
上一篇
如何正确安装GPU服务器程序才能提升性能?
GPU服务器安装程序通常涉及硬件驱动配置、深度学习框架部署及环境优化,主要步骤包括安装NVIDIA显卡驱动、CUDA/cuDNN工具包,搭建TensorFlow/PyTorch等计算框架,并通过压力测试验证多卡并行性能与稳定性,需注意硬件兼容性检查和散热方案设计。
GPU服务器安装程序详细指南
在人工智能、深度学习和高性能计算领域,GPU服务器已成为核心硬件设备,正确安装GPU服务器不仅能确保硬件性能最大化,还能提升系统稳定性和安全性,以下为详细安装步骤与注意事项,适用于企业用户、开发者和研究人员。
安装前的准备工作
硬件兼容性验证
- 确认服务器主板支持GPU型号(如NVIDIA A100、RTX 4090等),检查PCIe插槽版本(建议PCIe 4.0或以上)。
- 核对电源功率是否满足GPU需求(例如NVIDIA H100需700W以上独立供电)。
- 确保机箱散热设计支持多GPU并行(风冷/液冷方案需提前规划)。
系统环境准备
- 操作系统选择:推荐Ubuntu 22.04 LTS或CentOS 7.9(需内核版本≥5.0)。
- 禁用Nouveau驱动(针对NVIDIA GPU):
echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf sudo update-initramfs -u
工具与依赖项安装
- 安装编译工具链:
sudo apt-get install build-essential linux-headers-$(uname -r)
- 安装编译工具链:
GPU驱动与CUDA工具包安装
驱动安装(以NVIDIA为例)

- 从NVIDIA官网下载对应驱动(推荐使用生产分支版本)。
- 执行驱动安装命令:
chmod +x NVIDIA-Linux-x86_64-535.86.05.run sudo ./NVIDIA-Linux-x86_64-535.86.05.run --silent --dkms
- 验证安装:
nvidia-smi # 应显示GPU状态与驱动版本
CUDA工具包配置
- 下载CUDA 12.2安装包并运行:
sudo sh cuda_12.2.0_535.54.03_linux.run
- 配置环境变量(添加至
~/.bashrc):export PATH=/usr/local/cuda-12.2/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH
- 下载CUDA 12.2安装包并运行:
深度学习框架支持
安装GPU加速库
- cuDNN部署:
tar -xzvf cudnn-linux-x86_64-8.9.3.28_cuda12-archive.tar.xz sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include sudo cp cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64 sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
- cuDNN部署:
TensorFlow/PyTorch环境配置
- 使用Anaconda创建虚拟环境:
conda create -n gpu_env python=3.10 conda install -c nvidia cuda-toolkit
- 安装框架(示例为PyTorch):
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
- 使用Anaconda创建虚拟环境:
多GPU集群配置(可选)
NCCL库安装
sudo apt-get install libnccl2 libnccl-dev
多节点通信优化
- 配置SSH免密登录:
ssh-keygen -t rsa ssh-copy-id user@node2
- 使用MPI库(如OpenMPI)进行任务分发测试。
- 配置SSH免密登录:
安全与维护建议
权限管理
- 限制非管理员用户访问GPU设备(通过
/etc/udev/rules.d设置权限)。
- 限制非管理员用户访问GPU设备(通过
监控与报警
- 部署Prometheus + Grafana监控GPU温度、显存使用率。
- 设置阈值报警(如GPU温度>85℃触发邮件通知)。
定期维护
- 每季度清理服务器内部积灰。
- 每月更新驱动与CUDA版本(建议通过
apt-get upgrade自动化)。
常见问题解答
Q:安装驱动后系统无法启动?
A:进入恢复模式卸载驱动,检查内核版本兼容性。Q:多GPU卡负载不均衡?
A:使用nvidia-smi topo -m分析拓扑结构,优化PCIe通道分配。Q:CUDA程序报
out of memory错误?
A:通过torch.cuda.empty_cache()释放缓存,或调整batch size。
引用说明
- NVIDIA官方驱动安装文档:https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes
- CUDA Toolkit用户指南:https://docs.nvidia.com/cuda/cuda-installation-guide-linux
- Linux内核设备管理规范:https://www.kernel.org/doc/html/latest/admin-guide/
相关文章

