上一篇
hadoopmpp数据仓库产品
Hadoop MPP数据仓库产品结合分布式存储与并行计算,支持PB级数据处理,具备高扩展性、实时分析能力,适用于企业级数据仓库与
Hadoop MPP数据仓库产品详解
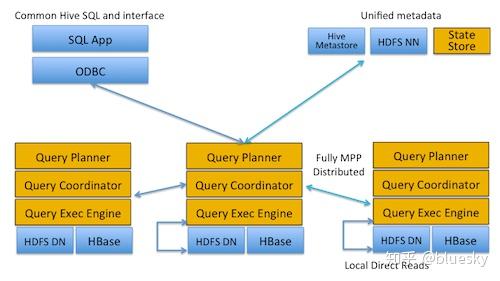
核心概念与技术架构
Hadoop MPP数据仓库是将Hadoop分布式存储能力与MPP(Massively Parallel Processing,大规模并行处理)计算引擎结合的产物,旨在解决传统Hadoop生态(如Hive、Spark)在复杂查询场景下的性能瓶颈,其核心特点包括:
- 分布式存储:基于HDFS或云存储(如S3)实现PB级数据存储。
- 并行计算:通过MPP架构将查询任务拆解为多个子任务,在多节点上并行执行。
- 列式存储优化:采用列式存储格式(如ORC、Parquet),减少I/O开销并加速聚合类查询。
- SQL兼容性:支持标准SQL语法,降低开发门槛。
典型技术架构:
| 组件 | 功能说明 |
|——————–|————————————————————————–|
| 数据存储层 | HDFS/云存储(如S3)、列式文件格式(ORC/Parquet)、数据压缩与分区策略 |
| 计算引擎层 | MPP查询引擎(如Greenplum、Presto)、资源调度(YARN/Kubernetes) |
| 优化器 | 查询优化(谓词下推、动态分区裁剪)、执行计划生成 |
| 元数据管理 | 表结构、分区信息、权限管理(兼容Hive Metastore或自定义元数据服务) |
主流Hadoop MPP数据仓库产品对比
以下是市场上主流产品的技术特性与适用场景分析:
| 产品名称 | 架构特点 | 性能优势 | 扩展性 | 成本模式 | 适用场景 |
|---|---|---|---|---|---|
| Greenplum | 开源MPP架构(基于PostgreSQL) | 高并发查询、复杂SQL支持 | 横向扩展至千节点 | 硬件+软件许可 | 金融风控、电信计费、日志分析 |
| Amazon Redshift | AWS云原生SPB架构 | 与S3深度集成、自动扩缩容 | 弹性扩展(PB级) | 按需实例+存储费用 | 电商数据分析、实时BI |
| Azure Synapse | 混合MPP与无服务器架构 | 无缝衔接Data Lake与数据仓库 | 按需扩展(秒级弹性) | 按量计费(CPU+IO) | 混合云迁移、ETL+BI一体化 |
| Google BigQuery | 全托管Serverless MPP | 秒级响应、自动优化查询 | 无上限扩展(全球节点) | 按查询扫描量计费 | 实时Ad Tech、机器学习数据集 |
| Hive+Tez/Spark | 内存计算+批处理 | 依赖YARN资源调度,适合离线分析 | 受限于集群规模 | 开源免费 | 低成本历史数据处理、小规模报表 |
关键优化技术解析
- 数据分区与分桶:
- 按时间、地域等维度分区,减少全表扫描。
- 分桶(如MD5哈希)提升JOIN操作效率。
- 向量化执行:
批量处理数据而非逐行处理,降低CPU开销。

- 智能索引:
Bitmap索引、Bloom过滤器加速WHERE条件过滤。
- 近似计算:
HyperLogLog、Count-Min Sketch等算法实现快速去重与统计。
选型建议与实践要点
- 数据规模与增长:
TB级可选开源方案(如Greenplum),PB级优先云服务(Redshift/Synapse)。
- 实时性需求:
亚秒级响应选择BigQuery/Redshift,分钟级可接受则自建MPP集群。
- 成本控制:
云服务按用量付费,自建需考虑硬件折旧与运维成本。
- 生态兼容性:
需与现有ETL工具(如Apache NiFi)、BI工具(Tableau/Power BI)无缝对接。
常见问题(FAQs)
Q1:Hadoop MPP数据仓库与传统MPP数据库(如Netezza)有何区别?
A1:Hadoop MPP产品基于廉价X86服务器与开源生态,支持HDFS/云存储,扩展成本更低;而传统MPP(如Netezza)依赖专用硬件,适用于超高性能场景但成本高昂。
Q2:如何判断业务是否需要MPP架构?
A2:若业务涉及以下场景,建议采用MPP:
- 单次查询扫描数据量超过100GB;
- 复杂JOIN、GROUP BY操作占比高;
- 需要亚秒级交互