上一篇
hadoop数据仓库优化架构
Hadoop数据仓库优化架构通过HDFS存储优化、MapReduce计算调优、YARN资源管理及Hive索引优化提升性能,结合数据压缩与分区策略减少I/O,采用列式存储提升查询效率,并实施数据治理
Hadoop数据仓库优化架构详解
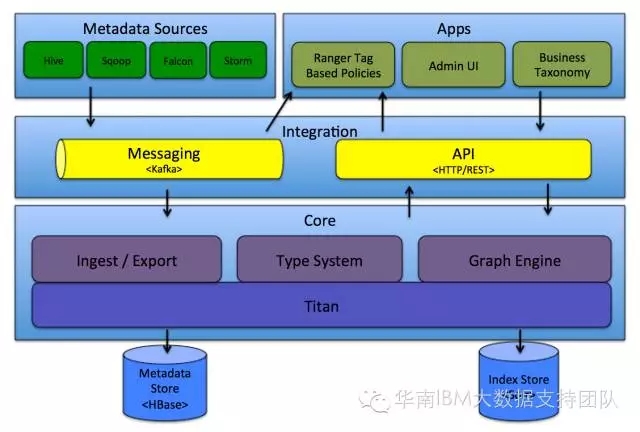
传统数据仓库与Hadoop架构的对比
在大数据场景下,传统数据仓库(如Teradata、Greenplum)面临扩展性差、成本高昂等问题,而Hadoop凭借分布式存储和计算能力成为主流选择,以下是两者的核心差异:
| 特性 | 传统数据仓库 | Hadoop数据仓库 |
|---|---|---|
| 扩展性 | 纵向扩展(依赖硬件升级) | 横向扩展(添加节点) |
| 成本 | 高昂(专用硬件+授权) | 低成本(开源+普通PC服务器) |
| 数据类型支持 | 结构化数据为主 | 支持结构化、半结构化、非结构化 |
| 灵活性 | 固定Schema,扩展困难 | Schema-on-Read,动态适配 |
Hadoop数据仓库优化核心方向
存储层优化
- HDFS参数调优:调整
dfs.replication(默认3,可根据业务重要性降低)、dfs.blocksize(增大至256MB或1GB以减少元数据压力)。 - 数据压缩:启用Snappy(快速压缩)或Zlib(高压缩率),减少I/O开销。
ALTER TABLE user_logs SET TBLPROPERTIES ('orc.compress'='SNAPPY'); - 文件格式选择:优先使用ORC/Parquet格式,支持列式存储和高效压缩。
- HDFS参数调优:调整
计算引擎优化
- 引擎对比:
| 场景 | MapReduce | Spark | Flink |
|——————|——————–|——————|——————–|
| 实时性 | 低(分钟级) | 中等(秒级) | 高(毫秒级) |
| 资源消耗 | 高(频繁磁盘IO) | 低(内存优先) | 中等(流式计算) |
| 适用任务 | 批处理 | 迭代式计算 | 流批一体 | - 推荐方案:离线任务用Spark(如ETL),实时流处理用Flink,复杂依赖用MapReduce。
- 引擎对比:
资源调度优化

- YARN配置:
- 动态资源分配:启用
yarn.scheduler.capacity.root.default.user-limit-factor=1,允许按需申请资源。 - 内存与CPU配比:设置
yarn.nodemanager.resource.memory-mb与yarn.nodemanager.resource.cpu-vcores比例为8:1(如32GB内存配4核)。
- 动态资源分配:启用
- 容器优化:限制单个任务的
mapreduce.map.memory.mb(如4GB),防止资源争抢。
- YARN配置:
数据分区与分桶
- 分区策略:按时间(如
dt=2023-10-01)或业务维度(如country)分区,示例:PARTITION (dt STRING, country STRING)
- 分桶规则:对高基数字段(如
user_id)哈希分桶,避免数据倾斜。CLUSTERED BY (hash_value) INTO 16 BUCKETS
- 分区策略:按时间(如
索引与加速技术
- 二级索引:对高频查询字段(如
order_id)创建Bitmap索引。 - 物化视图:预计算常用聚合结果,减少实时计算压力。
CREATE MATERIALIZED VIEW mv_sales AS SELECT date_trunc('day', order_time) AS dt, SUM(amount) FROM orders GROUP BY dt;
- 二级索引:对高频查询字段(如
SQL查询优化
- 避免全表扫描:强制使用分区键过滤,
WHERE dt = '2023-10-01' AND country = 'US'
- 广播变量:小表join大表时,使用
broadcast hint将小表加载到内存。 - 谓词下推:开启
hive.optimize.ppd=true,让查询计划尽早过滤数据。
- 避免全表扫描:强制使用分区键过滤,
安全与权限管理
- RBAC模型:通过Apache Ranger或Sentry实现角色权限控制,
{ "groups": [ { "name": "data_scientists", "permissions": [ {"type": "select", "db": "default", "table": "user_behavior"} ] } ] } - 数据脱敏:对敏感字段(如
phone_number)启用Masking策略。
- RBAC模型:通过Apache Ranger或Sentry实现角色权限控制,
监控与运维优化
- 关键指标:
| 指标 | 阈值 | 意义 |
|————————|——————————|——————————|
| HDFS使用率 | <85% | 避免存储空间耗尽 |
| YARN队列等待时间 | <5分钟 | 防止任务积压 |
| Spark作业失败率 | <3% | 保证系统稳定性 | - 工具链:集成Prometheus(监控)、Ganglia(性能分析)、Nagios(告警)。
- 关键指标:
典型优化案例
场景:某电商企业每日新增10TB订单数据,查询延迟过高。
优化方案:
- 将ORC格式替换为Parquet,压缩率提升20%。
- 按
dt和shop_id双重分区,减少全表扫描。 - 对
user_id字段建立BloomFilter索引,降低Join耗时。 - 使用Spark Tachyon(Alluxio)缓存热数据,查询速度提升4倍。
FAQs
Q1:如何提升Hadoop数据仓库的查询速度?
A1:
- 启用列式存储(ORC/Parquet)并开启压缩。
- 合理设计分区和分桶,避免数据热点。
- 使用物化视图或中间表缓存常用结果。
- 优化SQL逻辑,利用广播变量和谓词下推。
- 部署LLAP(Low-Latency Analytical Processing)加速实时查询。
Q2:如何处理Hadoop中的小文件过多问题?
A2:
- 合并小文件:使用
Hive Concat功能合并同类文件。INSERT OVERWRITE DIRECTORY /tmp/merged SELECT file_path FROM small_files;
- 调整分区策略:避免过度细分分区(如按小时分区改为按天)。
- 采用SequenceFile/Avro格式存储,减少元数据开销。
- 开启HDFS `dfs.namenode.fs-limit-concurrent-open-