上一篇
分布式消息传递如何使用
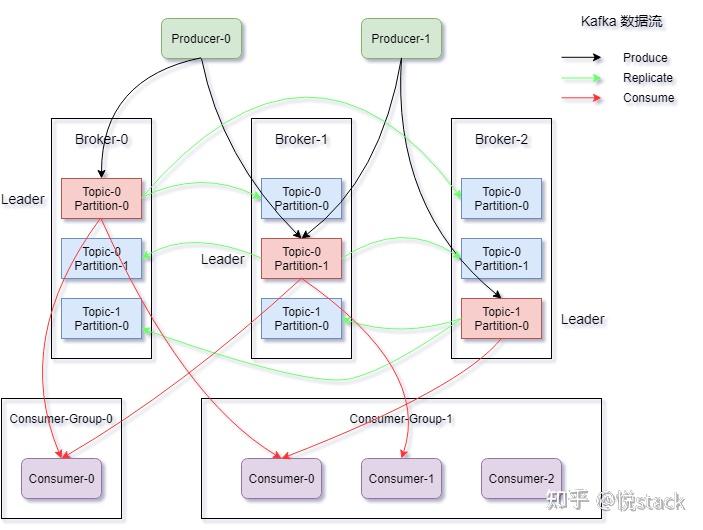
分布式消息传递通过消息队列(如Kafka/RabbitMQ)实现服务解耦,生产者发送消息至队列,消费者异步处理,用于削峰、缓冲流量、确保可靠传输,提升系统容错与扩展
分布式消息传递的核心原理与使用实践
分布式消息传递的基础概念
分布式消息传递是一种通过中间件实现跨进程、跨节点的异步通信机制,其核心目标是通过解耦生产者与消费者,提升系统的可扩展性、容错性和响应效率,消息传递系统通常包含以下角色:
- 生产者(Producer):负责生成并发送消息
- 消息队列(Broker):存储和管理消息的中间件
- 消费者(Consumer):接收并处理消息的客户端
核心组件与工作机制
| 组件 | 功能描述 | 典型实现示例 |
|---|---|---|
| 消息队列 | 临时或持久化存储消息,支持先进先出(FIFO)或自定义排序策略 | Kafka、RabbitMQ、Redis |
| 序列化协议 | 将对象转换为可传输的字节流(如JSON、Protobuf、Avro) | JSON(通用)、Protobuf(高效) |
| 消息确认机制 | 消费者处理完成后发送ACK,确保消息不被重复消费 | RabbitMQ的ACK机制 |
| 负载均衡 | 通过分区(Partition)或主题(Topic)实现消息的并行处理 | Kafka的Partition机制 |
使用步骤与关键配置
环境搭建
- 选择消息中间件(如Kafka、RabbitMQ)
- 部署集群(推荐至少3个Broker节点以保证高可用)
- 配置持久化存储(如Kafka的Log目录)
生产者实现
# 示例:Python使用RabbitMQ发送消息 import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) # 创建持久化队列 # 发送持久化消息 channel.basic_publish( exchange='', routing_key='task_queue', body='Hello World', properties=pika.BasicProperties(delivery_mode=2) # 2表示持久化 ) connection.close()消费者实现
// 示例:Java使用Kafka消费消息 Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test-group"); props.put("enable.auto.commit", "false"); // 手动提交偏移量 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { System.out.printf("Offset: %d, Key: %s, Value: %s%n", record.offset(), record.key(), record.value()); consumer.commitSync(); // 手动提交偏移量 } }关键配置项
| 配置项 | 作用 | 建议值 |
|———————–|———————————————————————-|—————————|
|ackMode| 消息确认模式(自动/手动) | 手动确认(高可靠性场景) |
|prefetchCount| 消费者单次拉取消息的最大数量 | 1(避免负载不均) |
|messageTTL| 消息存活时间(毫秒) | 根据业务需求设置 |
|retryPolicy| 消息消费失败重试策略 | 指数退避(3次重试) |
典型应用场景
异步任务处理
- 场景:电商订单处理、日志收集
- 优势:生产者快速响应,消费者异步执行耗时操作
- 实现:使用RabbitMQ的RPC模式或Kafka的延时队列
流量削峰
- 场景:瞬秒活动、突发请求缓冲
- 实现:将请求写入消息队列,按队列容量控制消费速率
- 示例配置:
# Apache RocketMQ削峰配置 brokerConfig: messageQueueNum: 16 # 增加分区数量 sendMessageThreadPool: 8 # 并发发送线程数
服务解耦
- 场景:微服务间通信、数据管道传输
- 优势:消除直接依赖,支持独立扩展
- 模式:采用发布/订阅模式(如MQTT协议)
高级特性与优化策略
消息顺序性保障
- 问题:电商订单、金融交易需要严格顺序
- 解决方案:
- Kafka:启用
enable.idempotence=true+ 消息键分区 - RabbitMQ:使用
channel.basicQos(1)限制并发
- Kafka:启用
消息可靠性保障
| 可靠性级别 | 实现方式 |
|————|————————————————————————–|
| At least once | 消息确认+重试机制(可能导致重复消费) |
| Exactly once | 事务消息(如RocketMQ的可靠投递)+ 幂等性设计 |性能优化
- 批量处理:Kafka的
max.poll.records=500配置 - 压缩传输:启用Snappy/GZIP压缩(节省带宽40%-70%)
- 连接池复用:Netty长连接复用(减少TCP握手开销)
- 批量处理:Kafka的
常见问题与解决方案
FAQs
问:如何防止消息丢失?
答:- 生产者侧:启用可靠投递(如Kafka的
acks=all) - Broker侧:配置同步刷盘(SYNC_FLUSH)
- 消费者侧:开启手动确认+偏移量提交
- 网络层:使用TLS加密+心跳检测(如MQTT的KeepAlive)
- 生产者侧:启用可靠投递(如Kafka的
问:如何处理消息积压问题?
答:- 垂直扩展:增加Broker节点数量
- 水平扩展:拆分Topic为多个Partition
- 限流策略:设置
consumer.maxPollInterval防止过载 - 紧急处理:启动临时消费者实例进行引流
通过以上实践方法,开发者可根据业务需求灵活配置分布式消息系统,实际部署时需结合监控工具(如Prometheus+Grafana)实时观察消息吞吐量、延迟等