上一篇
分布式消息服务如何使用
通过生产者发送消息至队列,消费者订阅处理,确保异步和解耦,注意消息顺序与可靠投递
分布式消息服务使用方法详解
分布式消息服务核心概念
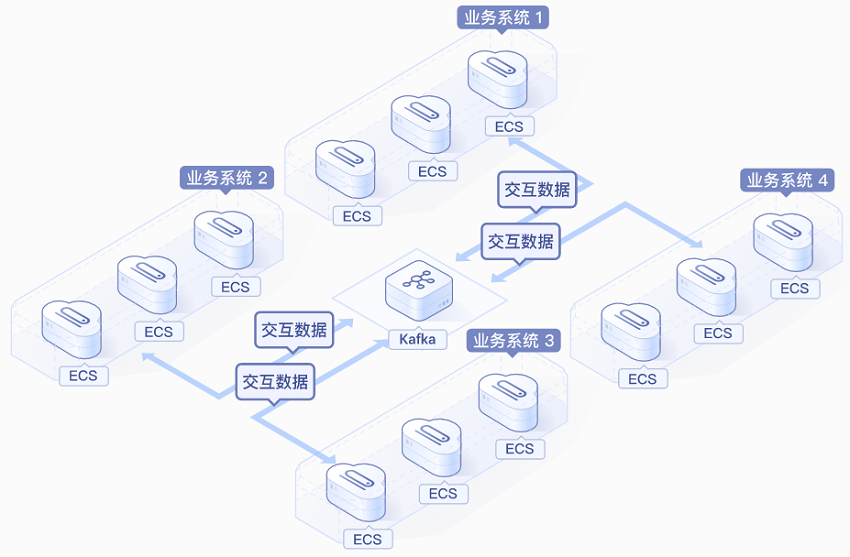
分布式消息服务(Distributed Message Service)是一种基于消息队列的通信机制,用于解耦系统、异步处理任务和平衡负载,其核心组件包括:
| 组件 | 功能描述 |
|---|---|
| Producer | 消息生产者,负责发送消息到消息队列 |
| Broker | 消息中间件服务器,负责存储、转发和管理消息队列 |
| Consumer | 消息消费者,订阅并处理队列中的消息 |
| Topic | 消息主题,用于区分不同业务场景的消息分类(类似邮件列表) |
| Queue | 消息队列,同一主题下可细分多个队列实现负载均衡或顺序消费 |
典型使用场景
分布式消息服务适用于以下场景:
- 异步任务处理
- 用户注册后发送欢迎邮件、短信验证码
- 电商下单后触发库存扣减、支付回调等链路
- 流量削峰填谷
- 瞬秒活动突发流量缓冲
- 日志采集系统应对瞬时高频写入
- 服务解耦
- 微服务间通过消息传递数据而非直接调用
- 跨系统数据同步(如ERP与CRM对接)
- 事件驱动架构
- 基于消息事件触发下游业务流程
- 实现CQRS(命令查询责任分离)模式
实现步骤与代码示例
环境准备
| 操作步骤 | 说明 |
|---|---|
| 选择消息中间件 | Kafka/RocketMQ/RabbitMQ(根据场景需求) |
| 部署Broker集群 | 至少3个节点保证高可用 |
| 创建Topic | order-service |
| 配置消费者组 | payment-consumer-group |
生产者代码示例(Java)
// 初始化生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.JsonSerializer");
// 创建生产者实例
KafkaProducer<String, Order> producer = new KafkaProducer<>(props);
// 发送订单消息
Order order = new Order(1001, "PENDING");
ProducerRecord<String, Order> record = new ProducerRecord<>("order-service", order.getId(), order);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// 处理发送失败
} else {
// 记录分区信息: metadata.partition()
}
});消费者代码示例(Python)
from kafka import KafkaConsumer
import json
# 初始化消费者
consumer = KafkaConsumer(
'order-service',
bootstrap_servers=['broker1:9092', 'broker2:9092'],
group_id='payment-consumer-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
# 循环消费消息
for message in consumer:
order = message.value
if order['status'] == 'PENDING':
# 执行支付扣款逻辑
print(f"Processing order {order['id']}")
consumer.commit() # 手动提交偏移量关键技术要点
消息序列化
- 常见格式:JSON(易读)、Avro(高效)、Protobuf(紧凑)
- 建议:关键业务字段使用Schema Registry管理
可靠性保障机制
| 机制类型 | 实现方式 |
|—————-|————————————————————————–|
| 消息确认 | Consumer显式调用commit()或auto.offset.reset=earliest |
| 消息持久化 | Broker配置磁盘存储(如Kafka log.dirs) |
| 消息重试 | Producer配置retries=3,结合死信队列(DLQ)处理失败消息 |
顺序性保障
- 订单场景需启用分区键(如按order_id哈希取模)
- RocketMQ支持消息消费偏移量管理
监控与运维
| 监控指标 | 阈值预警 |
|—————-|————————————————————————–|
| 消息堆积量 | >80%队列容量时触发扩容警报 |
| 消费延迟 | 超过5分钟未消费视为异常 |
| Broker负载 | CPU使用率>90%或内存使用>80%时触发扩容 |
典型问题解决方案
场景1:消息积压处理
| 问题表现 | 解决方案 |
|---|---|
| 单个Topic消息堆积 | 增加Partition数量(如从3个扩展到10个),提升并行消费能力 |
| 消费者消费能力不足 | 横向扩展Consumer实例数量,或优化单实例处理逻辑 |
| 消息峰值突增 | 开启限流策略(如Kafka throttle机制),或使用延时队列平缓处理 |
场景2:消息重复消费
# 幂等性处理示例
def process_order(order_id):
# 查询数据库是否存在该订单
if not check_order_exists(order_id):
# 执行业务逻辑
create_order_record(order_id)
else:
# 忽略重复处理
log.warning(f"Duplicate order {order_id} detected")最佳实践建议
消息设计原则
- 控制消息体大小(建议<1MB)
- 避免频繁变更消息结构
- 关键字段放在消息头部
消费者管理
- 设置合理的
auto.offset.reset参数(生产环境建议largest) - 禁用自动提交偏移量(enable.auto.commit=false)
- 定期清理过期消费组(使用Rebalance机制)
- 设置合理的
高可用配置
| 组件 | 高可用方案 |
|————–|—————————————————————————-|
| Broker | 部署3个以上节点,配置多副本存储(如Kafka replication.factor=3) |
| Producer | 启用客户端故障转移(failover机制) |
| Consumer | 部署多实例组成消费组,实现负载均衡 |
FAQs
Q1:消息积压时如何处理?
A1:首先排查消费者消费速率是否低于生产速率,可通过以下方式缓解:
- 增加Consumer实例数量
- 提升单个Consumer处理性能(如优化SQL查询)
- 临时关闭非核心业务的消息生产
- 分析消息堆积趋势,考虑水平扩展Broker集群
Q2:如何保证消息不丢失?
A2:需从三个环节保障:
- 生产端:设置
acks=all,开启可靠投递 - 传输端:Broker配置同步刷盘(如Kafka
unclean.leader.election.enable=false) - 消费端:开启手动提交偏移量,处理完业务后再