
上一篇
hdfs的是基于流数据库
HDFS是分布式文件系统,基于磁盘存储,用于静态数据批量存储;流数据库面向实时数据流处理,二者定位不同,但可
HDFS(Hadoop Distributed File System)与流数据库的关系需要从技术定位、设计目标和应用场景三个维度展开分析,以下是对两者关系的深度解析:

核心概念对比
| 特性 | HDFS | 流数据库 |
|---|---|---|
| 数据模型 | 静态批量文件存储 | 动态持续数据流 |
| 核心目标 | 高吞吐量、大规模持久化存储 | 低延迟、实时数据处理 |
| 典型应用场景 | 离线批处理(如MapReduce) | 实时监控(如日志分析、金融交易) |
| 数据更新方式 | 写时一次写入,后续只读 | 持续追加/更新 |
| 延迟要求 | 分钟级延迟可接受 | 毫秒级延迟要求 |
| 系统架构 | 主从架构(NameNode+DataNodes) | 分布式流处理引擎(如Flink/Kafka) |
HDFS的非流式特性分析
存储设计限制
- 块存储机制:HDFS将数据拆分为固定大小(默认128MB)的块,这种设计适合批量处理但无法高效处理细粒度实时数据。
- 写优化策略:采用”一次写入、多次读取”模式,数据写入后不可修改,这与流数据库的持续更新需求冲突。
- 元数据瓶颈:NameNode集中管理文件元数据,频繁的小文件写入会引发性能问题。
数据处理延迟
- 批处理导向:HDFS与MapReduce生态深度耦合,典型作业周期以小时计,无法满足实时计算需求。
- 缺乏流式接口:没有内置的数据流API,需通过外部系统集成(如Kafka+Flume)实现数据采集。
适用场景边界
- 冷数据存储:适合存储PB级历史数据,如归档日志、数据仓库原始层。
- 离线分析基础:为Spark、Hive等批处理工具提供底层存储支持。
流数据库的技术特征
核心架构特点
- 时间窗口处理:支持滑动窗口(Sliding Window)、滚动窗口(Tumbling Window)等实时计算模式。
- 状态管理:维护有状态的流处理上下文(如Flink的Checkpoint机制)。
- 容错机制:通过水位线(Watermark)处理乱序数据,保证”恰好一次”语义。
典型技术栈
| 组件 | 功能示例 |
|---|---|
| Apache Kafka | 高吞吐量事件流传输 |
| Apache Flink | 分布式流处理引擎(支持SQL/DataStream) |
| Apache Storm | 实时流计算框架 |
| ksqlDB | 流数据SQL查询引擎 |
性能指标
- 端到端延迟:通常要求<1秒(如金融交易监控)
- 吞吐量:单节点可支持百万级事件/秒(如Kafka Broker)
- 状态规模:支持GB~TB级状态存储(RocksDB作为后端)
HDFS与流数据库的协同模式
虽然HDFS本身不具备流处理能力,但在混合架构中常作为关键组件存在:
| 角色 | 工作方式 |
|---|---|
| 数据源 | Kafka采集实时数据,通过Flume写入HDFS作为长期存储 |
| 计算结果存储 | Flink流处理结果批量写入HDFS,供下游BI工具分析 |
| 冷热数据分层 | 热数据(近期流数据)保留在Kafka/Redis,冷数据转存HDFS |
| 批流一体架构 | Lambda架构中HDFS负责批处理层,流数据库处理实时层,结果通过Merge操作整合 |
典型应用场景对比
HDFS适用场景
- 大规模数据归档:社交媒体日志、设备传感器历史数据
- 离线数据分析:用户画像计算、复杂事件处理(CEP)
- 数据湖建设:作为Golden Copy存储层,支持多计算引擎
流数据库适用场景
- 实时预警系统:网络攻击检测、工业设备故障预测
- 流式ETL:实时清洗转换物联网数据
- 在线机器学习:动态更新推荐模型(如淘宝实时推荐)
技术演进趋势
| 发展方向 | HDFS演进 | 流数据库演进 |
|---|---|---|
| 存储优化 | 支持EC纠删码、异构存储资源调度 | 增强本地状态存储能力(如Flink State backend) |
| 计算融合 | 强化HDFS-RAID实时分析能力 | 集成更多机器学习库(如Flink ML) |
| 统一架构 | 探索流批一体存储(如Hadoop 3.x) | 发展轻量化批处理模式(Micro-Batch) |
FAQs
Q1:HDFS能否直接替代流数据库?
A:不能,HDFS缺乏流式数据处理能力,其高延迟写入和中心化元数据管理不适用于实时场景,但可通过Kafka+Flume组合实现数据流入,再通过Impala等工具进行近实时查询。
Q2:如何构建批流一体数据处理系统?
A:典型方案包括:
- 数据层:Kafka作为实时数据通道,HDFS存储历史数据
- 计算层:Flink处理实时流,Spark处理HDFS中的批数据
- 服务层:通过Liquibase同步视图,对外提供统一API
- 存储优化:使用Iceberg/Hudi实现流批数据统一存储格式
相关文章
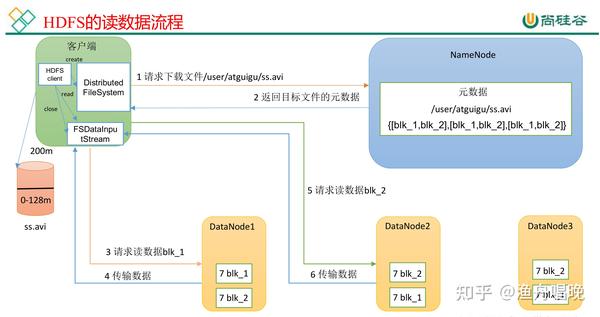
爬虫数据存储hdfs_HDFS数据
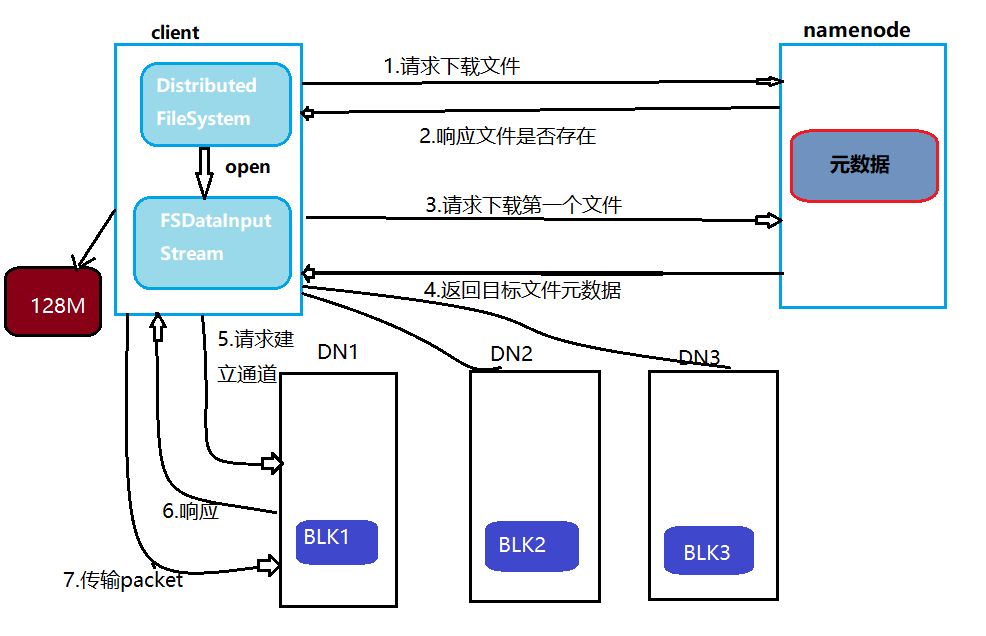
DFS挂载文件存储HDFS

