上一篇
分布式消息服务怎么用
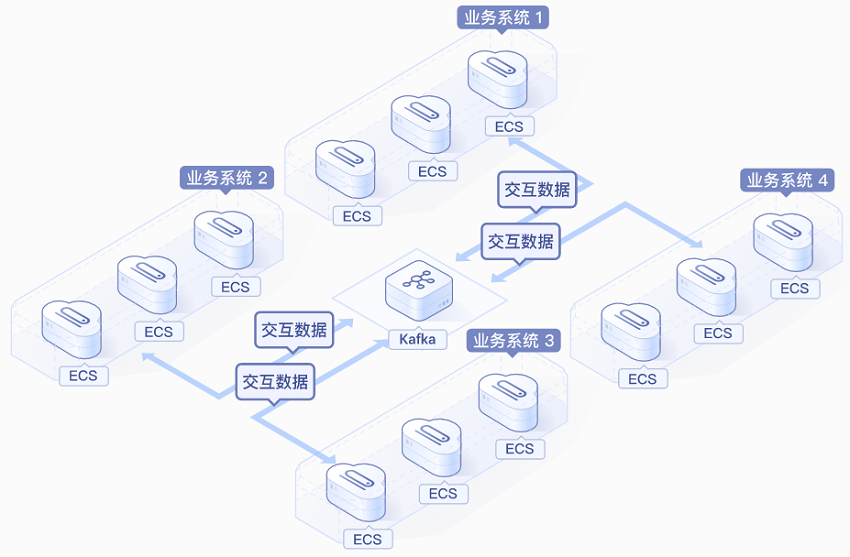
分布式消息服务通过队列实现异步通信,生产者发送消息至队列,消费者订阅处理,需配置集群保障高可用,结合业务设计消息格式,监控吞吐量与延迟
分布式消息服务的核心概念
分布式消息服务(Distributed Message Service)是一种基于消息队列的中间件技术,用于解耦系统、异步处理任务和缓冲流量,其核心组件包括:
- Producer(生产者):负责发送消息到消息队列。
- Consumer(消费者):从消息队列中读取并处理消息。
- Broker(代理):作为消息中转站,负责存储和转发消息。
- Topic/Queue(主题/队列):消息的逻辑分类或存储通道。
关键特性
| 特性 | 说明 |
|---|---|
| 解耦与异步 | 生产者无需等待消费者处理完成,提升系统吞吐量。 |
| 消息持久化 | 支持将消息存储到磁盘,防止因宕机导致数据丢失。 |
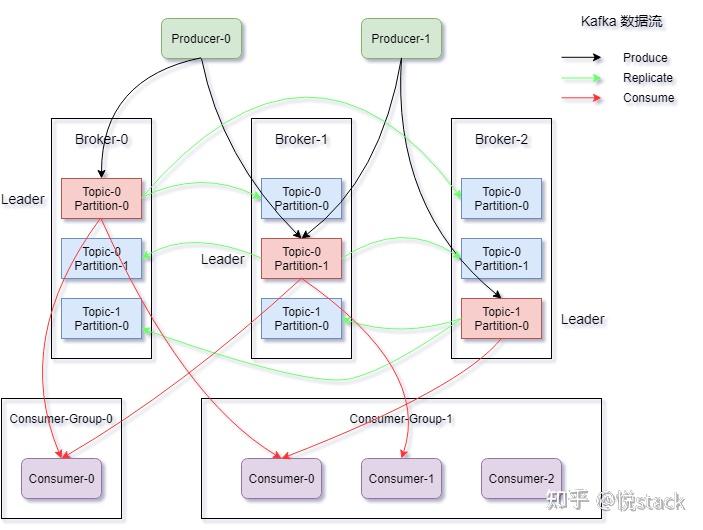
| 负载均衡 | 通过分区(Partition)实现多消费者并行消费,自动分配消息。 |
| 可靠性保障 | 通过确认机制(ACK)、重试策略和死信队列(DLQ)处理失败消息。 |
| 顺序性支持 | 部分场景需严格保证消息顺序(如订单处理),可通过顺序消息或分区实现。 |
分布式消息服务的使用方法
环境准备与选型
根据业务需求选择适合的消息服务,主流产品对比如下:
| 产品名称 | 协议支持 | 适用场景 | 特点 |
|---|---|---|---|
| Apache Kafka | 自有协议(基于TCP) | 高吞吐量日志采集、实时流处理 | 高吞吐、水平扩展强,适合大规模数据流。 |
| RabbitMQ | AMQP | 复杂路由、事务场景 | 支持多种交换模式(Fanout、Direct、Topic),适合企业级应用。 |
| AWS SQS | HTTP/HTTPS | 云端异步任务 | 全托管服务,与AWS生态集成,适合快速构建云端应用。 |
| RocketMQ | 自定义协议(类似Kafka) | 电商订单、金融级交易 | 低延迟、高可靠,支持亿级消息堆积,国产化适配良好。 |
| Redis Pub/Sub | 内存存储 | 实时性要求高的轻量场景 | 低延迟但无持久化,适合临时通知或状态同步。 |
基础使用步骤
以 Kafka 为例,演示消息服务的典型使用流程:

步骤1:搭建集群
- 部署Kafka Broker集群(至少3个节点保证高可用)。
- 创建Topic(如
order-topic),设置分区数(如3个分区)和副本因子(如2个副本)。
步骤2:生产者发送消息
// Java示例:发送订单消息
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.JsonSerializer");
KafkaProducer<String, Order> producer = new KafkaProducer<>(props);
Order order = new Order(1001, "userA", 500.0);
producer.send(new ProducerRecord<>("order-topic", order.getId().toString(), order));
producer.close();步骤3:消费者处理消息
# Python示例:消费订单消息
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
'order-topic',
bootstrap_servers=['kafka-broker1:9092'],
group_id='order-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
for message in consumer:
order = message.value
