上一篇
分布式消息服务是什么
分布式消息服务通过消息队列实现系统解耦和异步通信,支持高并发、可靠传输及容错,适用于微服务架构的数据同步与
分布式消息服务是什么?
定义与背景
分布式消息服务(Distributed Message Service)是一种基于分布式架构的消息中间件技术,用于在复杂系统中实现异步通信、解耦和流量削峰,它通过将消息的发送方(生产者)与接收方(消费者)隔离,利用消息队列(Message Queue)或主题(Topic)作为缓冲区,确保消息在不同系统或服务之间可靠传递,其核心目标是解决高并发、分布式环境下的数据一致性、服务稳定性和资源利用率问题。
发展历程:
- 早期阶段:传统消息队列(如ActiveMQ、RabbitMQ)以单机部署为主,依赖本地存储,扩展性有限。
- 分布式演进:随着云计算和微服务兴起,消息系统向分布式架构转型(如Kafka、RocketMQ),支持多节点协同、高吞吐量和容错能力。
- 云原生时代:云厂商推出托管服务(如AWS SQS、阿里云 RocketMQ),提供弹性扩容、全球部署和免运维能力。
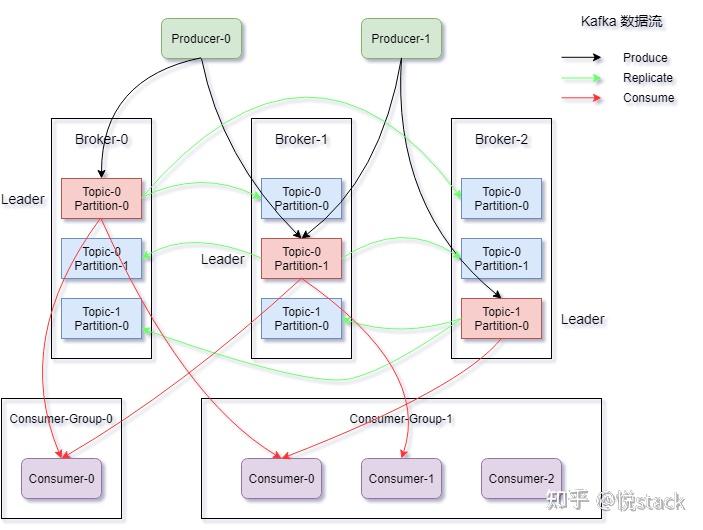
核心组件与架构
分布式消息服务的典型架构包含以下角色:
| 组件 | 功能描述 |
|---|---|
| Producer | 消息生产者,负责将业务数据封装为消息并发送到消息队列。 |
| Consumer | 消息消费者,订阅队列或主题并处理消息。 |
| Broker | 消息服务器,负责存储、转发消息,协调生产者与消费者。 |
| Message Queue | 消息队列,FIFO(先进先出)缓冲区,保证消息有序到达。 |
| Topic | 消息主题(发布/订阅模式),支持多消费者并行消费,适用于广播场景。 |
| Coordinator | 协调节点(如ZooKeeper),管理集群元数据、选举主节点、维护配置信息。 |
架构特点:
- 分布式部署:Broker节点横向扩展,数据分片(Partition)提升吞吐量。
- 高可用设计:通过副本机制(Replication)实现故障转移,保证服务不中断。
- 负载均衡:消费者组(Consumer Group)动态分配分区,均衡处理压力。
- 持久化存储:消息写入磁盘(如日志文件),防止因宕机导致数据丢失。
关键特性
| 特性 | 作用与实现方式 |
|---|---|
| 解耦与异步 | 生产者无需等待消费者处理结果,直接投递消息后继续执行,提升系统响应速度。 |
| 削峰填谷 | 突发流量时,消息堆积在队列中,下游服务按能力消费,避免资源过载。 |
| 可靠性保障 | 持久化:消息写入磁盘,支持ACK确认机制。 重试机制:消费失败后自动重投。 |
| 顺序性 | 通过分区顺序消费(如Kafka)、消息编号或事务保证局部或全局顺序。 |
| 可扩展性 | 新增Broker节点即可扩展容量,分区数动态调整,支持百万级TPS。 |
应用场景
- 电商订单处理:
用户下单后,订单服务将消息写入队列,库存、支付、物流等服务异步消费,避免同步调用延迟。
- 金融交易系统:
交易指令通过消息队列异步传递,确保高并发下的数据一致性(如 RocketMQ 的事务消息)。
- 日志收集与分析:
分布式系统日志通过消息队列(如 Kafka)集中存储,供实时计算(Flink)或批量分析(Hadoop)。
- IoT设备通信:
海量设备数据通过 MQTT 协议接入消息服务,统一处理后转发至业务系统。
与传统消息队列的对比
| 维度 | 传统消息队列(如RabbitMQ) | 分布式消息服务(如Kafka) |
|---|---|---|
| 架构 | 单机或主从模式 | 多节点对等扩展 |
| 吞吐量 | 万级/秒 | 百万级/秒(依赖分区数) |
| 存储模型 | 内存+磁盘混合存储 | 磁盘顺序写入(日志结构) |
| 扩展性 | 垂直扩展为主 | 水平扩展无上限 |
| 适用场景 | 低延迟、小规模系统 | 高吞吐、大数据流处理 |
技术挑战与解决方案
- 数据一致性:
- 问题:分布式环境下,网络延迟或节点故障可能导致数据不一致。
- 方案:采用Raft/Paxos协议(如RocketMQ)或依赖外部协调服务(如ZooKeeper)。
- 消息顺序性:
- 问题:某些场景(如订单处理)要求严格顺序消费。
- 方案:通过分区键哈希分配消息,或使用RocketMQ的顺序消息特性。
- 监控与运维:
- 问题:集群规模大时,故障定位困难。
- 方案:集成Prometheus、Grafana监控指标(如延迟、吞吐量、堆内存),结合日志追踪(如SkyWalking)。
主流分布式消息服务对比
| 产品 | 核心特点 | 适用场景 |
|---|---|---|
| Apache Kafka | 高吞吐、持久化日志、水平扩展,适合大数据流处理。 | 日志收集、实时分析、CDC |
| RocketMQ | 阿里开源,支持事务消息、顺序消息,兼容多种协议(HTTP/TCP/MQTT)。 | 电商、金融、物联网 |
| RabbitMQ | AMQP协议支持复杂路由、消息确认机制,易于开发。 | 小型系统、RPC通信 |
| AWS SQS | 全托管服务,无缝集成AWS生态,支持标准队列和FIFO队列。 | 云原生应用、无服务器架构 |
FAQs
Q1:为什么需要分布式消息服务?
A1:分布式消息服务通过异步解耦、流量削峰和可靠性保障,解决以下问题:
- 性能瓶颈:避免上下游服务直接耦合导致的响应延迟。
- 故障隔离:某服务宕机时,消息仍可暂存,不影响整体系统。
- 弹性扩展:应对突发流量(如瞬秒活动)时,通过队列缓冲平缓压力。
Q2:分布式消息服务与数据库的区别是什么?
A2:两者定位不同:
- 数据库:用于持久化存储结构化数据,支持事务与复杂查询。
- 消息服务:侧重于异步传递数据,强调高吞吐、低延迟和临时存储。
- 关键差异:
- 数据库追求ACID特性,消息服务更关注最终一致性(Eventually Consistency)。
- 数据库通常用于状态存储,而