上一篇
Hadoop数据仓库ETL
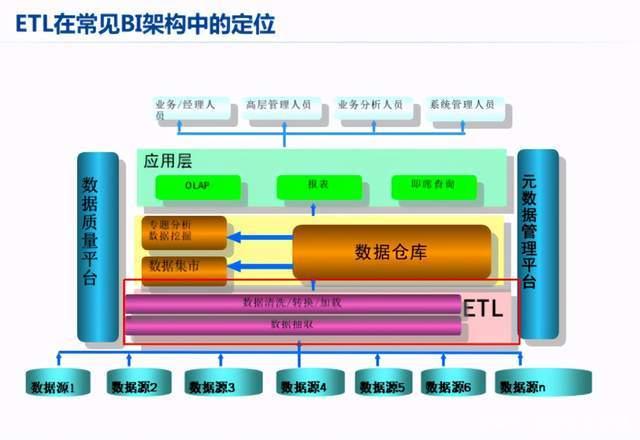
Hadoop数据仓库ETL通过Sqoop抽取数据,利用MapReduce/Hive进行清洗转换,结合HDFS分布式存储,实现TB/PB级数据高效加载与分析,支撑企业级数据
Hadoop数据仓库ETL:核心流程与技术实践
Hadoop数据仓库ETL
Hadoop作为分布式存储与计算框架,为数据仓库ETL(Extract, Transform, Load)提供了高扩展性和低成本的解决方案,其核心优势在于处理海量非结构化/半结构化数据的能力,结合HDFS、MapReduce、YARN等组件,可构建从数据采集到分析的完整链路,以下从技术架构、工具链、关键挑战三个维度展开说明。
ETL核心流程与Hadoop技术映射
| 阶段 | 传统数据仓库方式 | Hadoop生态解决方案 | 典型工具 |
|---|---|---|---|
| Extract | SSIS、Informatica | 分布式采集(支持多源异构数据) | Sqoop、Flume、Kafka |
| Transform | PL/SQL、ETL工具脚本 | 分布式计算(批处理/流处理) | Pig、Hive、Spark、Flink |
| Load | INSERT INTO语句 | 高效存储(列式/分区/压缩) | Hive、Impala、Parquet格式 |
数据抽取(Extract)
- 批量抽取:Sqoop支持从RDBMS(如MySQL、Oracle)并行导入数据至HDFS,通过
--split-by参数实现数据分片。 - 实时流式:Flume通过Source-Channel-Sink架构采集日志(如Web访问日志),支持Tail监控文件变化。
- 消息队列集成:Kafka作为缓冲层,实现多系统数据异步传输,配合Kafka Connector完成与Hadoop的对接。
数据转换(Transform)
- 离线计算:Hive QL编写ETL脚本,利用自定义UDF处理复杂逻辑(如JSON解析、时间窗口计算)。
- 内存加速:Spark通过RDD/DataFrame API实现机器学习特征工程,缓存中间结果减少IO开销。
- 流批一体:Flink Checkpoint机制保障状态一致性,支持窗口聚合(如滚动窗口、滑动窗口)处理实时数据。
数据加载(Load)
- 分区策略:Hive按日期(
PARTITIONED BY (dt STRING))或哈希分区(CLUSTERED BY)优化查询性能。 - 存储优化:ORC/Parquet列式存储减少磁盘占用,配合Snappy压缩提升读写效率。
- 索引加速:Hue集成Impala Ad-hoc查询,通过倒排索引快速定位数据。
Hadoop ETL关键技术组件
Sqoop
- 功能:RDBMS与HDFS/Hive间数据传输
- 优化:
--direct模式绕过MapReduce,--query指定增量抽取条件 - 限制:不支持DDL/DML操作,需配合Beeline执行并发任务
Flume

- 架构:Source(如Exec Source监控命令输出)→ Channel(Memory/File)→ Sink(HDFS/Kafka)
- 场景:日志收集(如Nginx Access Log)、设备传感器数据流
- 扩展:Interceptor插件实现数据清洗(如正则过滤、字段截取)
Spark SQL
- 优势:支持JOIN、窗口函数等复杂操作,Cache RDD减少重复计算
- 案例:用户行为宽表构建(设备ID、时间戳、事件类型多表关联)
- 调优:动态分区(
spark.sql.shuffle.partitions)、倾斜数据随机前缀打散
Airflow
- 作用:编排DAG任务依赖(如每日ETL流程:抽取→清洗→聚合→加载)
- 配置:通过BEIGHTER格式定义任务优先级,邮件告警失败任务
- 扩展:集成Livy启动Spark作业,避免YARN资源冲突
