上一篇
分布式消息中间件如何使用
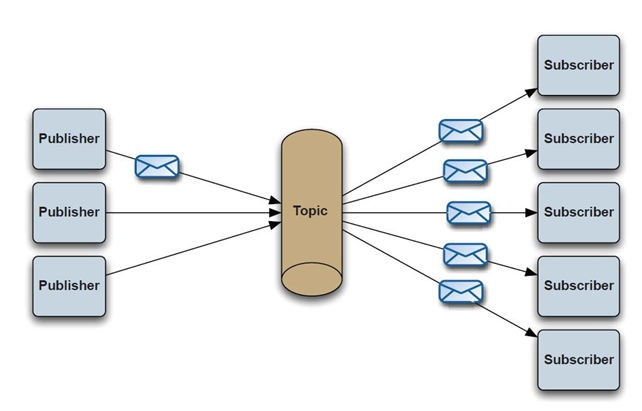
分布式消息中间件用于系统解耦、异步处理及削峰填谷,通过生产者发送消息至队列,消费者异步消费,支持持久化保障可靠性,可配置路由实现顺序性,适用于高并发场景如订单
核心使用步骤
选型与环境准备
| 维度 | Kafka | RabbitMQ | RocketMQ | Redis Stream |
|---|---|---|---|---|
| 适用场景 | 高吞吐量日志、大数据 | 复杂路由、RPC | 金融级事务、大促峰值 | 轻量级实时数据流 |
| 协议支持 | 自有二进制协议 | AMQP | 自定义协议 | Redis命令 |
| 部署复杂度 | 中等(依赖ZooKeeper) | 低(独立Broker) | 高(多组件) | 极低(无额外组件) |
| 消息顺序性 | 分区内有序 | 默认全局有序 | 严格顺序(RocketMQ) | 默认无序 |
选择建议:
- 高并发日志场景优先 Kafka
- 复杂路由或 RPC 场景用 RabbitMQ
- 金融交易或大促场景选 RocketMQ
- 轻量级实时处理用 Redis Stream
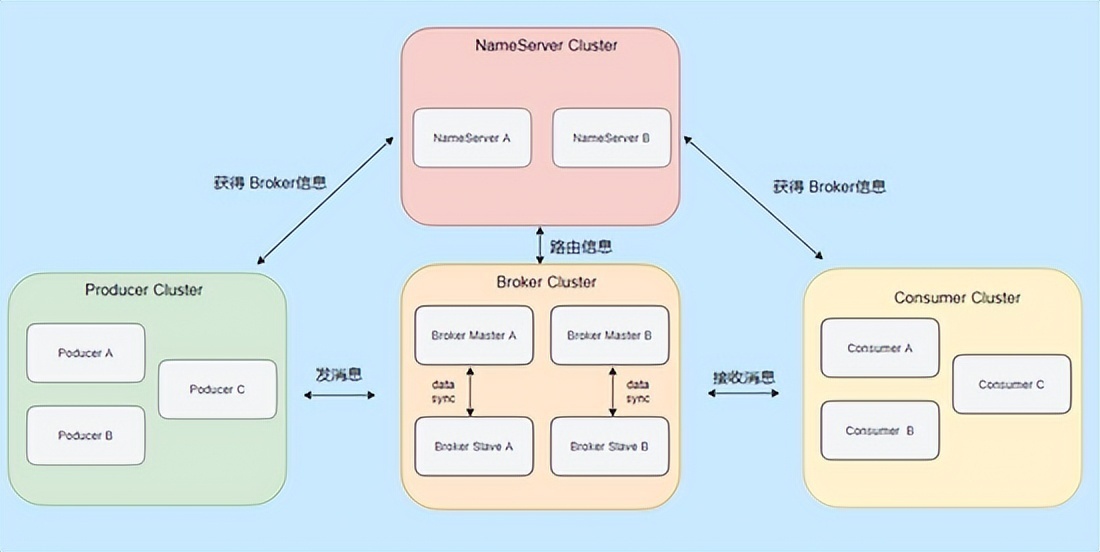
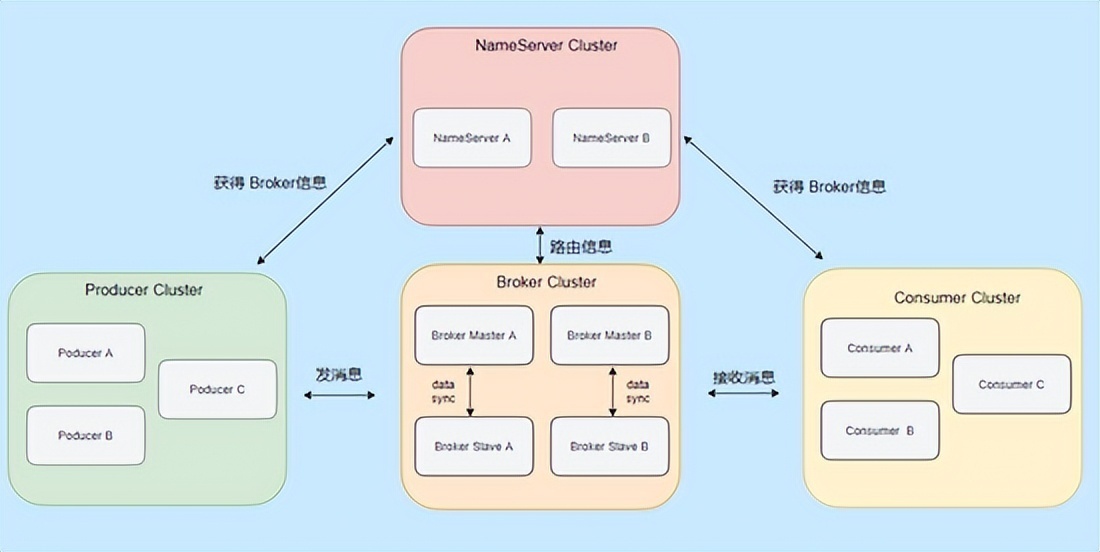
基础架构部署
- 集群搭建:
- Kafka:至少3个Broker+ZooKeeper集群
- RabbitMQ:镜像队列模式(最少3节点)
- RocketMQ:Broker+NameServer+MetaStore
- 关键配置项:
| 参数 | 作用 | 建议值 |
|——————-|——————————|————————-|
| 消息持久化 | 防止Broker宕机丢失数据 | Kafka:log.retention=7天 |
| ACK机制 | 确保消息被消费 | RabbitMQ:autoAck=false|
| 重试次数 | 失败后重新投递 | RocketMQ:retry=3|
| 消费偏移量存储 | 断点续传 | Kafka:offset.storage=kafka|
生产与消费代码实现
生产者示例(Java + Kafka):
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("topic-name", "key1", "value1"));
producer.close();消费者示例(Python + RabbitMQ):
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('rabbitmq-host'))
channel = connection.channel()
channel.queue_declare(queue='task_queue')
def callback(ch, method, properties, body):
print(f"Received {body}")
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
