上一篇
hdfs存储技术
HDFS基于分布式主从架构,通过数据块复制实现可扩展与高容错,适配大数据
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统的核心组件之一,专为大规模数据存储和分布式计算场景设计,其核心目标是通过冗余存储和分布式架构实现高容错性、高吞吐量的数据访问,同时支持海量数据(PB级)的可靠存储,以下从技术原理、架构设计、存储机制等角度进行详细解析。

HDFS核心概念
| 特性 | 描述 |
|---|---|
| 分布式存储 | 数据分块存储在多个节点,避免单点故障。 |
| 高容错性 | 通过数据副本机制(默认3份)保证数据可靠性。 |
| 高吞吐量优先 | 优化大文件顺序读写,牺牲低延迟(适合批量处理而非实时交互)。 |
| 可扩展性 | 支持动态扩展集群规模,无需停机即可添加新节点。 |
| 廉价硬件兼容 | 设计目标为运行在普通商用服务器上,降低硬件成本。 |
HDFS架构组件
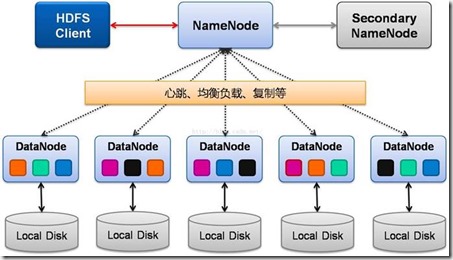
HDFS采用主从(Master-Slave)架构,核心组件包括:
NameNode(主节点)
- 功能:管理文件系统的元数据(如文件目录结构、块位置、权限等),协调客户端对数据的访问。
- 元数据存储:文件路径、文件属性、数据块与DataNode的映射关系。
- 单点问题:NameNode是潜在单点故障,可通过Secondary NameNode(辅助节点,用于元数据备份)或HDFS HA(高可用模式)缓解。
DataNode(数据节点)
- 功能:存储实际数据块,执行NameNode的指令(如创建/删除块、复制数据)。
- 数据存储:每个数据块默认存储3份副本,分布在不同机架(机架感知策略)以提升容灾能力。
- 心跳机制:定期向NameNode发送心跳包,报告存储状态和块列表。
Client(客户端)
- 交互流程:客户端先与NameNode通信获取元数据(如文件块位置),再直接与DataNode交互完成数据读写。
HDFS存储机制
数据分块(Block)
- 默认块大小:128MB(可配置),远大于普通文件系统,以减少寻址开销并适应大文件处理。
- 块编号:每个块有唯一ID,NameNode通过块ID追踪其存储位置。
副本存储策略
| 副本策略 | 规则 |
|---|---|
| 机架感知 | 优先将副本分布在不同机架,防止机架级故障导致数据丢失。 |
| 节点负载均衡 | 新副本优先存储在磁盘利用率低的节点。 |
| 副本数量调整 | 通过参数dfs.replication动态修改副本数(如冷数据可降为2份)。 |
元数据管理
- FsImage文件:NameNode启动时加载的元数据快照(包含文件树结构、块信息)。
- EditLog日志:记录元数据变更操作(如文件创建、删除),定期与FsImage合并。
- 内存优化:元数据全部加载到内存,因此NameNode内存限制了集群规模(通常支持数千节点)。
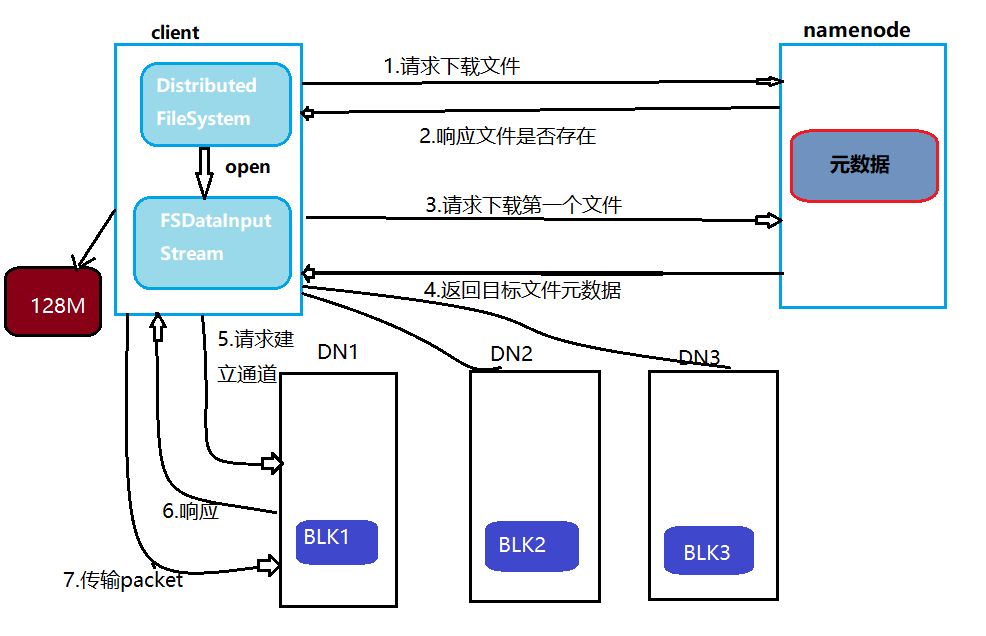
数据读写流程
写数据流程