典型ETL场景与实现方案
场景1:电商业务数据仓库建设
| 需求 | 实现方案 |
|---|---|
| 全量+增量同步 | Sqoop增量导入订单表(--incremental lastmodified),Flume实时采集支付日志 |
| 用户行为分析 | Spark Streaming处理点击流,Kafka存储事件,Hive存储日粒度聚合结果 |
| 商品画像更新 | Pig脚本清洗评论文本,NLP模型(如Word2Vec)生成标签,HBase存储特征向量 |
场景2:日志数据仓库
- 原始日志:Flume采集Nginx日志至HDFS,按小时分区存储(
/logs/2023-10-01/09/)。 - 清洗转换:Spark解析IP地址(GeoIP库)、统计状态码分布,输出Parquet文件。
- 服务监控:Ganglia监控YARN队列,设置资源池隔离ETL与报表查询任务。
性能优化与常见问题解决
数据倾斜处理
- 原因:Key分布不均(如地域ID集中)导致Reducer负载过高。
- 解决方案:
- Spark:
salt算法添加随机前缀(order_id + random(4)),扩容后再聚合。 - Hive:开启
set hive.groupby.skewindata=true自动优化GROUP BY。
- Spark:
小文件过多问题
- 影响:NameNode内存压力大,Map任务启动耗时。
- 优化方法:
- 合并工具:使用
Hadoop combineTextInputFormat或Sparkcoalesce合并小文件。 - 存储策略:采用SequenceFile/ORC格式,开启Block压缩(
set dfs.block.size=134217728)。
- 合并工具:使用
数据一致性保障
- 方案:
- 事务支持:Hive ACID特性(
set hive.txn.manager=true)保证插入原子性。 - 增量校验:MD5校验Flume传输的文件完整性,Airflow任务依赖检查上游成功状态。
- 事务支持:Hive ACID特性(
Hadoop ETL最佳实践
分层设计
- ODSS(Operational Data Store):存储原始日志与明细数据(如订单、点击流)。
- DWD(Data Warehouse Detail):轻度聚合,保留业务过程信息(如每日用户访问明细)。
- DWS(Data Warehouse Summary):重度聚合,供BI分析(如月活跃用户、GMV趋势)。
元数据管理
- 使用Apache Atlas记录表血缘关系,可视化数据来源与加工逻辑。
- 通过Hive Metastore统一管理表Schema,避免手动同步DDL。
资源隔离
- YARN队列配置:为ETL任务分配专属队列(
capacity=40%),防止与临时查询争抢资源。 - 动态资源调整:Spark Thrift Server设置
spark.dynamicAllocation.enabled=true,按需伸缩Executor。
- YARN队列配置:为ETL任务分配专属队列(
FAQs
Q1:如何在Hadoop ETL中处理实时数据?
A1:可采用Kafka+Flink组合,Kafka作为实时数据通道,Flink通过Watermark机制处理乱序事件,实现窗口计算(如5分钟滚动窗口统计UV),若延迟敏感,可启用Flink Checkpoint间隔缩短至秒级,并配置Exactly-Once语义。
Q2:Hadoop ETL任务执行缓慢如何排查?
A2:分三步定位瓶颈:
- 资源监控:通过Yarn ResourceManager查看各Task内存/CPU使用率,确认是否因资源不足导致超时。
- 执行计划:Hive解释EXPLAIN计划,检查是否全表扫描或未用分区裁剪。
- 数据分布:Spark UI分析Stage耗时,若某Task长时间运行,可能是数据倾斜或Shuffle文件过大,需调整并行度或优化