上一篇
hdfs存储系统
HDFS采用分块存储与主从架构,通过数据冗余和高容错保障可靠性,支持海量
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统的核心组件之一,专为大规模数据存储和分布式计算场景设计,其设计理念基于谷歌GFS论文,通过分块存储、数据冗余和分布式管理实现高可靠性和可扩展性,以下从架构、核心组件、数据存储机制、容错策略等方面展开详细分析。

HDFS架构设计
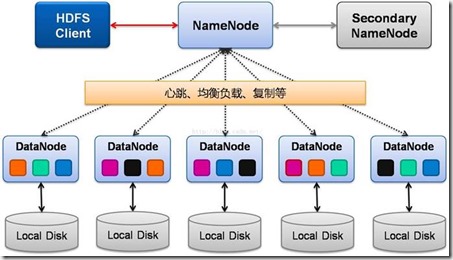
HDFS采用主从(Master-Slave)架构,包含以下关键角色:
| 组件 | 功能描述 |
|---|---|
| NameNode | 主节点,负责管理文件系统元数据(如目录结构、文件块位置)、客户端请求协调。 |
| DataNode | 从节点,负责存储实际数据块(Block),执行NameNode指令(如创建/删除块)。 |
| Secondary NameNode | 辅助节点,定期合并NameNode的编辑日志(Edit Log)和元数据快照(FsImage),减轻主节点负载。 |
| Client | 用户接口,发起文件读写请求,与NameNode交互获取元数据,再与DataNode交互完成数据传输。 |
架构特点
- 去中心化存储:数据分块后分布存储在多个DataNode上,避免单点存储瓶颈。
- 元数据集中管理:NameNode维护文件系统的树状结构和块映射表,内存中加载元数据以提高访问速度。
- 数据冗余保障:默认每个数据块存储3份副本(可配置),分布在不同机架或节点上,提升容错能力。
核心组件详解
NameNode
- 元数据存储:通过
FsImage(持久化快照)和Edit Log(操作日志)记录文件系统状态。 - 内存优化:仅将近期修改的元数据写入Edit Log,定期合并到FsImage以减少重启恢复时间。
- 单点风险:NameNode是HDFS的单点故障源,需通过主备切换或HA(高可用)架构解决。
DataNode
- 数据存储:每个DataNode本地存储数据块,定期向NameNode发送心跳(Heartbeat)和块报告(Block Report)。
- 数据读取:响应客户端请求,直接传输数据块;支持数据流式读取以减少延迟。
- 故障检测:若NameNode连续收到超时心跳,则标记对应DataNode为失效节点。
Secondary NameNode
- 作用澄清:并非NameNode的备份,而是用于合并元数据日志和快照,防止NameNode启动时因日志过大导致恢复缓慢。
- 工作流程:定期从NameNode拉取FsImage和Edit Log,合并后生成新的FsImage并清空Edit Log。
数据存储与读写机制
数据分块(Block)
- 默认块大小:128MB(可配置),远大于传统文件系统的块尺寸,适合大文件存储。
- 块分配策略:NameNode根据DataNode的存储容量、网络拓扑(如机架感知)分配块副本。
元数据管理
- 文件路径与块映射:例如文件
/data/file.txt会被拆分为多个块(Block ID),每个块存储在不同DataNode。 - 元数据结构:NameNode内存中维护
Inode对象(文件/目录的抽象),记录权限、所有者、块列表等信息。
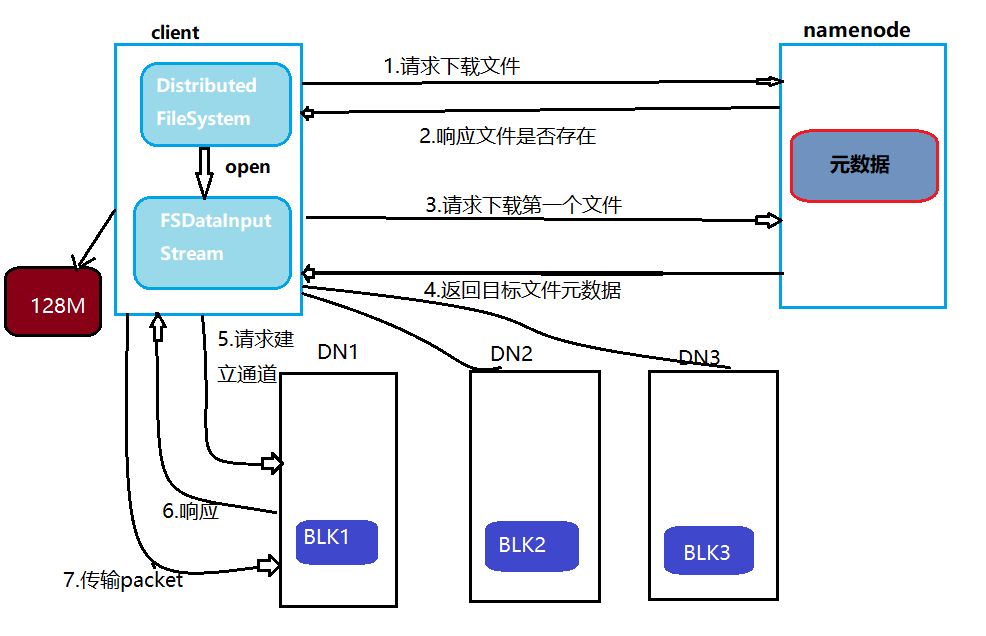
数据写入流程
- 客户端请求:向NameNode发起文件创建请求,获取可用DataNode列表。
- 管道传输:客户端按顺序将数据块写入第一个DataNode,该节点再转发至后续节点(链式复制)。
- 确认机制:所有副本写入成功后,客户端收到成功响应;若中途失败,需重新选择节点复制。
