上一篇
hadoop数据仓库体系结构
Hadoop数据仓库体系以HDFS为核心存储,通过Sqoop采集多源数据,经MapReduce/Spark完成ETL清洗转换,Hive/Impala提供SQL查询接口,Yarn资源调度保障高并发,最终实现TB-PB级数据的高效存储与OL
Hadoop数据仓库体系结构是一种基于分布式计算框架构建的海量数据存储与分析解决方案,其核心目标是通过低成本、高扩展性的架构实现PB级数据的高效处理,以下从核心组件、架构层次、工作流程及技术特性等方面展开详细说明。
核心组件与功能
| 组件名称 | 功能描述 | 技术特点 |
|---|---|---|
| HDFS | 分布式文件系统,提供高容错的数据存储能力 | 主从架构(NameNode+DataNode)、数据块冗余存储(默认3副本)、支持流式数据写入 |
| MapReduce | 分布式计算模型,用于批量数据处理 | 分治思想(Map+Reduce)、任务调度、数据本地化计算优化 |
| YARN | 资源调度框架,负责集群资源管理和任务调度 | 分离资源管理(ResourceManager)与任务执行(NodeManager),支持多租户 |
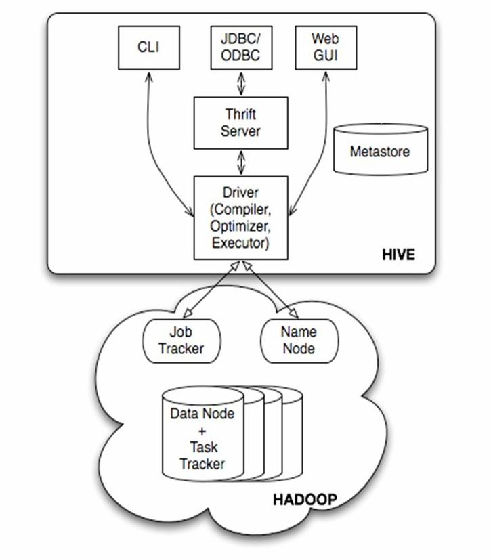
| Hive | 数据仓库工具,提供SQL-like查询接口 | 基于HDFS存储、支持分区/桶排序、元数据管理(MetaStore) |
| HBase | 分布式NoSQL数据库,支持实时读写 | 列式存储、LSM树结构、支持高并发随机读写 |
| Sqoop | 数据导入导出工具,连接关系型数据库与HDFS | 支持增量导入、并行传输、任务断点续传 |
| Oozie/Airflow | 工作流调度工具,管理复杂数据处理任务依赖 | 定时调度、DAG任务编排、事件驱动触发 |
架构层次划分
Hadoop数据仓库采用分层架构设计,各层职责明确,典型分层如下:
数据源层
- 包含业务数据库(MySQL/Oracle)、日志文件、传感器数据等原始数据
- 通过Flume、Kafka、Sqoop等工具实现数据采集
ETL处理层
- Extract:使用Sqoop从关系库抽取数据,Flume收集日志流
- Transform:通过MapReduce/Spark完成数据清洗、转换、聚合
- Load:将处理后数据存入HDFS或HBase
数据存储层
- 热数据存储:HBase用于低延迟随机读写(如用户画像更新)
- 冷数据存储:HDFS存储历史归档数据,采用Parquet/ORC列式格式优化查询
- 元数据管理:Hive MetaStore维护表结构、分区等元信息
数据分析层
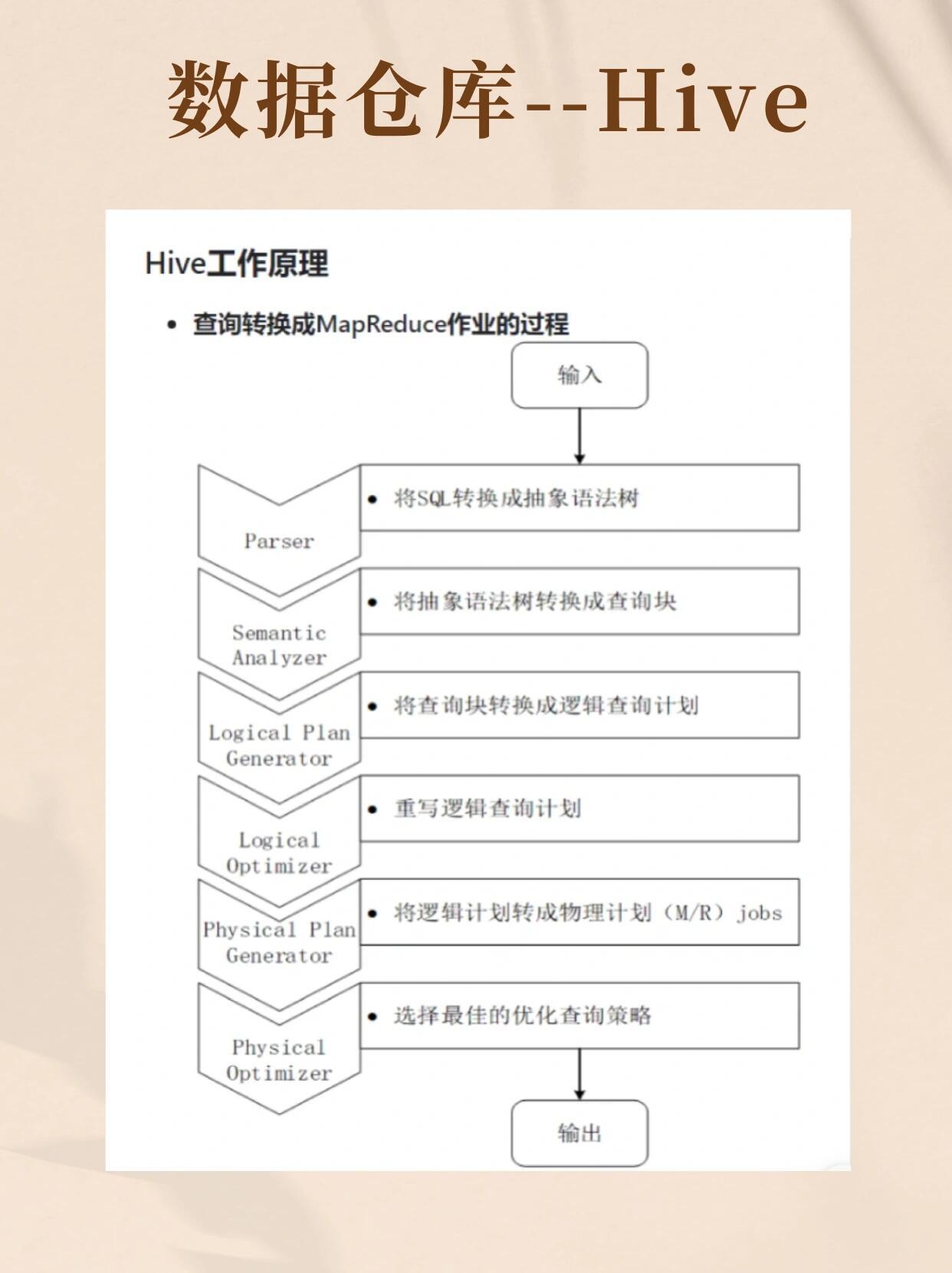
- 离线分析:Hive执行SQL查询,底层调用MapReduce/Tez引擎
