上一篇
GPU存储优化如何显著提升计算性能?
GPU存储优化通过内存分配策略调整、数据压缩及共享内存高效利用,结合张量核心加速和缓存预取技术,降低显存占用与访问延迟,混合精度训练和梯度检查点技术进一步平衡计算资源,提升深度学习模型训练效率,适用于大规模并行计算场景。
在深度学习、科学计算和图形渲染等领域,GPU存储优化已成为提升计算效率的核心技术,本文将从硬件架构、软件策略和算法创新三个维度,深入解析如何通过系统性优化释放GPU的极限性能。
GPU存储架构的底层逻辑
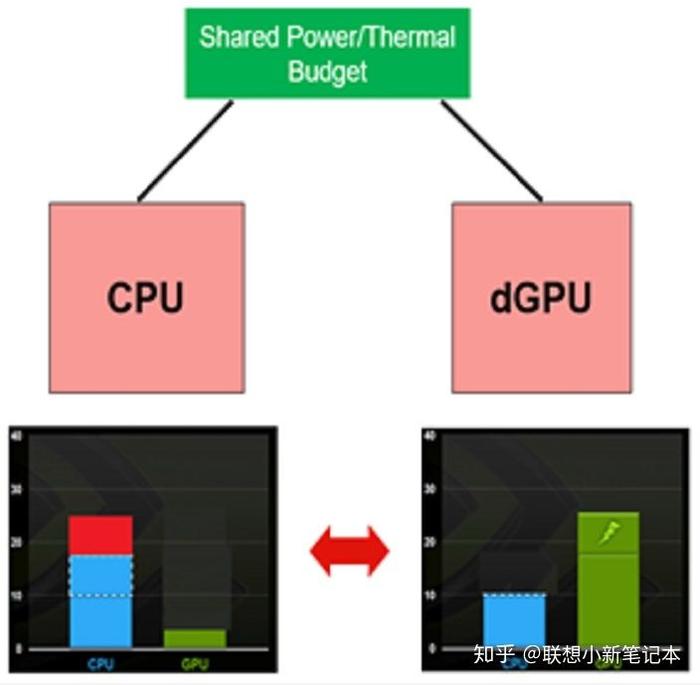
现代GPU采用分层存储设计(图1),其存储体系包含:
- 全局显存(Global Memory):容量8-80GB,带宽400-3000GB/s
- L2缓存:共享缓存,容量4-50MB
- L1缓存/共享内存:每SM单元64-128KB
- 寄存器文件:每线程255个寄存器
这种金字塔结构决定了数据复用率直接影响性能,NVIDIA Ampere架构引入的异步拷贝(Async Copy)技术,允许在计算同时执行数据搬运,将存储延迟隐藏效率提升40%。
六大关键优化技术
显存访问模式优化
- 合并访问:将32/128字节访问对齐到缓存行
- 银行冲突避免:共享内存采用32-way交错存储
// 错误示例:跨步访问导致带宽浪费 for(int i=0; i<1024; i+=32) data[i] = ...;
// 优化后:连续合并访问
for(int i=0; i<32; i++)
data[threadIdx.x + i*blockDim.x] = …;
混合精度计算
Tensor Core支持FP16/FP32混合精度训练,结合动态损失缩放(Dynamic Loss Scaling)技术:- 显存占用减少50%
- 计算吞吐提升3倍
- 精度损失<0.5%
零冗余优化器(ZeRO)
Microsoft开发的分布式训练技术:
| 优化阶段 | 显存节省 | 通信开销 |
|—|—|—-|
| ZeRO-1 | 4x | 低 |
| ZeRO-2 | 8x | 中 |
| ZeRO-3 | 线性扩展 | 高 |动态显存分配
CUDA 11引入的异步内存池:import torch torch.cuda.memory._set_allocator_settings('roundup_power2_divisions=4')可减少内存碎片,提升分配效率30%。
模型压缩技术
- 量化训练:INT8精度保持99%准确率
- 知识蒸馏:ResNet-50压缩至原模型1/4
- 稀疏训练:A100支持2:4结构化稀疏
流水线并行
Megatron-LM采用的Gpipe流水线:[GPU1] Forward → [GPU2] Forward → ... → [GPUn] Forward [GPUn] Backward ← ... ← [GPU2] Backward ← [GPU1] Backward吞吐量提升与流水线阶段数成正比。
性能监控工具链
- Nsight Systems:可视化显存使用时间线
- PyTorch Profiler:自动检测显存泄漏
- DCGM:集群级显存监控
- VLLM:大语言模型推理优化框架
前沿研究方向
- 存算一体架构:NVIDIA H100集成Transformer引擎
- 光子显存:Lightmatter研发的光学互连技术
- 持久化显存:CXL 3.0协议支持GPU直接访问SSD
典型优化案例
- Stable Diffusion推理优化:
通过TensorRT部署,显存占用从12GB降至4GB,推理速度提升5倍 - AlphaFold训练优化:
使用NVIDIA APEX优化器,128GPU集群训练时间从11天缩短至3天
实施路线图
- 基准测试:使用MLPerf评估当前性能
- 瓶颈分析:通过nsys定位存储热点
- 渐进优化:按计算→通信→存储顺序优化
- 持续调优:建立性能监控仪表盘
引用说明
[1] NVIDIA CUDA C++ Programming Guide
[2] Microsoft ZeRO: https://arxiv.org/abs/1910.02054
[3] PyTorch Memory Management Whitepaper
[4] MLPerf Training v3.0 Benchmark Results