上一篇
分布式消息服务
分布式消息服务通过异步解耦实现系统间高效通信,支持消息持久化与可靠投递,具备高吞吐、弹性扩展能力,有效缓解峰值压力并提升容错性,适用于微 服务架构的流量削峰与数据异步
分布式消息服务:核心概念与技术解析
分布式消息服务的定义与价值
分布式消息服务(Distributed Message Service)是一种基于消息队列的中间件技术,用于解耦系统间的实时通信与异步处理,其核心目标是通过消息的存储与转发,实现不同服务之间的可靠数据传输,同时提升系统的可扩展性、容错性和响应效率,以下是其核心价值:
| 核心价值 | 具体表现 |
|---|---|
| 解耦 | 发送方与接收方无需直接依赖,支持独立扩展与维护 |
| 削峰填谷 | 缓冲突发流量,避免后端服务因瞬时高负载而崩溃 |
| 可靠性 | 通过持久化、重试机制保证消息不丢失 |
| 异步处理 | 提升系统吞吐量,减少响应延迟 |
| 多语言支持 | 兼容不同编程语言的客户端,适应异构技术栈 |
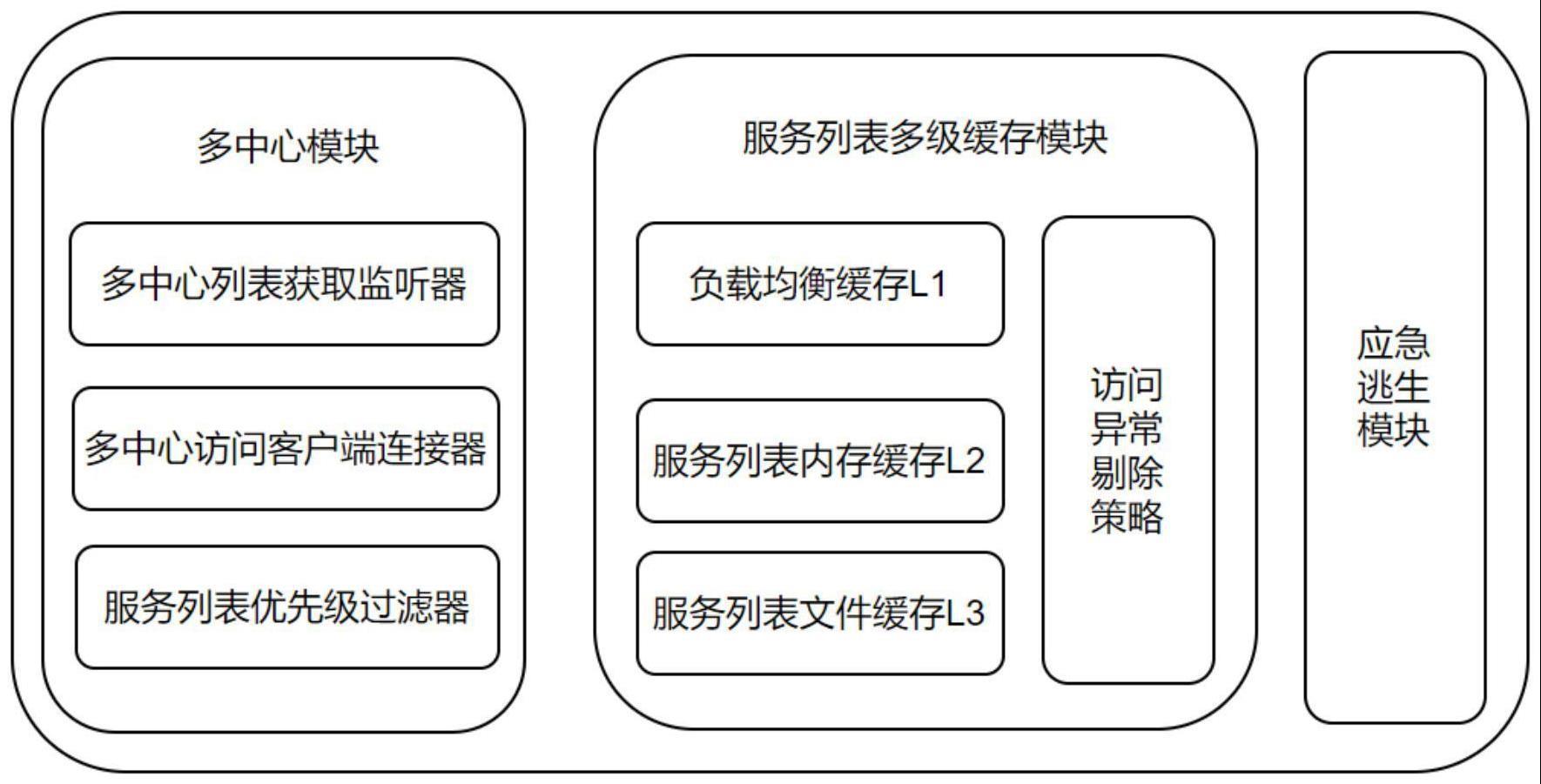
核心组件与架构设计
分布式消息服务的典型架构包含以下关键组件:
Producer(生产者)

- 负责生成消息并发送到消息队列
- 支持消息的分组、标签、优先级设置
- 需处理消息发送失败的重试逻辑
Broker(消息代理)
- 核心组件,负责消息的存储、路由与转发
- 支持集群部署以实现高可用性
- 提供消息持久化(磁盘/内存)与索引加速
Consumer(消费者)
- 订阅消息队列并处理消息
- 支持自动偏移量管理(消费进度跟踪)
- 需实现消息确认(ACK)机制以避免重复消费
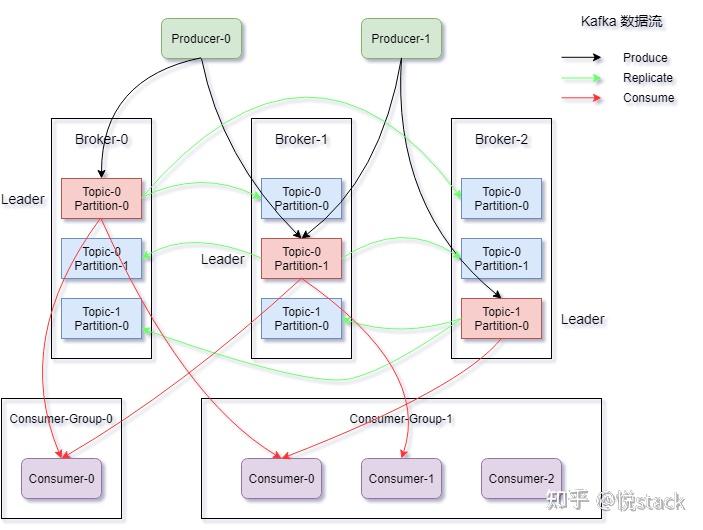
Topic(主题)与Partition(分区)
- Topic:逻辑上的消息分类,用于区分不同业务场景
- Partition:物理上的分区,支持水平扩展与并行处理
- 典型设计:每个Topic包含多个Partition,分散存储于不同Broker节点
架构分层示例:
[Producer] → [Load Balancer] → [Broker Cluster] → [Consumer Group]- 负载均衡层:分发Producer请求至Broker集群
