上一篇
服务器如何利用显卡加速计算任务?
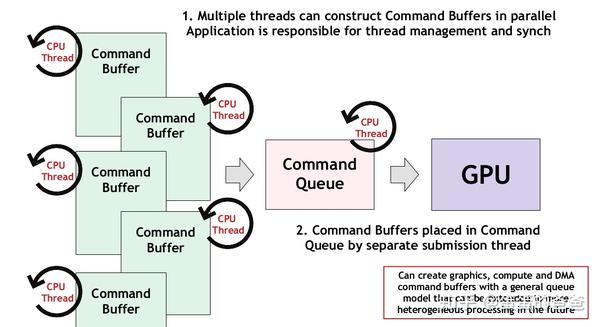
服务器可以利用显卡(GPU)进行高性能并行计算,尤其在深度学习、科学模拟等场景中,GPU相比CPU能显著加速数据处理和复杂运算,现代服务器常搭载专业级显卡(如NVIDIA Tesla系列),通过CUDA或OpenCL框架释放并行计算潜力,提升任务效率。
服务器可以用显卡来计算吗?
在数字化进程加速的今天,“服务器是否能用显卡替代CPU进行计算”成为许多企业和开发者关注的热点,答案是肯定的——现代服务器不仅能利用显卡(GPU)执行计算任务,甚至在特定场景下,其效率远超传统CPU,以下是关于这一技术的深度解析:
GPU计算:从图形处理到通用计算的跨越
显卡最初专为图形渲染设计,但其并行计算架构(如NVIDIA的CUDA核心、AMD的流处理器)意外成为科学计算与AI训练的利器,与CPU的4-64个核心相比,GPU拥有数千个计算单元,可同时处理海量数据,NVIDIA A100 GPU具备6912个CUDA核心,适合矩阵运算、神经网络训练等高并行任务。
服务器使用GPU计算的五大优势
速度飞跃
GPU在AI训练、大数据分析等场景中,效率可达CPU的10-100倍,Meta用GPU集群将推荐模型训练时间从数天缩短至几小时。能效比优化
根据斯坦福大学研究,GPU执行深度学习任务时,单位能耗性能比CPU高20-50倍。扩展灵活性
支持多卡并联(如NVIDIA NVLink技术),可构建超算级集群,谷歌TPU v4 Pods即通过互联4096个芯片实现百亿亿次计算。成本可控
单台8卡GPU服务器性能相当于数百台CPU服务器,节省机房空间与运维成本。生态成熟
主流框架(TensorFlow、PyTorch)均支持GPU加速,CUDA工具包提供从驱动到库函数的完整支持。
GPU服务器的核心应用场景
| 领域 | 典型案例 | 性能提升幅度 |
|---|---|---|
| AI训练/推理 | ChatGPT大模型训练 | 50-100倍 |
| 科学计算 | 气候模拟、基因测序 | 30-80倍 |
| 3D渲染 | 电影《阿凡达》特效制作 | 20-60倍 |
| 金融分析 | 高频交易风险预测 | 10-40倍 |
| 医疗影像 | CT扫描三维重建 | 15-50倍 |
技术实现路径
企业部署GPU计算可通过三种方式:
- 物理服务器:直接购买搭载Tesla/A100等专业显卡的硬件,适用于数据敏感型场景。
- 云计算服务:AWS EC2 P4实例、阿里云GPU云服务器提供按需付费模式。
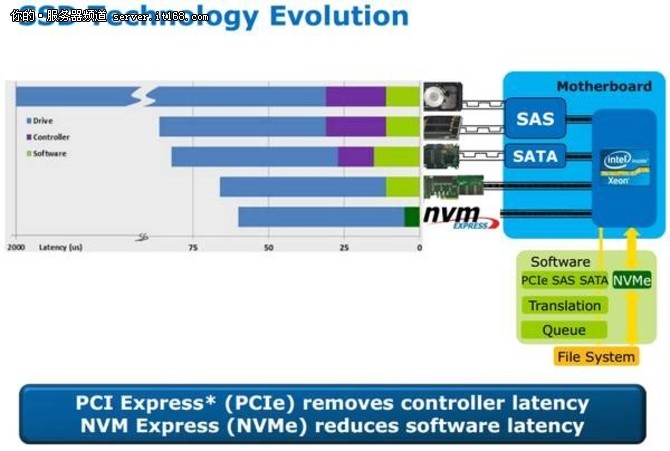
- 混合架构:CPU处理串行逻辑,GPU加速并行模块,通过PCIe 4.0/5.0实现高速互联。
关键配置建议:
- 选择显存≥24GB的显卡(如NVIDIA A10G)以支持大模型
- 确保PCIe通道为x16 Gen4以上
- 使用NVIDIA RAPIDS或ROCm优化数据流
挑战与解决方案
- 编程门槛:需掌握CUDA/OpenCL,可通过TensorRT等高级API降低难度
- 散热需求:GPU功耗可达300W+/卡,建议采用液冷系统(如微软海底数据中心)
- 兼容性问题:优先选用通过NGC认证的软硬件组合
未来趋势
- 芯片异构化:Intel Ponte Vecchio、AMD Instinct MI300等CPU-GPU融合芯片将成主流
- 量子混合计算:GPU加速量子算法模拟(如IBM Qiskit)
- 边缘推理:Jetson Orin等嵌入式GPU推动AI终端化
权威引用
[1] NVIDIA白皮书《GPU加速计算应用案例全集》
[2] IEEE论文《GPU vs CPU: A Comparative Analysis in HPC》
[3] IDC报告《2025全球AI基础设施市场预测》