离散傅里叶变换(DFT)是一种将时域信号转换为频域信号的数学工具。它通过傅里叶分析,把时间或空间域中的信号转换到频率域,从而揭示信号的频谱结构和变化规律。,基于DFT的原理和特性,我们可以提出以下疑问,,如何优化DFT算法以减少计算复杂度?,要学以致用,您可以思考如何运用快速傅里叶变换(FFT)算法来降低离散傅里叶变换(DFT)的计算复杂度。FFT通过递归分治策略将长序列分解为更短的序列,从而显著减少了乘法运算的次数。探索如何实现这一优化,并考虑其在实际信号处理中的应用。

一个关于MySQL数据库中LIMIT和OFFSET用法的疑问句标题可以这样写,,MySQL查询优化,LIMIT 2、LIMIT 2,3与LIMIT 2 OFFSET 3有何区别?,清晰地表达了文章的核心主题,即探讨MySQL中LIMIT和OFFSET的不同用法及其对查询结果的影响。同时,它遵循了SEO原则,包含了关键词MySQL、LIMIT和OFFSET,有助于搜索引擎更好地理解和索引文章内容。此外,通过使用疑问句形式,标题还吸引了读者的注意力,激发了他们点击阅读的兴趣。
python 远程 mysql数据库_使用Python远程连接HDFS的端口失败

SVN服务器更新:取消FSFS文件系统 (svn服务器取消fsfs)

本站全新文章标题mf8550cdn似乎是一个型号或代码,而并非一个明确的文章标题。为了生成一个疑问句标题,我需要更多关于文章内容的信息。不过,基于这个型号,我可以假设这是某种产品(可能是电子产品、软件版本、打印机型号等)的标识,并围绕它提出一个相关的疑问句标题。例如,,MF8550CDN 是什么?探索这款设备的创新功能!,请注意,由于缺乏具体的内容信息,这个标题是基于猜测创建的。如果您能提供更多关于文章内容的细节,我将能够给出一个更加精确和贴切的疑问句标题。

在设计疑问句标题时,通常需要根据文章内容来创造一个既吸引人又相关的问题。然而,由于本站全新信息hl 4050cdn不足以了解文章的内容,我无法提供一个精确的、与特定内容相关的疑问句标题。,不过,如果您需要一个通用的、基于这个信息片段的疑问句标题示例,我可以这样构造,,HL 4050CDN,这串神秘代码背后隐藏了什么秘密?,请注意,这个标题是基于假设的,旨在激发读者的好奇心,实际的文章内容可能与这个标题并不匹配。如果可以提供更多关于文章的信息,我可以帮助您创建一个更加准确和相关的疑问句标题。







