上一篇
GPU服务器进程如何优化才能提升计算性能?
GPU服务器进程指在配备图形处理器的计算节点中运行的高性能并行任务,主要用于深度学习、科学模拟及大数据处理,其通过协调CPU与GPU资源分配,优化显存管理,加速矩阵运算等计算密集型操作,支持多任务并发处理,需配合CUDA等专用框架实现硬件级加速,显著提升复杂算法的执行效率。
GPU服务器进程:技术解析与应用指南
在人工智能、高性能计算(HPC)、图形渲染等领域,GPU服务器的核心价值体现在其强大的并行计算能力,而支撑这一能力的核心单元,正是GPU服务器进程,本文将深入探讨GPU进程的定义、工作原理、管理方法及行业应用,帮助用户全面理解这一技术。
什么是GPU服务器进程?
GPU服务器进程是指在GPU(图形处理器)上运行的程序实例,负责执行特定的计算任务,与传统CPU进程不同,GPU进程专注于并行计算,通过数千个计算核心同时处理数据,适用于需要高吞吐量的场景(如深度学习模型训练、科学模拟等)。
核心特点:
- 并行处理:单进程可调用多个GPU核心,加速复杂计算。
- 专用驱动:依赖NVIDIA CUDA、AMD ROCm等框架实现硬件交互。
- 资源隔离:通过进程级隔离避免任务冲突,提升稳定性。
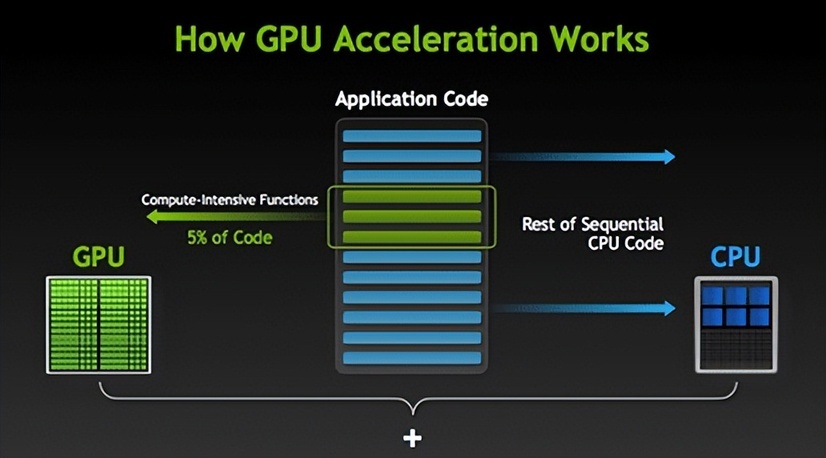
GPU服务器进程的工作原理
任务分配:
用户程序(如TensorFlow、PyTorch)通过API(CUDA/OpenCL)向GPU发送计算指令,GPU驱动将任务分解为多个线程,由SM(流式多处理器)并行执行。
内存管理:
GPU进程需在显存(VRAM)中分配数据,通过PCIe总线与CPU内存交互,显存不足时,进程可能因资源竞争而崩溃。计算执行:
GPU核心(如CUDA Core)执行矩阵运算、图像处理等任务,结果返回至CPU或直接输出。异常监控:
进程状态由工具(如nvidia-smi)实时监控,可跟踪显存占用、温度、计算利用率等指标。
GPU进程的典型应用场景
深度学习训练
- 单卡或多卡并行训练模型(如ResNet、GPT)。
- 典型案例:AI公司使用8*A100 GPU集群,将训练周期从30天缩短至3天。
科学计算
- 分子动力学模拟、气候建模等需要浮点运算的领域。
- 案例:NASA利用GPU进程加速火星探测数据分析。
图形渲染与实时推理
- 影视特效渲染(如使用NVIDIA OptiX)。
- 实时视频分析(安防、自动驾驶)。
如何高效管理GPU进程?
工具与框架
- NVIDIA-SMI:命令行工具,支持进程监控、显存分配。
- Kubernetes GPU插件:实现容器化GPU资源调度(如阿里云ACK)。
- 容器化技术:Docker结合NVIDIA Container Toolkit,隔离多任务环境。
关键监控指标
| 指标 | 说明 | 健康阈值 |
|———————|——————————–|—————-|
| GPU利用率(Util) | 计算核心活跃度 | 80%-95% |
| 显存占用(Mem Used)| 进程占用的显存容量 | ≤总显存的90% |
| 温度(Temp) | GPU芯片温度 | ≤85℃ |
常见问题与优化
- 进程卡死:通过
kill -9 PID终止异常进程,排查代码或驱动问题。 - 显存泄漏:使用内存分析工具(如PyTorch的
memory_stats)定位未释放的缓存。 - 多进程竞争:采用MIG(多实例GPU)技术划分物理GPU为独立实例。
行业案例:GPU进程的实际价值
- 互联网公司:某头部电商使用GPU进程优化推荐算法,点击率提升12%。
- 科研机构:上海超算中心通过GPU并行计算,将基因组比对效率提高20倍。
- 影视行业:好莱坞工作室采用GPU渲染集群,单部电影渲染周期减少60%。
未来趋势与挑战
- 硬件升级:随着H100、MI300等GPU发布,单卡算力提升将推动进程调度更精细化。
- 软件生态:开源框架(如Ray、Horovod)进一步简化分布式GPU进程管理。
- 安全性需求:进程级加密、显存隔离技术(如NVIDIA Confidential Computing)成为重点。
引用说明
- NVIDIA官方文档:CUDA编程指南、MIG技术白皮书
- 行业报告:Gartner《2025年AI基础设施趋势》、IDC《全球GPU服务器市场分析》
- 案例来源:AWS、阿里云、NASA公开技术博客
通过科学的GPU进程管理,企业和开发者可最大化释放算力价值,应对日益复杂的计算需求。