- 客户端请求:向NameNode申请上传文件,获取文件分块信息及第一个块的存储节点列表。
- 数据分流:客户端按顺序将数据块并行写入多个DataNode(如块A→DataNode1、块A→DataNode2、块A→DataNode3)。
- ACK确认:所有副本写入成功后,DataNode通知客户端继续下一个块。
- 副本同步:后续块的存储节点由NameNode根据策略分配。
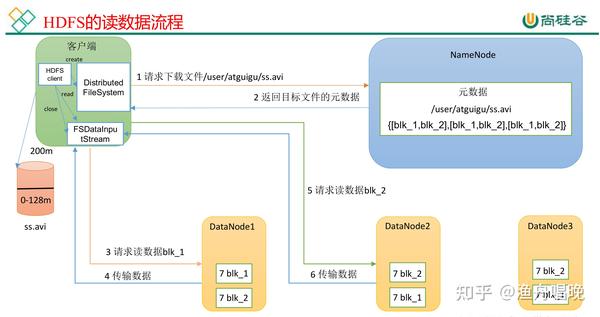
读数据流程
- 元数据查询:客户端向NameNode请求文件块位置信息。
- 就近读取:客户端直接从最近的DataNode读取数据块。
- 流式传输:支持多块并行读取,优化带宽利用率。
HDFS优化与扩展
性能优化
- 短回路访问:客户端缓存元数据,减少对NameNode的频繁请求。
- 数据本地性:计算任务优先访问本机或同机架数据,降低网络延迟。
- 压缩存储:支持Snappy、LZO等压缩算法减少存储空间。
高可用方案
- HDFS HA:通过Active/Standby双NameNode架构实现主节点故障自动切换。
- 联邦架构:将元数据分散到多个NameNode,突破单节点内存瓶颈。
与其他系统集成
- YARN资源调度:与Hadoop资源管理器协同,动态分配计算资源。
- 云存储适配:通过兼容S3协议或集成对象存储(如AWS S3)扩展存储容量。
HDFS vs 其他存储系统
| 对比项 | HDFS | 传统分布式文件系统(如Ceph) | 云存储(如AWS S3) |
|---|---|---|---|
| 设计目标 | 高吞吐量、大文件处理 | 通用场景(小文件+大文件) | 无限扩展、低延迟访问 |
| 硬件成本 | 廉价商用服务器 | 高性能硬件依赖 | 按需付费 |
| API兼容性 | HDFS自有API,支持Java/C++ | 多种协议(如POSIX、S3) | S3标准接口 |
| 一致性模型 | 最终一致性 | 强一致性(CP) | 强一致性(事件驱动) |
典型应用场景
- 大数据分析:作为MapReduce、Spark等计算框架的输入输出存储。
- 日志归档:海量非结构化数据(如服务器日志)的长期存储。
- 数据湖构建:支持Parquet、ORC等格式,为机器学习和BI提供底层存储。
- 冷数据备份:低频访问但需长期保留的数据(如历史交易记录)。
FAQs
Q1:HDFS是否适合存储小文件?
A:不适合,HDFS设计初衷是处理大文件,小文件会占用过多NameNode内存(每个文件需维护元数据),解决方案包括:
- 合并小文件为大文件(如使用SequenceFile或Hadoop Archives)。
- 使用对象存储(如S3)管理小文件,HDFS仅存储大文件。
Q2:如何恢复DataNode故障导致的数据丢失?
A:
- 副本重建:NameNode检测到DataNode失效后,触发其他节点复制丢失的副本。
- 手动干预:若副本数不足,管理员可通过
hdfs dfsck命令检查并强制修复。 - 预防措施:启用机架感知策略和多副本存储,避免单节点故障影响数据可用