- 实时分析:Impala/Presto提供MPP查询加速,HBase+Phoenix支持实时OLAP
- 数据挖掘:Spark MLlib进行机器学习建模
应用服务层
- BI工具(Tableau/PowerBI)连接Hive/Impala获取可视化报表
- API网关对外提供数据服务接口(RESTful API)
典型工作流程
以电商用户行为分析为例,数据处理流程如下:
数据采集
- Flume采集用户浏览日志,Kafka接收实时点击事件
- Sqoop每日增量同步订单数据库到HDFS
数据清洗
- MapReduce任务过滤无效日志(如缺失用户ID的记录)
- 基于时间戳进行数据去重,按小时粒度生成清洁数据集
数据存储
- 热数据(最近7天行为)存入HBase,按用户ID建立RowKey
- 历史数据按日期分区存储为Hive表,采用ORC压缩格式
分析计算
- Hive SQL统计每日UV/PV:
SELECT count(DISTINCT user_id) FROM logs WHERE date='2023-10-01' - Spark Streaming实时计算用户留存率,结果写入Redis缓存
- Hive SQL统计每日UV/PV:
结果输出
- BI系统定期生成《用户活跃度分析报告》
- API接口返回用户最近30天消费总额
技术优势与挑战
优势
| 维度 | 传统数仓(如Teradata) | Hadoop数仓 |
|---|---|---|
| 扩展性 | 垂直扩展(硬件上限) | 水平扩展(添加节点即可) |
| 成本 | 高昂专有硬件 | 廉价PC服务器集群 |
| 灵活性 | 结构化数据专用 | 支持非结构化/半结构化数据 |
| 吞吐量 | 千级/秒查询 | 万级/秒批量处理 |
挑战
性能调优复杂
- 需优化HDFS块大小、MapReduce任务拆分粒度
- 数据倾斜可能导致部分节点成为瓶颈
数据一致性保障
- HDFS最终一致性模型不适合强事务场景
- HBase需通过版本控制解决读写冲突
运维难度较高
- 数百节点集群需监控JVM内存、磁盘IO等指标
- YARN资源调度策略需根据业务负载动态调整
FAQs
Q1:Hadoop数据仓库与传统数仓的本质区别是什么?
A1:传统数仓(如Greenplum)采用共享存储架构,依赖高端硬件实现性能;Hadoop采用分布式存储+计算分离架构,通过廉价PC服务器集群实现横向扩展,前者适合ACID事务型分析,后者擅长海量非结构化数据处理。
Q2:如何提升Hadoop数仓的查询响应速度?
A2:可采取以下优化措施:
- 存储优化:使用Parquet列式存储减少IO,开启Snappy/Zlib压缩
- 索引加速:Hive创建BloomFilter索引过滤无效分区
- 计算优化:启用Tez替代MapReduce,配置CBO(成本基优化器)
- 缓存机制:利用Hive缓存元数据,配置Redis