channel.start_consuming()高级功能配置
| 功能 | 实现方式 |
|---|---|
| 消息顺序性 | Kafka:相同Key发送至同一分区;RocketMQ:RELIABLE_DELIVER+消息消费偏移 |
| 死信队列 | RabbitMQ:设置x-dead-letter-routing-key;Kafka:手动创建DLQ主题 |
| 延迟消息 | RabbitMQ:插件rabbitmq_delayed_message_exchange;Kafka:定时任务扫描 |
| 流量控制 | RocketMQ:FLOW_CONTROL_BY_COUNT限流;Kafka:客户端速率限制 |
关键使用场景与优化
典型应用场景
| 场景 | 设计要点 |
|---|---|
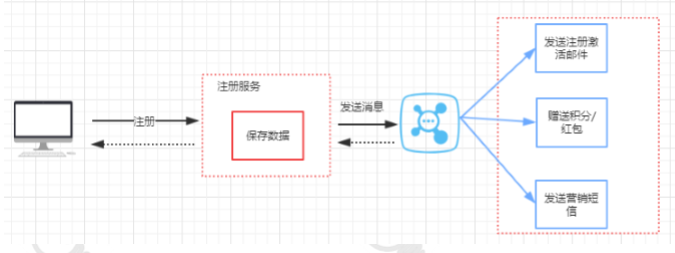
| 订单系统解耦 | 订单写入数据库后发送消息到MQ,库存/支付系统异步消费 |
| 日志聚合分析 | Kafka收集各服务日志,ELK栈订阅消费 |
| 服务间RPC调用 | RabbitMQ通过replyTo实现请求响应模式 |
| 峰值削峰 | 电商大促时,将请求写入MQ,后续按消费能力处理 |
性能优化策略
- 批量处理:Kafka生产者启用
batch.size=16KB,消费者批量拉取 - 异步IO:RabbitMQ使用
ConsumerWorkService异步处理消息 - 压缩算法:启用LZ4/Snappy压缩减少网络传输(Kafka:
compression.type=lz4) - 连接池复用:复用Consumer/Producer连接,避免频繁创建销毁
常见问题与解决方案
FAQs
Q1:消息积压如何处理?
- 排查步骤:
- 检查Broker磁盘IO是否瓶颈(如Kafka日志清理策略)
- 增加Consumer实例数(需保证消费逻辑幂等)
- 提升硬件配置(CPU/内存/SSD)
- 优化消息大小(Kafka建议<1MB/条)
Q2:如何保证消息不丢失?
- 可靠性方案:
- Kafka:
acks=all+retries=3+min.insync.replicas=2 - RabbitMQ:
confirmSelect确认机制 + 持久化队列(durable=true) - RocketMQ:同步刷盘(
SYNC_FLUSH) + 可靠投递
- Kafka:
监控与运维
核心监控指标:
| 指标 | 阈值预警 |
|——————-|—————————————–|
| Broker磁盘使用率 | >85%(需扩容或清理过期数据) |
| 消息堆积量 | >10万条(需增加Consumer或扩容Partition) |
| 消费者延迟 | >5分钟(检查业务逻辑或扩容) |
| JVM内存使用 | >70%(调整堆内存或优化代码) |工具推荐:
- Kafka:Prometheus+Grafana监控JMX指标
- RabbitMQ:启用
management_plugin查看Web界面 - RocketMQ:集成阿里云ARMS监控工具
通过以上步骤,可构建高可用、高性能的分布式消息系统,实际使用中需结合业务