
上一篇
hadoop和数据仓库
Hadoop通过分布式存储与计算为数据仓库提供底层支撑,结合Hive等工具可构建低成本、高扩展
Hadoop与数据仓库的深度解析
Hadoop技术体系
Hadoop作为开源分布式计算框架,其核心优势在于处理海量非结构化数据的能力,通过HDFS(分布式文件系统)、MapReduce(并行计算模型)和YARN(资源调度系统)三大组件,构建了高可靠、可扩展的大数据基础设施,其生态系统涵盖:
- 存储层:HDFS支持TB/PB级数据块存储,采用3副本机制保障容错
- 计算层:MapReduce实现批处理,Spark提供内存计算加速,Flink支持流批一体
- 管理工具:ZooKeeper协调分布式服务,Oozie/Airflow管理工作流
- 应用接口:Pig提供脚本化数据处理,Hive实现类SQL查询
典型部署架构如下:
| 组件 | 功能 | 典型配置 |
|---|---|---|
| NameNode | 元数据管理 | 冗余部署(HA模式) |
| DataNode | 数据存储 | 千台级集群 |
| ResourceManager | 资源调度 | YARN架构 |
| NodeManager | 节点监控 | 与DataNode共节点部署 |
| Hive Metastore | 元数据服务 | MySQL/PostgreSQL后端 |
数据仓库技术演进
数据仓库经历了从传统关系型到现代云原生的演变:
传统数仓(Teradata/Netezza):
- 架构:MPP(大规模并行处理)架构
- 特性:列式存储、物化视图、复杂查询优化
- 局限:硬件成本高昂(百万级)、扩展性差
云原生数仓(Redshift/Snowflake):
- 存储计算分离:按需弹性扩展
- 多模型支持:关系表+半结构化数据
- 优化方向:向量化执行引擎、智能物化视图
开源数仓(Hive/ClickHouse):
- Hive:基于Hadoop的ETL工具,支持SQL-on-Hadoop
- ClickHouse:列式OLAP数据库,单节点性能达千万QPS
关键特性对比表:
| 特性 | 传统数仓 | 云数仓 | Hadoop数仓(Hive) |
|---|---|---|---|
| 数据模型 | 严格Schema | 灵活Schema | 宽松Schema |
| 扩展方式 | 纵向扩展 | 横向扩展 | 横向扩展 |
| 延迟 | 秒级响应 | 亚秒级响应 | 分钟级响应 |
| 成本 | 硬件昂贵 | 按需付费 | 硬件成本低 |
| 数据更新 | ACID事务支持 | 部分支持 | 最终一致性 |
核心技术差异分析
数据存储机制:
- Hadoop:基于HDFS的块存储,适合非结构化/半结构化数据(日志、JSON、AVRO)
- 数仓:列式存储优化(如Parquet/ORC),支持压缩编码(Run-Length/Dictionary)
数据处理模式:
- Hadoop:批处理为主(MapReduce),新增流处理(Flink/Spark Streaming)
- 数仓:预聚合+物化视图,支持增量刷新(Micro-Batch)
查询优化策略:
- Hadoop:依赖Hive优化器(CBO/RBO),执行计划生成后不可变
- 数仓:高级优化器(规则+代价模型),动态调整执行路径
事务支持:
- Hadoop:基于快照的最终一致性,适合数据分析场景
- 数仓:ACID事务保证,支持实时数据写入(如Kafka->数仓管道)
应用场景对比
| 场景类型 | Hadoop优势领域 | 数仓优势领域 | 混合解决方案案例 |
|---|---|---|---|
| 数据类型 | 日志、传感器数据、音视频 | 结构化业务报表数据 | 日志分析+业务指标关联分析 |
| 处理需求 | ETL预处理、机器学习特征工程 | 即时BI、多维分析 | 特征平台+训练数据集输出 |
| 性能要求 | 离线批量处理(小时级) | 实时交互查询(秒级) | Kafka流处理+数仓加速层 |
| 成本敏感度 | PB级存储成本优先 | 查询性能优先 | 冷热数据分层存储 |
技术融合实践
现代大数据架构常采用Lambda架构的变体:
- 实时层:Kafka+Flink处理流数据,结果写入数仓
- 批处理层:Hadoop集群进行历史数据清洗转换
- 服务层:统一使用Presto/Trino进行跨源查询
- 存储层:HDFS存储原始数据,数仓存储加工后的主题域数据
某电商企业实践案例:
- 原始日志存储在HDFS(每天50TB)
- Spark Streaming实时处理点击流,结果写入Kudu(实时数仓)
- 每日批量作业(Hive+Spark)生成用户画像,存储至HBase
- 业务部门通过Superset连接Hive/Kudu/HBase进行多维分析
性能优化策略对比
| 优化维度 | Hadoop优化方案 | 数仓优化方案 |
|---|---|---|
| 存储优化 | Parquet列式存储、BZ2压缩 | 向量化存储、分区裁剪 |
| 计算优化 | 数据本地性调度、推测执行 | 并行度动态调整、列式执行引擎 |
| 查询优化 | ORC文件索引、Hive统计信息收集 | 物化视图自动刷新、查询缓存 |
| 资源管理 | YARN Cgroup隔离、公平调度 | 资源队列划分、优先级控制 |
未来发展趋势
Hadoop演进:
- 强化流批一体处理(Flink成为核心引擎)
- 容器化部署(Kubernetes+Docker)
- 存算分离架构(类似云数仓)
数仓创新:
- Serverless模式(按查询计费)
- 机器学习集成(内置特征工程)
- 多租户安全(细粒度权限控制)
融合方向:
- 统一元数据管理(Hive Metastore与数仓目录同步)
- 混合存储引擎(同时支持行式/列式存储)
- 智能查询路由(根据SLA自动选择执行引擎)
FAQs:
Q1:如何选择Hadoop和数据仓库?
A:根据数据特性决定:非结构化原始数据存储选Hadoop,结构化分析场景选数仓,建议组合使用,Hadoop做数据湖存储原始数据,数仓进行加工后的数据分析。
Q2:Hive属于数据仓库吗?
A:Hive具备数仓特征(SQL接口、元数据管理),但受限于Hadoop的批处理特性,更适合作为ETL工具,现代数仓(如Snowflake)在性能、实时性方面更
相关文章

