上一篇
hadoop数据仓库原理
Hadoop数据仓库基于HDFS分布式存储,通过MapReduce实现并行计算,结合数据分块与副本机制,支持PB级数据
Hadoop数据仓库原理详解
传统数据仓库的局限性与Hadoop的崛起
传统数据仓库(如Teradata、Greenplum)依赖集中式架构,存在以下问题:
- 扩展性差:硬件扩容成本高,纵向扩展能力有限。
- 灵活性低:结构化数据处理为主,难以适应非结构化数据(如日志、文本)。
- 成本高昂:商业许可证费用高,维护复杂。
Hadoop通过分布式存储与计算框架解决了上述问题,其核心优势包括:
- 横向扩展:通过增加廉价PC服务器提升计算和存储能力。
- 高容错性:数据副本机制保证节点故障时服务不中断。
- 多源数据处理:支持结构化、半结构化和非结构化数据。
Hadoop数据仓库的核心组件与架构
Hadoop数据仓库由以下组件构成:
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统,提供高可靠、可扩展的数据存储。 |
| MapReduce | 分布式计算框架,支持大规模数据处理。 |
| Hive | 数据仓库工具,提供SQL接口,支持ETL和OLAP查询。 |
| HBase | 分布式NoSQL数据库,适合实时读写和随机访问。 |
| YARN | 资源调度器,统一管理集群资源,支持多任务并行。 |
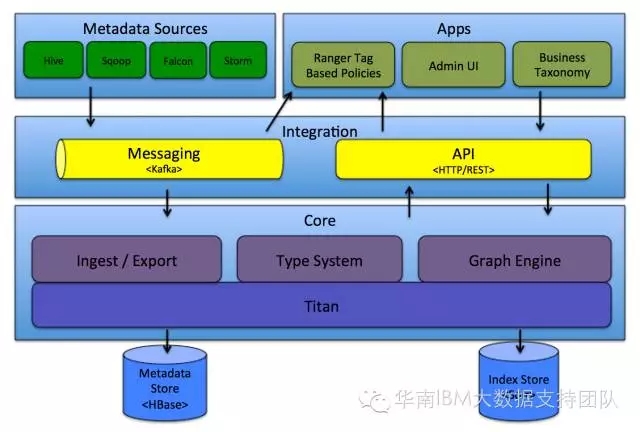
架构图示:
用户 → Hive/HBase → MapReduce/YARN → HDFS Hadoop数据仓库的存储原理
HDFS存储机制:
- 块存储:文件被拆分为固定大小(默认128MB)的Block,分散存储在不同节点。
- 副本策略:每个Block默认存储3份副本,分布在不同机架内,保证高可用性。
- 元数据管理:NameNode记录文件元数据(路径、Block位置),DataNode存储实际数据。
数据分区与压缩:

- 分区(Partition):按时间、哈希等规则将数据分散到不同目录,减少单节点负载。
- 压缩(Compression):采用Snappy、Gzip等算法减少存储空间和网络传输开销。
HDFS与传统文件系统对比:
| 特性 | HDFS | 传统文件系统(如NTFS) |
|——————|———————–|—————————|
| 扩展性 | 横向扩展(添加节点) | 纵向扩展(升级硬件) |
| 容错性 | 自动副本恢复 | 依赖RAID等硬件方案 |
| 数据访问 | 流式读取(适合批处理)| 随机读写(适合交互式) |
Hadoop数据仓库的计算模型
MapReduce原理:
- Map阶段:输入数据被分割为多个Split,每个Split由Mapper处理并生成键值对。
- Shuffle阶段:根据Key对数据排序并分组,分发到不同Reducer。
- Reduce阶段:合并具有相同Key的键值对,输出最终结果。
YARN资源调度:
- ResourceManager:负责全局资源分配(CPU、内存)。
- NodeManager:监控节点资源使用情况,执行容器化任务。
- ApplicationMaster:为每个任务申请资源并协调执行。
MapReduce vs Spark:
| 特性 | MapReduce | Spark |
|——————|————————|—————————|
| 计算模型 | 磁盘IO密集型 | 内存计算为主 |
| 延迟 | 高(分钟级) | 低(秒级) |
| 适用场景 | 离线批处理 | 实时/准实时分析 |
Hadoop数据仓库的数据处理流程
数据加载:
- 批量导入:通过Sqoop从关系数据库导入数据到HDFS。
- 实时采集:使用Flume接收日志流并写入HDFS。
数据转换(ETL):
- 清洗:去除重复、错误数据(如使用Hive的
WHERE过滤)。 - 转换:通过Hive SQL或自定义MapReduce任务完成数据聚合、格式转换。
- 加载:将处理后的数据写入目标表或分区。
- 清洗:去除重复、错误数据(如使用Hive的
数据分析与查询:
- OLAP查询:通过Hive执行复杂SQL(如
GROUP BY、JOIN)。 - 实时查询:结合HBase实现低延迟随机读写(如用户画像更新)。
- OLAP查询:通过Hive执行复杂SQL(如
Hadoop数据仓库的优化策略
存储优化:
- 合并小文件:使用
Hadoop CombineFileInputFormat减少Mapper数量。 - 列式存储:通过Parquet/ORC文件格式压缩存储空间并加速查询。
- 合并小文件:使用
计算优化:
- 数据本地性:尽量让计算任务靠近数据存储节点,减少网络传输。
- 倾斜处理:对Key分布不均的任务,采用自定义分区或
Map端聚合。
资源优化:
- 动态资源分配:YARN根据任务负载动态调整资源(如内存、CPU)。
- 容器复用:通过
Yarn Scheduler配置缩短任务启动时间。
FAQs
Q1:Hadoop数据仓库与传统数据仓库的本质区别是什么?
A1:传统数据仓库依赖专有硬件和集中式架构,扩展成本高且灵活性差;Hadoop基于廉价PC服务器构建分布式集群,支持横向扩展和多源数据处理,更适合海量异构数据的存储与分析。
Q2:Hadoop数据仓库如何支持实时数据分析?
A2:Hadoop本身以批处理为主,但可通过以下方式增强实时性:
- HBase:提供低延迟的随机读写能力,适合实时数据更新。
- Spark Streaming:结合Hadoop生态实现准实时流处理。
- Kafka+Flume:构建实时数据采集管道,将数据