上一篇
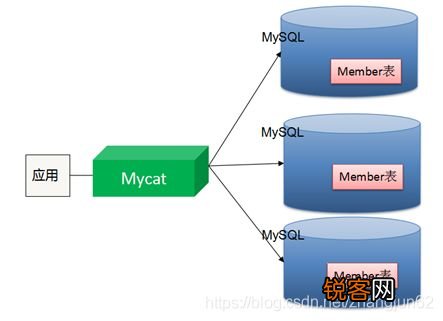
hadoop和数据库的关系型数据库
Hadoop与关系型数据库互补共存:Hadoop擅长分布式存储与处理非结构化大数据,适合批量分析; 关系数据库基于表结构,支持事务与精确查询,适用于结构化数据管理,二者协同
Hadoop与关系型数据库的核心差异与协同应用
核心差异对比
| 维度 | 关系型数据库(如MySQL、Oracle) | Hadoop生态系统(含HDFS、MapReduce、Hive等) |
|---|---|---|
| 数据模型 | 结构化表(行/列严格定义) | 非结构化/半结构化数据(Key-Value、JSON等) |
| 扩展方式 | 纵向扩展(依赖单机性能提升) | 横向扩展(通过增加节点实现线性扩展) |
| 事务支持 | ACID特性(强一致性) | 最终一致性(适合批量处理) |
| 查询延迟 | 毫秒级(优化索引后) | 分钟级(全量扫描+分布式计算) |
| 存储成本 | 较高(商业授权+硬件要求高) | 较低(开源+普通PC服务器集群) |
| 数据处理范式 | OLTP(在线事务处理) | OLAP(离线分析)+流处理(结合Flink等) |
典型应用场景对比
关系型数据库优势场景:
- 高频实时交易(银行转账、电商订单)
- 需要ACID保障的数据操作(如库存扣减)
- 低延迟查询(用户身份验证、配置信息读取)
- 结构化数据管理(企业ERP系统)
Hadoop优势场景:
- 海量日志分析(网站访问日志、传感器数据)
- 复杂ETL处理(数据清洗、格式转换)
- 机器学习训练(大规模数据集预处理)
- 冷数据存储(历史归档数据)
协同工作机制
Hadoop与关系型数据库并非替代关系,而是形成”数据处理流水线”:

graph TD
A[数据采集] --> B{数据分类}
B -->|实时交易数据| C[关系型数据库]
B -->|日志/历史数据| D[Hadoop集群]
D --> E[数据分析]
E --> F[分析结果]
F --> C[同步更新]
C --> G[业务系统]典型集成方案
Sqoop数据同步
功能:在关系型数据库与HDFS间传输数据
典型命令:
# 导出MySQL数据到HDFS sqoop export --connect jdbc:mysql://dbserver/testdb --username user --password pass --table emp --export-dir /user/hadoop/emp # 从HDFS导入到PostgreSQL sqoop import --connect jdbc:postgresql://pgserver/prod --username postgres --password secret --table logs --columns-file /user/hadoop/logs_columns.txt --data-file /user/hadoop/logs_data
Hive+JDBC混合查询
- 架构:通过Hive JDBC接口实现SQL-on-Hadoop
- 优势:数据科学家可使用标准SQL访问HDFS数据
- 示例流程:
- 原始日志存储在HDFS
- Hive创建外部表映射数据结构
- 通过PARTITION分区策略优化查询
- 计算结果写入MySQL供BI系统使用
Lambda架构结合
- 实时层:关系型数据库处理即时查询
- 批处理层:Hadoop进行历史数据分析
- 融合层:通过Kafka实现数据同步
性能优化策略
| 优化方向 | 关系型数据库 | Hadoop集群 |
|---|---|---|
| 索引策略 | B+树索引、哈希索引 | 无原生索引,依赖分区排序 |
| 数据压缩 | 行级压缩(InnoDB) | 块级压缩(Snappy/LZO) |
| 并发控制 | MVCC多版本控制 | 任务调度器(YARN)资源隔离 |
| 备份机制 | 二进制日志+物理备份 | HDFS快照+MapReduce日志 |
成本对比分析
| 成本维度 | 传统关系型数据库 | Hadoop方案 |
|---|---|---|
| 硬件投入 | $50,000+(高端服务器) | $20,000(普通PC集群) |
| 软件授权 | $10,000/年(Oracle标准版) | 免费(开源许可证) |
| 运维复杂度 | 高(需DBA专家) | 中(自动化工具丰富) |
| 扩展成本 | $10,000+/节点 | $3,000/节点 |
FAQs
Q1:什么情况下需要同时使用Hadoop和关系型数据库?
A1:当业务系统包含以下特征时建议组合使用:
- 存在实时交易与历史分析双重需求(如电商平台)
- 需要处理TB级日志同时保持低延迟用户服务
- 数据生命周期管理需求(热数据放数据库,冷数据迁HDFS)
- 混合负载场景(OLTP+OLAP)
Q2:Hadoop能否完全替代关系型数据库?
A2:不能替代,主要限制因素包括:
- 事务支持:Hadoop缺乏ACID事务保证,不适合金融交易
- 查询延迟:Hive/Spark查询通常需要秒级到分钟级
- 数据一致性:最终一致性模型不适用实时精准查询
- 开发成本:SQL-on-Hadoop生态成熟度仍低于传统数据库
- 数据治理:元数据管理、权限控制不如成熟RDBMS完善