数据仓库的含义及特点,数据仓库具有哪些特点(数据仓库的含义及特点,数据仓库具有哪些特点呢)

以下几个疑问句标题可供选择,,创城数据仓库的工资待遇究竟如何?,创城数据仓库工资待遇怎么样?,谁了解创城数据仓库的工资待遇情况?
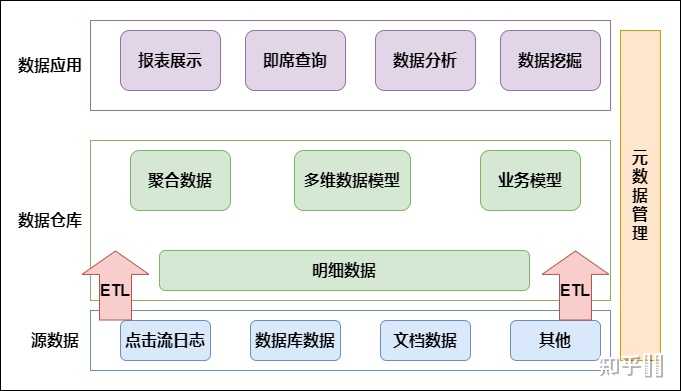
大数据和数据仓库有何区别?探索数据仓库服务的本质

大数据处理hadoop_SQL on Hadoop

安装hadoop_SQL on Hadoop

Hadoop Jar包冲突影响Flink作业提交?如何解决MapReduce与Hadoop的兼容性问题?

如何利用MapReduce和Hadoop实现高效的SQL on Hadoop处理?

kafka 存储hadoop_SQL on Hadoop








