上一篇
分布式消息系统创建
分布式消息系统创建需设计消息队列模型,搭建Broker集群实现高可用,通过生产者/消费者模式解耦服务,采用分区存储与副本复制保障数据可靠性,结合负载均衡提升吞吐量,最终实现异步通信与流量削峰
分布式消息系统创建指南
核心概念与架构设计
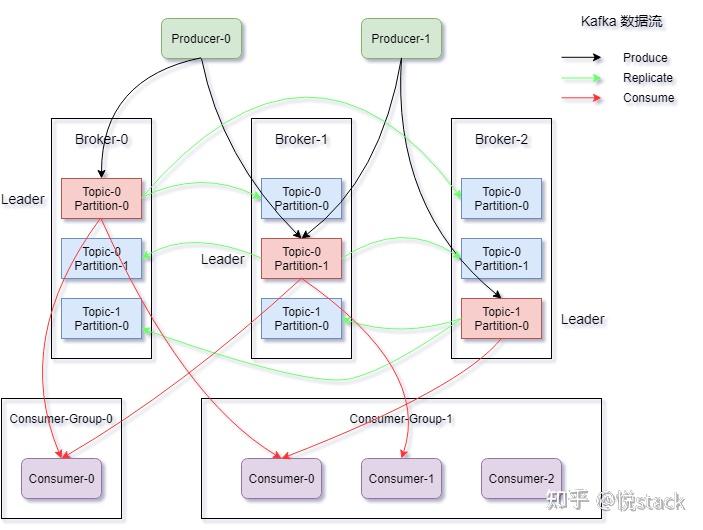
分布式消息系统是解耦异步通信、平衡负载、保障数据一致性的关键基础设施,其核心架构包含以下角色:

| 组件 | 功能描述 |
|---|---|
| Producer | 消息生产者,负责发送消息至系统 |
| Consumer | 消息消费者,订阅并处理消息 |
| Broker | 消息中间件,负责存储转发、权限管理、消息路由 |
| 协调节点 | 管理元数据(如Kafka的ZooKeeper/Kafka自身协调) |
| 存储层 | 持久化消息数据(磁盘/内存),需支持高吞吐写入与顺序读取 |
典型架构模式分为两种:
- 队列模型:单消费者独占消息(FIFO),适用于任务分配场景
- 发布订阅模型:多消费者共享消息,适用于事件广播场景
关键设计要素
高可用性设计
- 多Broker集群:通过主从架构实现故障转移,典型副本数≥3
- 数据分片策略:
- 哈希分片:按Key均匀分布(保证顺序性)
- 范围分片:按时间/ID分段(适合流式处理)
- CAP定理权衡:
- AP模式(如Kafka):允许短暂分区不可用,优先可用性
- CP模式(如Raft协议):强一致性但可用性受限
扩展性设计
| 维度 | 实现方案 |
|---|---|
| 纵向扩展 | 单机优化:零拷贝技术、内存映射文件(如Kafka的PageCache机制) |
| 横向扩展 | 增加Broker节点,动态扩展Topic分区(需重新平衡数据) |
| 客户端扩展 | 消费者组自动负载均衡(如Kafka的Rebalance机制) |
可靠性保障
- 消息持久化:同步刷盘(SYNC_FLUSH) vs 异步刷盘(异步性能高但存在丢失风险)
- ACK机制:
- At-least-once:允许重复消费(需业务层去重)
- Exactly-once:事务消息(如RocketMQ事务消息)
- 死信队列:处理消费失败消息,支持延迟重试或人工干预
主流技术选型对比
| 特性 | Apache Kafka | RabbitMQ | RocketMQ | Apache Pulsar |
|---|---|---|---|---|
| 最佳场景 | 高吞吐日志采集 | 复杂路由场景 | 金融级事务消息 | 多租户云原生 |
| 消息模型 | 发布订阅+队列 | 全支持 | 全支持 | 全支持 |
| 一致性保障 | 分区内强有序 | 镜像队列强一致 | 全局顺序消息 | 跨集群一致性 |
| 存储机制 | 时间窗口分段存储 | 队列镜像 | 可靠投递+回溯 | BookKeeper |
| 协议支持 | 自有二进制协议 | AMQP 1.0/STOMP | 自定义协议 | HTTP/TLS |
创建实施步骤
需求分析阶段
- 业务指标:
- 峰值TPS(如电商促销时50万条/秒)
- 消息延迟要求(实时场景<100ms,日志收集<1s)
- 存储周期(冷数据保留7天/热数据保留1年)
- 功能需求:
- 是否需要事务消息(如订单系统)
- 是否要求消息顺序性(如数据库变更日志)
- 是否需要多语言SDK支持
架构设计阶段
- 拓扑结构:
- 3+ Broker节点部署(跨AZ/机房)
- 独立ZooKeeper集群(Kafka)或内置协调服务(Pulsar)
- 容量规划:
- 磁盘空间 = 日增量 × 保留天数 × 副本数
- JVM堆内存 = Broker内存 × 80%(避免GC频繁)
- 网络规划:
- 客户端与Broker长连接保活(心跳间隔<30s)
- 跨数据中心带宽≥50Mbps(同步复制场景)
技术实施阶段
(1) 环境准备
# Kafka示例(3节点集群) # 安装JDK8+ yum install java-1.8.0-openjdk -y # 下载Kafka wget https://archive.apache.org/dist/kafka/2.8.0/kafka_2.13-2.8.0.tgz # 配置server.properties broker.id=1 # 依次设置为1/2/3 log.dirs=/data/kafka/logs zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
(2) 核心配置项
| 参数 | 说明 | 推荐值 |
|---|---|---|
num.partitions | Topic初始分区数 | 根据业务并行度设置 |
replication.factor | 副本数量 | ≥3(生产环境) |
auto.create.topics | 自动创建Topic策略 | 设为false,显式创建 |
log.retention | 日志保留策略 | 基于大小+时间组合 |
unclean.leader.election | 禁用非ISR副本选举 | false(保障数据完整性) |
(3) 客户端开发规范
- Producer端:
- 批量发送(batch.size=16KB)
- 压缩算法选择LZ4(平衡压缩率与性能)
- Consumer端:
- 启用自动提交偏移量(enable.auto.commit=true)
- 设置合理消费位移(EARLIEST/LATEST/TIMESTAMP)
- 消息体规范:
- 固定消息头(包含traceId/业务标识)
- 序列化格式(Avro/Protobuf优于JSON)
运维监控体系
核心监控指标
| 指标类别 | 关键指标 |
|---|---|
| Broker层 | CPU使用率/JVM堆内存/磁盘IO/网络带宽 |
| 消息流转 | TPS/消息延迟(P99/P999)/重试次数/死信队列堆积量 |
| 存储层 | 日志段大小/索引文件大小/磁盘剩余空间 |
| 协调服务 | ZooKeeper会话超时/节点负载/提案处理延迟 |
应急处理方案
- Broker宕机:触发自动故障转移,消费者切换连接
- 消息积压:
- 短期:扩容Consumer实例数
- 长期:增加Topic分区并重新平衡数据
- 脑裂问题:启用仲裁机制(如Kafka的unclean.leader.election=false)
性能优化策略
- JVM调优:
- G1垃圾回收器(-XX:+UseG1GC)
- 年轻代占比≥60%(-Xmn6g -Xmx10g)
- 操作系统优化:
- 关闭TCP延迟确认(net.ipv4.tcp_no_delay=1)
- 文件句柄数限制(ulimit -n 65536)
- 存储优化:
- RAID10阵列(兼顾性能与可靠性)
- DISK满时触发滚动升级(避免业务中断)
FAQs
Q1:如何选择消息队列模型(队列/发布订阅)?
A:若需要严格的消息顺序性和独占消费(如订单处理),选择队列模型;若需要多消费者并行处理且不敏感顺序(如日志收集),选择发布订阅模型,可通过测试不同模型下的消费者并发能力(如Kafka的consumer group rebalance表现)进行验证。
Q2:如何彻底解决消息丢失问题?
A:需从三个层面保障:
- Broker层:开启同步刷盘(acks=all)并配置3+副本
- Producer端:启用可靠投递(retries>0,linger.ms>0)
- 业务层:实现幂等接口(如基于唯一消息ID去重)或采用事务消息(如RocketMQ的半事务