腾讯云gpu服务器,腾讯云GPU服务器(腾讯云gpu服务器,腾讯云gpu服务器区别)
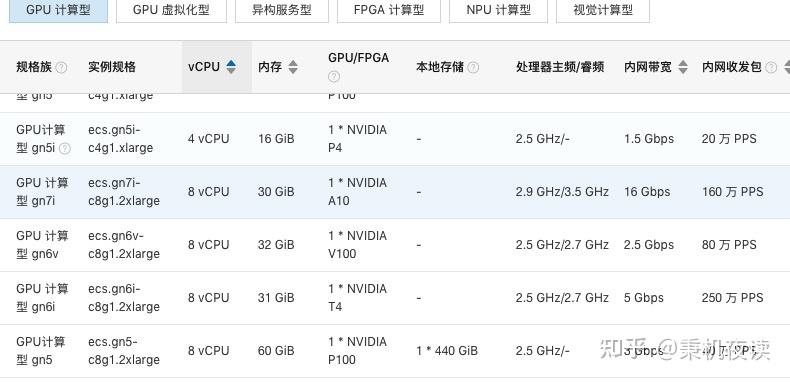
腾讯云gpu服务器(阿里云 GPU服务器)(腾讯云gpu服务器价格)
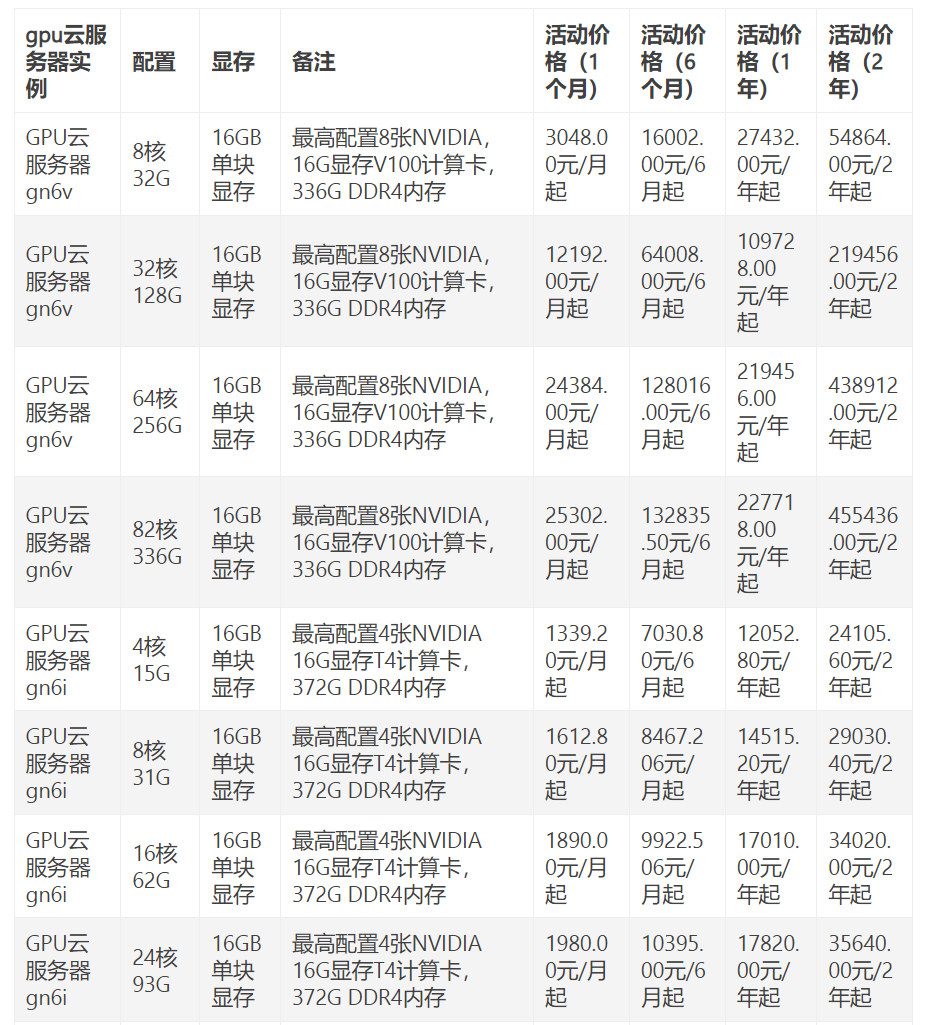
gpu服务器租用,阿里云gpu服务器租用2022年更新(阿里云gpu服务器租用价格表)

gpu服务器怎么用,GPU服务器搭建2022年更新(gpu服务器怎么使用)

Contabo:GPU服务器(Nvidia Tesla T4 16 GB)(conda gpu)(gpu服务器使用教程)
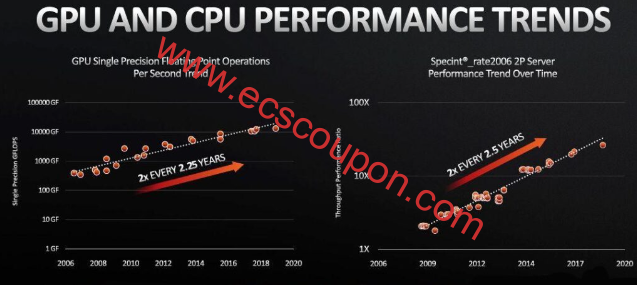
GPU服务器是否需要增加内存才能提升性能?
GPU服务器需要哪些关键配置才能提升性能?

ubuntu安装git(ubuntu安装gitlfs)(ubuntu下安装git)








