上一篇
GPU存储器结构如何影响你的计算性能?
GPU存储器采用分层结构,包含全局内存、共享内存、常量内存、纹理内存和寄存器,全局内存容量大但延迟高,共享内存由线程块内共享,访问速度快;寄存器为线程私有,速度最快,不同存储层级通过数据复用和访问优化提升计算效率,适应并行计算需求。
在计算机图形处理和并行计算领域,GPU(图形处理器)的存储器结构直接决定了其性能天花板,本文通过技术参数对比、架构原理解析及实际应用场景,为读者构建完整的GPU存储体系认知框架。
GPU存储器的核心层级
现代GPU采用分层存储设计,通过7级存储结构实现速度与容量的平衡:
寄存器堆(Register File)
- 速度:0.5-1周期延迟
- 容量:每个CUDA核心256KB(NVIDIA Ampere架构)
- 特性:线程私有,零延迟访问,编译器自动分配
共享内存(Shared Memory)
- 速度:1-2周期延迟
- 容量:每SM 192KB(NVIDIA Ada Lovelace架构)
- 应用场景:线程块内数据交换,实现矩阵分块运算
L1缓存/纹理缓存
- 带宽:>1TB/s
- 智能预取:支持2D/3D空间局部性访问优化
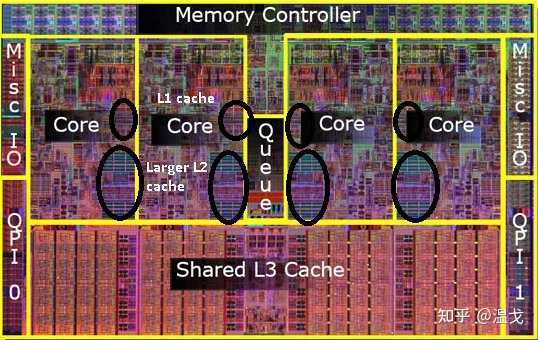
L2缓存

- 容量:96MB(AMD RDNA3)
- 统一架构:同时服务图形渲染与通用计算
显存系统的技术演进
| 技术类型 | 带宽峰值 | 能效比 | 典型应用 |
|---|---|---|---|
| GDDR6X | 936GB/s | 15pJ/bit | 游戏显卡 |
| HBM2e | 6TB/s | 10pJ/bit | 数据中心 |
| GDDR7 | 5TB/s | 12pJ/bit | 下一代PC |
HBM(高带宽存储器)采用3D堆叠技术,通过TSV硅通孔实现:
- 1024位总线宽度(GDDR6仅384位)
- 堆叠高度可达12层(HBM3标准)
- 5D封装集成于中介层(Interposer)
架构差异对比
NVIDIA与AMD设计哲学:
缓存策略
- NVIDIA:L2缓存作为全局交换中心
- AMD:Infinity Cache三级大缓存设计(RDNA3达128MB)
显存控制器
- NVIDIA:每32位总线独立控制器
- AMD:采用256位环形总线架构
数据压缩技术
- DLSS3:AI驱动的动态数据降载
- FidelityFX:基于算法的无损压缩
性能优化实践指南
访存模式优化
- 合并访问:将32字节对齐的连续访问合并为单次事务
- 银行冲突规避:共享内存采用32银行交错寻址
显存分配策略
cudaMallocManaged() // 统一内存管理 cudaMemAdviseSetPreferredLocation() // 数据预置
实时监控工具
- NVIDIA NSight:显存带宽利用率热力图
- ROCm Profiler:缓存命中率分析
前沿技术趋势
CXL互联协议
实现GPU与CPU内存池化,延迟降低至200ns级别光子存储器
实验性硅光链路达成5TB/s带宽(MIT 2025研究成果)存算一体架构
三星HBM-PIM集成AI运算单元于存储芯片内
参考文献
[1] NVIDIA A100 Tensor Core GPU架构白皮书
[2] AMD CDNA2架构技术简报
[3] JEDEC HBM3标准化文档JESD238A
[4] IEEE Spectrum《新一代存储器技术综述》2025.6