- Broker集群:采用主从架构或一致性哈希实现高可用
- 消费者组:多个Consumer实例共享一个Topic,实现负载均衡
关键技术与实现机制
消息模型
| 模型类型 | 特点 | 适用场景 |
|---|---|---|
| 点对点模型 | 单消费者独占队列,消息被消费后即删除 | 任务分配、RPC响应 |
| 发布/订阅模型 | 多消费者共享主题,消息广播至所有订阅者 | 事件通知、日志收集 |
| 流处理模型 | 无限消息存储,支持时间窗口与状态管理 | 实时数据分析、监控告警 |
可靠性保障
- 消息持久化:将消息写入磁盘(如WAL日志)防止宕机丢失
- ACK机制:Consumer处理完成后发送确认,超时则重新投递
- 幂等性设计:确保重复消费不会产生副作用(如支付场景需去重)
- 死信队列(DLQ):存储消费失败的消息,支持后续人工干预
高可用性设计
- 多副本存储:每个Partition复制多份(如3副本),通过Raft协议选举主节点
- 故障转移:主节点故障时自动切换至备节点,保证服务无中断
- 动态扩容:支持在线添加Broker节点,通过哈希分配重新平衡Partition
性能优化
- 批量处理:合并小消息为批次发送,减少网络开销
- 压缩技术:采用Snappy、LZ4等算法压缩消息体,降低传输带宽
- 零拷贝技术:避免CPU参与数据拷贝,直接通过DMA传输
- 长轮询模式:Consumer阻塞式拉取消息,减少空轮询的浪费
典型应用场景与案例
电商订单处理
- 场景:用户下单后,订单服务将消息写入队列,库存、支付、物流服务异步消费
- 优势:避免订单服务因库存扣减延迟而阻塞,提升用户体验
日志收集与分析
- 场景:分布式系统将日志写入消息队列,日志服务统一消费并存储至Elasticsearch
- 优势:缓解日志峰值压力,支持实时监控与历史检索
微服务间通信
- 场景:服务A调用服务B后,通过消息队列传递调用结果,而非同步等待
- 优势:降低服务间耦合度,支持跨语言、跨协议的灵活集成
挑战与解决方案
消息积压问题
- 原因:突发流量、Consumer消费速度不足、磁盘IO瓶颈
- 解决方案:
- 横向扩展Consumer实例数
- 优化消息大小与频率,采用压缩算法
- 动态调整消息优先级,优先处理关键任务
消息顺序性保障
- 问题:某些场景(如订单处理)要求严格的消息顺序