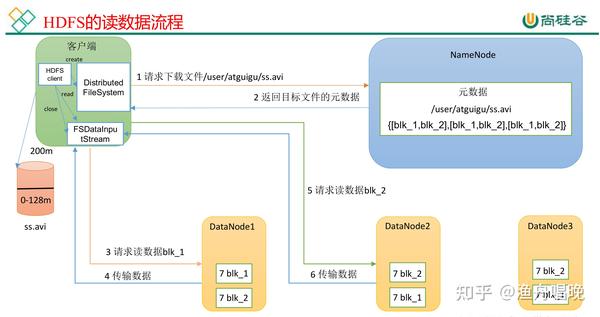
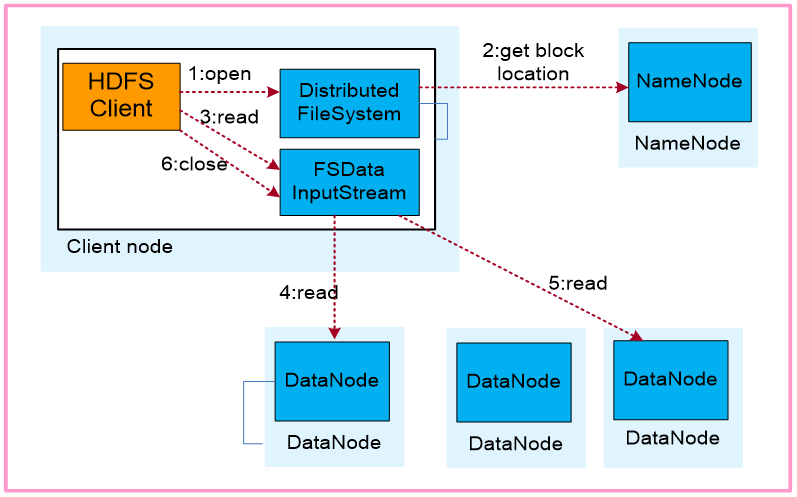
数据读取流程
- 元数据查询:客户端向NameNode请求文件块位置信息。
- 直接读取:客户端根据返回的DataNode地址,并行读取多个块(支持数据本地性优化)。
- 缓存策略:DataNode利用操作系统缓存加速读取,但HDFS本身不提供客户端缓存。
容错与恢复机制
数据冗余策略
- 副本因子(Replication Factor):默认3份,可通过配置文件调整(如冷数据设为2份)。
- 机架感知(Rack Awareness):副本分布优先跨机架,避免因机架故障导致数据丢失。
故障检测与恢复
- 心跳机制:DataNode每3秒发送心跳包,携带块状态信息;NameNode超时阈值默认10.5分钟。
- 块报告:DataNode定期上报存储的块列表,NameNode对比元数据发现丢失块后触发副本重建。
- 数据完整性:每个块附带校验和(Checksum),读取时验证数据是否损坏。
节点故障处理
- DataNode故障:NameNode标记失效节点,将其存储的块副本数降至阈值以下,触发新副本创建。
- NameNode故障:依赖HA集群或手动切换备用节点,需确保元数据同步(通过共享存储或JournalNode)。
HDFS优缺点分析
优势
| 场景 | 适配性 |
|---|---|
| 大规模数据存储 | 支持TB~PB级数据,横向扩展能力强 |
| 高吞吐量读写 | 优化大文件顺序访问,适合批处理任务 |
| 高容错性 | 数据副本和自动恢复机制降低硬件故障影响 |
| 低成本硬件适配 | 可运行在普通PC服务器上,无需高端存储设备 |
局限性
| 问题 | 原因与表现 |
|---|---|
| 低延迟需求不满足 | 元数据操作依赖NameNode,随机读写性能较差 |
| 小文件存储效率低 | 每个文件占用一个Block,元数据开销大 |
| 单NameNode性能瓶颈 | 元数据存储在内存中,集群规模受限于硬件资源 |
典型应用场景
- 大数据分析:作为Hive、Spark等计算框架的底层存储,支撑离线数据处理。
- 日志收集与归档:海量日志文件的集中存储(如电商用户行为日志)。
- 冷数据长期保存:配合廉价存储设备(如HDD)构建低成本归档系统。
- 分布式机器学习:为参数服务器或All-Reduce算法提供数据输入。
FAQs
问题1:HDFS与传统文件系统(如NTFS、EXT4)的核心区别是什么?
答:
HDFS专为分布式环境和大规模数据设计,与传统文件系统相比:
- 存储目标:HDFS面向GB~TB级大文件,传统文件系统优化小文件和随机读写。
- 元数据管理:HDFS的元数据集中管理(NameNode),传统文件系统依赖本地文件表。
- 容错机制:HDFS通过副本和心跳检测实现高可用,传统文件系统依赖RAID或备份软件。
- 扩展性:HDFS支持动态添加节点,传统文件系统受限于单台存储设备容量。
问题2:HDFS中Secondary NameNode的作用是否等同于备份节点?
答:
Secondary NameNode并非备份节点,其核心功能是合并元数据日志和快照,具体差异如下:
| 特性 | Secondary NameNode | Backup NameNode(HA模式) |
|————————|———————————–|——————————|
| 角色定位 | 元数据合并工具 | 实时同步的备用主节点 |
| 数据一致性 | 合并后的FsImage可能存在短暂延迟 | 与主节点保持实时同步 |
| 故障切换 | 无法自动接管NameNode职责 | 支持自动Failover |
| 部署复杂度 | 仅需配置定期合并任务 | 需ZooKeeper或JournalNode支持 |