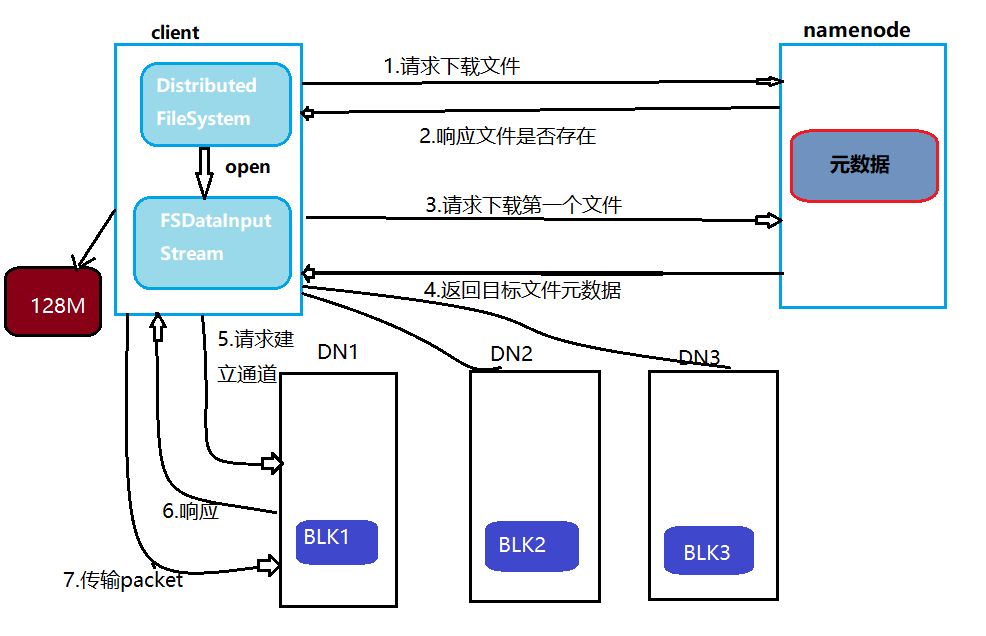
| 读取阶段 | 客户端请求文件 → NameNode返回块位置列表 → 直接从DataNode并行读取数据 |
优势:
- 支持跨机架并行读取(突破单节点带宽限制)
- 简化存储扩展(新增节点只需注册即可参与存储)
副本存储策略与容错机制
副本因子配置
- 默认值:3副本(可通过参数dfs.replication调整)
- 副本分布算法:
- 第一个副本:随机选择第一个DataNode
- 第二个副本:放置在不同机架的DataNode
- 第三个副本:与第二个副本同机架但不同节点
- 设计目标:
- 机架级容错(防止单机架断电/网络故障)
- 数据局部性优化(计算任务优先访问本机架数据)
副本维护机制
| 场景 | 处理方式 |
|---|---|
| DataNode故障 | NameNode检测心跳超时 → 触发副本重建(从其他副本复制) |
| 块校验失败 | 使用HDFS-RAID校验码恢复数据(需开启纠删码特性) |
| 集群扩容 | 自动均衡副本分布(通过Balancer工具) |
元数据管理与一致性保障
NameNode元数据存储
- :
- 文件目录树结构(inode表)
- 块到DataNode映射表(blocksMap)
- 文件权限、时间戳等属性
- 存储介质:
- 内存存储热数据(FsImage+EditLog)
- 磁盘持久化(SecondaryNameNode定期合并日志)
元数据操作流程
| 操作类型 | 流程步骤 |
|---|---|
| 文件创建 | NameNode分配inode → 生成块ID → 更新目录树 → 记录EditLog |
| 块报告接收 | DataNode定期发送块列表 → NameNode比对内存状态 → 更新blocksMap |
| 元数据持久化 | 周期性将内存元数据写入FsImage → EditLog追加操作日志 |
高可用改进:

- Hadoop 2.x+:采用Active/Standby双NameNode架构(JournalNode共享日志)
- HDFS HA快照:通过ZKFC实现快速故障切换
数据读写优化策略
写入流程优化
- 数据流水线传输:
- 客户端将块拆分为多个Packet
- 依次传输给流水线中的DataNode(减少客户端负载)
- ACK确认机制:
- 所有副本写入成功才返回确认
- 失败时重试下游节点
- 就近写入策略:
优先选择网络拓扑邻近的DataNode
读取优化
- 短路读取:
当客户端与DataNode位于同机架时,直接建立直连通道(绕过NameNode)
- 块预读缓存:
DataNode预读相邻块到本地缓存(提升顺序读取性能)
- 多流合并:
对小文件合并读取请求(减少寻址开销)
存储容量扩展机制
| 扩展方向 | 实现方式 |
|---|---|
| 纵向扩展 | 单节点增加磁盘(受限于JBOD架构) |
| 横向扩展 | 添加新DataNode → NameNode自动发现并纳入存储池 |
| 元数据扩展 | Federation模式(多NameNode分治命名空间) |
关键限制:
- NameNode内存限制(默认可管理百亿级文件)
- 块报告处理能力(大规模集群需优化心跳间隔)
与传统文件系统对比
| 特性 | HDFS | 传统分布式文件系统(如Ceph/GlusterFS) |
|---|---|---|
| 设计目标 | 高吞吐量批处理 | 通用型存储(兼顾高低延迟场景) |
| 元数据管理 | 集中式(单NameNode) | 分布式元数据(如Ceph的MON集群) |
| 副本策略 | 固定策略+机架感知 | 动态CRUSH算法 |
| 扩展瓶颈 | NameNode内存 | 元数据集群扩展性 |
| 典型应用场景 | ETL作业、大数据分析 | 混合型业务(文件/块存储) |
FAQs
Q1:HDFS为什么不适合存储大量小文件?
A1:每个文件对应一个Block和元数据条目,海量小文件会导致:
- NameNode内存被元数据占满(inode表膨胀)
- DataNode存储大量小块产生管理开销
- MapReduce任务数量激增(每个小文件生成独立Task)
解决方案:使用Hadoop Archive(HAR)合并小文件或采用对象存储接口。
Q2:DataNode故障后如何保证数据不丢失?
A2:通过三重机制保障:
- 副本机制:每个块有3份冗余存储
- 心跳检测:NameNode每3秒检测DataNode状态
- 自动恢复:故障节点的块由存活副本重新复制到其他节点
极端情况:若超过2/3副本所在节点同时故障
相关文章
hdfs的文件存储机制
爬虫数据存储hdfs_HDFS数据

hdfs存储机制是什么
DFS挂载文件存储HDFS
hdfs的存储文件格式

SVN服务器更新:取消FSFS文件系统 (svn服务器取消fsfs)

一个关于MySQL数据库中LIMIT和OFFSET用法的疑问句标题可以这样写,,MySQL查询优化,LIMIT 2、LIMIT 2,3与LIMIT 2 OFFSET 3有何区别?,清晰地表达了文章的核心主题,即探讨MySQL中LIMIT和OFFSET的不同用法及其对查询结果的影响。同时,它遵循了SEO原则,包含了关键词MySQL、LIMIT和OFFSET,有助于搜索引擎更好地理解和索引文章内容。此外,通过使用疑问句形式,标题还吸引了读者的注意力,激发了他们点击阅读的兴趣。

hdfs的文件存储方式