- 实现方式:
- 分区顺序:按用户ID哈希分区,保证同一用户的订单按顺序消费
- 全局顺序:引入单调递增的消息ID,但牺牲并发性能
一致性与事务支持
- 挑战:分布式环境下如何保证消息投递与业务操作的原子性
- 方案:
- 本地事务消息:将消息发送与数据库操作纳入同一事务
- 事务消息:支持Prepare/Commit两阶段提交,确保消息与业务状态一致
主流产品对比与选择建议
| 产品 | 核心特点 | 适用场景 |
|---|---|---|
| Apache Kafka | 高吞吐量、持久化日志、流处理支持 | 大数据日志、实时分析 |
| RabbitMQ | 灵活路由、镜像队列、插件生态 | RPC、复杂路由场景 |
| RocketMQ | 低延迟、高并发、阿里系开源 | 电商订单、瞬秒活动 |
| AWS SQS | 全托管服务、无缝集成AWS生态 | 云原生应用、快速上手 |
选择建议:
- 高吞吐场景优先Kafka,复杂路由选RabbitMQ,低延迟考虑RocketMQ
- 云环境推荐SQS或Kafka on Cloud(如Azure Event Hubs)
FAQs:分布式消息服务常见问题解答
Q1:如何判断消息队列的长度是否合理?
A1:需结合业务特点与系统承载能力:
- 短队列(<1万):适合实时性要求高的场景(如交易指令),但需确保Consumer处理能力足够。
- 长队列(>10万):适用于日志、监控等允许一定延迟的场景,可通过监控Consumer的TPS(每秒处理数)与队列长度的比值动态调整,若队列持续增长,需排查Consumer性能或扩容。
Q2:自建消息队列与云服务消息队列如何选择?
A2:对比维度与上文归纳:
| 对比维度 | 自建消息队列 | 云服务消息队列 |
|——————–|————————————–|———————————-|
| 成本 | 硬件采购+运维人力成本高 | 按需付费,初期成本低 |
| 灵活性 | 可深度定制,但需自主维护 | 标准化功能,快速集成 |
| 扩展性 | 受硬件资源限制,扩容周期长 | 弹性扩展,秒级生效 |
| 高可用性 | 需自行搭建多AZ架构,复杂度高 | 默认多可用区容灾,SLA保障 |
:中小型企业或原型验证阶段推荐云服务;超大规模企业或特殊定制需求可选择自建,但需评估