print(f"Processing order {order['id']} for user {order['user']}")
# 模拟业务处理逻辑步骤4:消息确认与偏移量管理
- 消费者处理完成后需发送ACK,Kafka通过偏移量(Offset)记录消费位置。
- 可配置自动提交偏移量或手动控制(如事务场景)。
消息管理与维护
| 操作 | 说明 |
|---|---|
| 消息过滤 | 通过Kafka的Partition或RabbitMQ的Routing Key实现精准消费。 |
| 死信队列(DLQ) | 处理消费失败的消息,避免无限重试导致阻塞。 |
| 消息回溯 | Kafka支持按时间或偏移量重置消费位点,用于数据重放或纠错。 |
| 监控与告警 | 监控关键指标(如TPS、延迟、堆积量),通过Prometheus+Grafana可视化。 |
典型应用场景与实践
场景1:电商订单异步处理
- 问题:用户下单后需调用库存、支付、物流等多个服务,同步调用耗时长。
- 解决方案:
- 订单服务将消息写入
order-topic。 - 库存服务、支付服务作为消费者订阅该Topic,并行处理。
- 通过消息确认机制保证处理成功,失败则转入DLQ人工干预。
- 订单服务将消息写入
场景2:日志收集与实时分析
- 问题:服务器日志分散在多个节点,需集中存储并分析。
- 解决方案:
- 各服务器通过Flume或Logstash将日志推送至Kafka的
log-topic。 - 消费者(如Spark Streaming)实时计算日志中的关键字统计、错误率等。
- 存储至HDFS或Elasticsearch供后续查询。
- 各服务器通过Flume或Logstash将日志推送至Kafka的
场景3:流量削峰与限流
- 问题:瞬秒活动突发流量可能导致数据库崩溃。
- 解决方案:
- 前端将请求写入
request-queue(如RabbitMQ)。 - 后端按固定速率消费消息,平滑处理峰值流量。
- 结合Redis实现限流(如限制每秒最多1000个请求)。
- 前端将请求写入
高级功能与优化策略
消息顺序性保障
- 问题:订单处理需严格保证消息顺序(如支付后发货)。
- 方案:
- Kafka:启用
enable_auto_commit=false,按消息Key分配分区(同一订单的Key相同)。 - RabbitMQ:使用
Direct Exchange绑定相同Routing Key,确保消息按顺序到达。
- Kafka:启用
消息积压处理
- 原因:突发流量、消费者处理速度慢或Broker故障。
- 解决方案:
- 横向扩容:增加Consumer实例或分区数。
- 优化处理逻辑:批量消费、并行处理。
- 丢弃策略:对非关键消息设置过期时间(TTL)。
事务与可靠性
- 事务消息:支持“恰好一次”投递(如RocketMQ的事务消息)。
- 幂等性设计:消费者端需对重复消息去重(如基于唯一ID检测)。
- 持久化配置:开启可靠投递(Reliable Delivery),避免因宕机丢失数据。
常见问题与监控运维
FAQs:
Q1:如何选择消息队列的协议(AMQP/HTTP/MQTT)?
A1:
- AMQP(RabbitMQ):适合复杂路由、事务和多语言支持。
- HTTP/REST(AWS SQS):便于云端集成,但性能较低。
- MQTT(物联网场景):轻量级,适合低带宽、高延迟环境(如传感器数据传输)。
Q2:消息积压严重时如何处理?
A2:
- 扩容Consumer:增加消费者实例数,提高处理能力。
- 拆分Topic:按业务维度(如按用户ID哈希)划分子Topic,分散压力。
- 优化消息体:压缩消息大小,减少网络传输耗时。
- 限流或延迟处理:对非核心消息设置延迟队列,优先处理关键任务。
归纳与最佳实践
- 按需选择产品:根据场景需求(如吞吐量、延迟、成本)选择Kafka、RabbitMQ或云服务。
- 设计高可用架构:部署多Broker集群,开启数据副本和自动故障转移。
- 监控与告警:关注TPS、延迟、堆积量等指标,设置阈值告警。
- 合理规划资源:避免过度扩容,根据业务峰值