上一篇
如何通过GPU服务器支持实现计算性能飞跃?
GPU服务器支持提供高性能并行计算能力,适用于AI训练、深度学习及大规模数据处理,其内置多卡协同架构加速运算效率,兼容主流开发框架,配备高效散热与稳定供电系统,确保长时间可靠运行,并支持远程管理与实时监控,满足企业级算力需求。
GPU服务器支持:技术底座与业务升级的核心动力
在人工智能、高性能计算、图形渲染等领域快速发展的今天,GPU服务器已成为企业数字化进程中的关键基础设施,其强大的并行计算能力、高效的资源利用率以及广泛的应用场景,为科研机构、互联网企业、智能制造等行业提供了技术突破和业务增长的基石,以下从核心优势、典型场景、选型建议及服务支持维度展开说明,帮助用户全面了解GPU服务器的价值与选择策略。
GPU服务器的核心优势
高性能并行计算
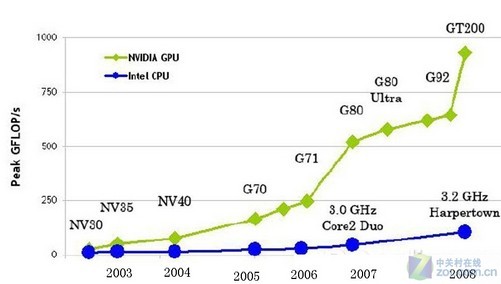
GPU(图形处理器)凭借数千个计算核心的架构设计,擅长处理大量并行任务,与CPU相比,其在深度学习训练、图像处理等场景中的计算效率可提升数十倍。
典型应用:AI模型训练、科学模拟、大数据分析。能效比优化
相同算力需求下,GPU服务器的功耗和硬件成本通常低于CPU集群,NVIDIA A100 GPU的单卡FP32算力达19.5 TFLOPS,可显著降低企业IT投入。软硬件生态完善
GPU厂商(如NVIDIA、AMD)与主流云计算平台、框架(TensorFlow、PyTorch)深度适配,提供CUDA、ROCm等开发工具链,降低开发门槛。
GPU服务器的典型应用场景
人工智能与深度学习
支持大规模神经网络训练与推理,适用于自然语言处理(NLP)、计算机视觉(CV)等场景。
案例:某自动驾驶公司采用8卡A100服务器,模型训练时间缩短70%。科学计算与工程仿真
加速流体力学、分子动力学模拟,缩短科研周期。
案例:某高校超算中心利用GPU集群完成气候模拟,效率提升12倍。图形渲染与元宇宙
提供实时3D渲染能力,支撑游戏开发、虚拟现实(VR)等场景。
边缘计算与实时处理
Jetson系列等边缘GPU设备可部署于智慧城市、工业质检等低延迟场景。
如何选择适合的GPU服务器?
按需求匹配算力
- 训练型任务:选择高显存、高带宽的GPU(如NVIDIA A100/H100)。
- 推理型任务:注重性价比,可选用T4、A30等专为推理优化的型号。
硬件扩展性
- 多卡互联技术(NVLink/Switch)提升多任务吞吐量。
- 支持PCIe 4.0/5.0接口,避免数据传输瓶颈。
软件与框架兼容性
确保服务器支持主流AI框架(TensorFlow、PyTorch)、容器化环境(Docker/Kubernetes)。散热与稳定性
GPU高负载下的散热方案(液冷/风冷)直接影响设备寿命与稳定性。
专业服务支持:保障GPU服务器的长期价值
定制化解决方案
根据业务需求提供硬件选型、集群架构设计、网络优化等全流程支持,- 分布式训练中的多节点通信优化。
- 混合云场景下的GPU资源弹性调度。
运维与监控体系
- 7×24小时硬件状态监测与故障预警。
- 性能调优服务(如显存碎片整理、任务调度算法优化)。
安全与合规
- 数据加密传输与存储方案。
- 符合等保2.0、GDPR等法规要求。
技术培训与社区支持
- 提供CUDA编程、模型压缩等培训课程。
- 接入开发者社区,共享最佳实践。
常见问题解答(FAQ)
Q1:GPU服务器与普通服务器的区别?
A:GPU服务器专为并行计算优化,配备多块高性能显卡,适用于AI、渲染等场景;普通服务器以CPU为核心,适合通用计算任务。
Q2:是否支持混合部署CPU与GPU?
A:支持,通过异构计算架构(如NVIDIA Grace Hopper),可协同发挥CPU的逻辑处理能力与GPU的并行算力。
Q3:如何评估所需GPU数量?
A:需结合模型参数量、数据集规模、训练时长综合测算,1750亿参数的GPT-3需数千块GPU进行训练。
引用说明
- NVIDIA官方文档:CUDA并行计算架构技术白皮书
- IDC报告《2025全球AI基础设施市场预测》
- Gartner研究《企业GPU服务器选型指南》
— 基于公开技术资料与行业实践总结,具体配置方案需结合实际业务需求评估。)