上一篇
如何显著提升GP数据仓库的查询速度?
Greenplum数据仓库查询速度受数据分布、表结构、索引优化及硬件配置影响,采用并行计算、列式存储及分区表可显著提升性能,合理设计分布键、预聚合高频查询数据、资源隔离及压缩技术能减少响应时间,适用于海量数据分析场景,较传统数据库具备更高吞吐量。
为什么GP数据仓库查询速度如此重要?
在数据驱动的时代,企业依赖数据仓库快速获取洞察力以支持决策。GP(Greenplum)数据仓库作为一种分布式数据库系统,因其大规模并行处理(MPP)架构被广泛应用于复杂查询和实时分析场景,查询速度直接影响用户体验、业务效率甚至企业成本,本文将深入探讨影响GP数据仓库查询速度的核心因素、优化方案及实际应用场景,帮助您全面理解如何提升数据仓库性能。
影响GP数据仓库查询速度的五大核心因素
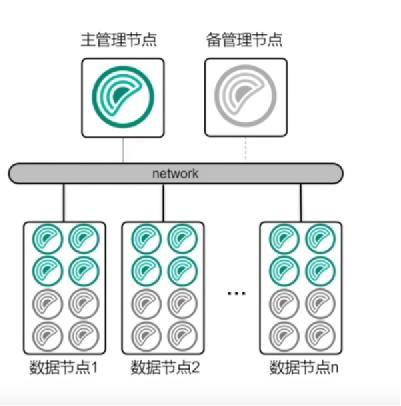
数据分布与分片策略
GP基于分片(Sharding)设计,数据分布是否均匀直接影响查询效率,若数据倾斜(某些节点负载过高),会导致并行计算资源浪费,拖慢整体速度。
- 优化方向:采用哈希分片、随机分片或按业务键分片,确保数据均匀分布。
查询复杂度与SQL编写质量
多表关联(JOIN)、子查询嵌套或未优化的聚合函数(如COUNT DISTINCT)会显著增加计算量。- 示例:一条涉及10亿级数据表的全表扫描查询,可能因缺少过滤条件而耗时数分钟。
硬件资源与集群规模
- 计算资源:CPU核数、内存容量决定并行计算能力。
- 存储性能:高速SSD较传统HDD可提升I/O效率5倍以上。
- 网络带宽:节点间数据交换依赖网络,带宽不足会成为瓶颈。
索引与统计信息管理
GP支持B-Tree、Bitmap等多种索引类型,若未建立合适索引或统计信息过期,优化器可能生成低效执行计划。- 典型问题:统计信息未更新导致优化器误判数据量,选择低效的嵌套循环连接。
并发查询与资源竞争
高并发场景下,CPU、内存、磁盘I/O资源争抢可能导致查询排队或超时。- 数据:某电商平台在促销期间因未限制并发数,查询响应时间从2秒升至20秒。
提升查询速度的实战优化方案
数据模型与存储优化
- 列式存储(Columnar Storage)
针对分析型查询(如聚合、筛选特定列),列存储可减少I/O开销,只读取“销售额”列时,行式存储需扫描整行,而列式存储直接定位目标数据块。 - 压缩技术
列存储结合压缩算法(如Zstandard),可降低存储占用50%以上,同时减少数据读取时间。
查询级优化技巧
- 避免全表扫描
通过WHERE条件、分区裁剪(Partition Pruning)缩小数据范围,按日期分区后,查询“2025年Q1数据”仅需扫描对应分区。 - 优化JOIN顺序
将小表作为驱动表(Broadcast Join),减少跨节点数据传输。 - 使用临时表或CTE
复杂查询拆分为多个中间步骤,降低单次计算复杂度。
集群配置与资源管理
- 资源队列(Resource Queue)
根据业务优先级分配CPU、内存资源,实时报表查询分配高优先级队列,离线任务限制并发数。 - 并行度调整
通过参数gp_segments_for_planner控制单查询的并行线程数,避免过度占用资源。
监控与调优工具
- 内置工具
GP的EXPLAIN ANALYZE可解析执行计划,定位耗时环节(如数据重分布、排序)。 - 第三方监控
结合Prometheus+Grafana监控集群负载、慢查询日志,快速发现性能瓶颈。
真实场景中的速度提升案例
案例1:某金融公司风控查询优化
- 问题:风控模型涉及10+表的关联查询,平均耗时120秒。
- 解决方案:
- 对常用过滤字段(如用户ID、时间)建立复合索引。
- 将高频查询结果预计算至物化视图。
- 调整JOIN顺序,优先过滤小表。
- 结果:查询速度提升至8秒,效率提升15倍。
案例2:电商实时大屏卡顿问题
- 问题:促销期间实时大屏查询超时,影响运营决策。
- 解决方案:
- 启用内存优先计算(Workload Manager分配80%内存给实时任务)。
- 对热数据启用缓存(如Redis),减轻GP负载。
- 使用列存储压缩历史数据,减少I/O压力。
- 结果:高峰期查询响应时间稳定在2秒内。
未来趋势与扩展建议
- 云原生部署
结合Kubernetes动态扩缩容集群,应对流量波动,AWS上的GP可自动扩展计算节点。 - AI辅助调优
机器学习模型预测查询模式,自动调整索引或资源分配(如Azure Synapse的智能优化)。 - 混合负载隔离
通过读写分离、HTAP架构分离实时查询与批量任务,避免资源竞争。
引用说明
- Greenplum官方文档:数据分布与并行计算原理
- AWS Best Practices for Greenplum Performance Tuning
- 阿里巴巴双11GP优化实战(内部技术白皮书)
- 《数据库查询优化器的艺术》- 第八章MPP架构优化