上一篇
分布式消息系统体验
分布式消息系统通过异步解耦提升响应,削峰填谷平衡负载,多节点保障高可用,水平扩展灵活适配业务增长,显著增强
分布式消息系统体验:从理论到实践的深度解析
分布式消息系统的核心概念与价值
分布式消息系统是现代分布式架构中不可或缺的组件,其核心目标是解决异步通信、流量削峰、服务解耦等问题,通过消息队列(Message Queue)作为中间代理,生产者(Producer)和消费者(Consumer)无需直接耦合,实现了系统的松耦合设计,以下是其关键特性与价值:
| 特性 | 价值 |
|---|---|
| 异步通信 | 提升系统响应速度,避免同步调用的阻塞 |
| 流量削峰 | 平滑突发流量,防止后端服务被压垮 |
| 服务解耦 | 隔离上下游依赖,支持独立扩展与维护 |
| 可靠性保障 | 通过持久化、重试机制确保消息不丢失(取决于实现) |
| 顺序性保证 | 支持严格的消息消费顺序(如Kafka分区) |
| 多语言支持 | 兼容不同技术栈(如Java、Python、Go等) |
主流分布式消息系统的技术对比
在实际体验中,不同消息系统的适用场景差异显著,以下是主流方案的对比:

| 系统 | 架构特点 | 适用场景 | 关键限制 |
|---|---|---|---|
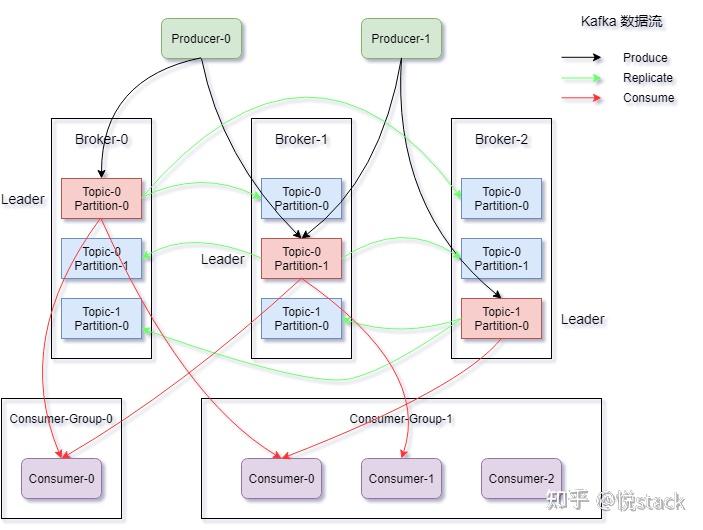
| Kafka | 高吞吐量、分区机制、日志存储 | 大数据实时处理、日志采集、高并发场景 | 延迟较高,运维复杂 |
| RabbitMQ | 交换器(Exchange)模式、灵活路由 | 复杂业务逻辑、动态路由、RPC场景 | 性能受限于Erlang语言 |
| RocketMQ | 阿里系开源、高可靠、低延迟 | 电商订单、金融交易、大促场景 | 生态依赖较强,学习成本较高 |
| Pulsar | 云原生设计、多租户隔离 | 混合云部署、全球化场景 | 社区成熟度低于Kafka |
实际应用场景与体验分析
电商订单处理流程
在电商系统中,分布式消息系统常用于订单状态流转。
- 流程:用户下单 → 订单服务写入数据库 → 发送消息到MQ → 库存服务、支付服务、物流服务异步消费。
- 体验:
- 优势:订单服务快速返回,避免用户等待;各服务独立扩展(如大促时扩容库存服务)。
- 挑战:消息积压导致延迟(需监控Broker负载)、幂等性处理(如重复消费扣减库存)。
金融交易数据同步
金融系统对消息可靠性要求极高:
- 需求:交易数据必须零丢失,且严格顺序消费。
- 实践:
- 使用Kafka的Exactly Once语义(EOS),配合事务消息。
- 采用分区键(如交易ID)保证顺序性。
- 体验:配置复杂度高,但能确保数据一致性。
物联网设备数据收集
物联网场景中,设备数据高频上报:
- 痛点:海量设备并发写入,需支持高吞吐和持久化。
- 方案:使用Kafka的分区扩展能力,结合时间戳排序。
- 效果:每秒百万级消息处理,支持离线分析与实时告警。
常见问题与优化策略
消息积压处理
| 原因 | 解决方案 |
|---|---|
| 消费者消费速度不足 | 增加消费者实例数(水平扩展)或优化消费逻辑 |
| Broker性能瓶颈 | 升级硬件、拆分Topic分区或启用多Broker集群 |
| 消息峰值突增 | 开启流量削峰(如限流算法)或动态扩容 |
消息丢失与重复消费
- 可靠性保障:
- 开启可靠投递(如ACK确认机制)。
- 使用同步刷盘(SYNC_FLUSH)保证持久化。
- 幂等性设计:
- 消费者端生成唯一消息ID,结合数据库乐观锁去重。
- 业务层实现接口幂等(如支付回调的防重机制)。
典型错误与避坑指南
- 过度依赖消息系统:
- 错误:将所有服务间调用改为异步消息,导致调试困难。
- 建议:仅对高并发、非实时场景使用异步化。
- 忽略消息顺序性:
- 错误:订单相关操作未绑定分区键,导致消费顺序混乱。
- 建议:通过消息属性(如Kafka的Key)或业务字段保证分区。
- 未监控死信队列(DLQ):
- 错误:消费者异常导致消息堆积在DLQ,业务中断。
- 建议:定期清理DLQ并报警,分析消费失败原因。
FAQs
Q1:如何选择消息系统的持久化策略?
A1:根据业务容忍度决定:
- 高可靠场景(如支付):选择SYNC_FLUSH + 三副本存储,牺牲部分性能。
- 高性能场景(如日志采集):使用异步刷盘(ACK_FLUSH),但需承担宕机丢消息风险。
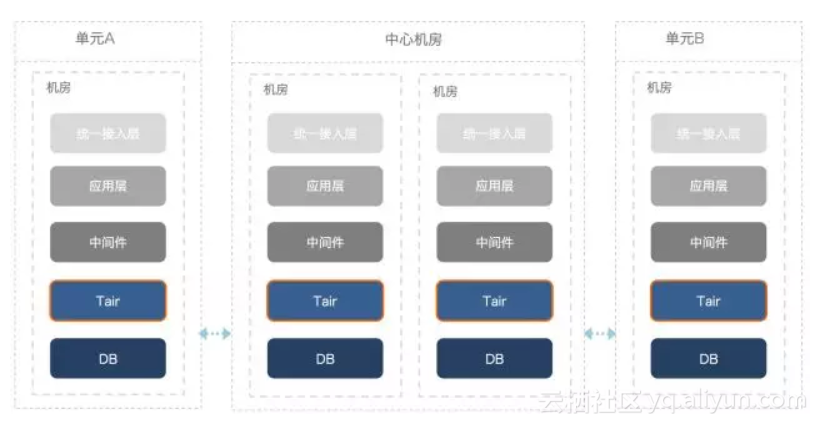
Q2:消息系统如何支持全球多活架构?
A2:关键设计包括:
- 多中心部署:在不同地域部署Broker集群,数据同步采用跨区复制(如Kafka的MirrorMaker)。
- 分区策略:按地域或业务划分分区,避免跨区依赖。
- 故障转移:配置跨可用区负载均衡,主中心故障时自动切换。