上一篇
hadoop数据仓库好用吗
Hadoop数据仓库适合海量数据处理,扩展性强但部署运维复杂,实时性较弱
Hadoop数据仓库作为大数据时代的重要基础设施,其实用性和适用性一直是企业和开发者关注的焦点,以下从技术特性、应用场景、优缺点对比、实际案例等多个维度进行深度分析,帮助用户全面评估Hadoop数据仓库的适用性。
Hadoop数据仓库的核心特性
| 特性 | 技术实现 | 作用 |
|---|---|---|
| 分布式存储 | HDFS(Hadoop Distributed File System) | 支持PB级数据存储,通过块复制机制保证高容错性 |
| 并行计算框架 | MapReduce(或Spark/Flink等替代引擎) | 拆分任务至多节点执行,提升处理效率 |
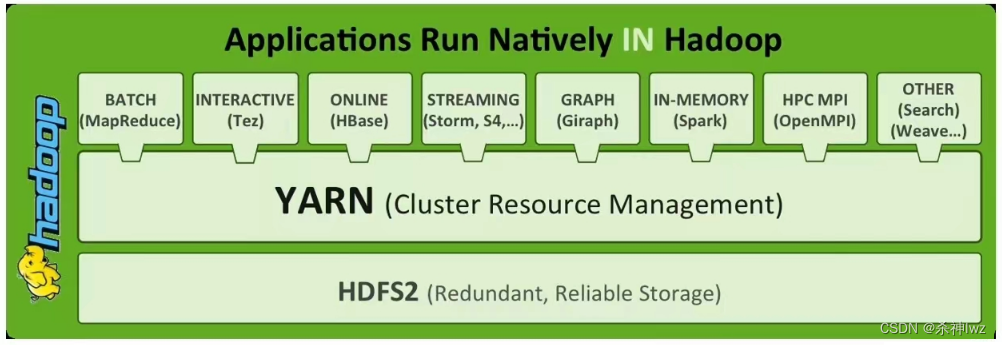
| 横向扩展能力 | 通过增加普通PC服务器节点实现扩容 | 突破传统数据库的硬件性能瓶颈,降低成本 |
| 数据批处理 | 适合离线分析场景(如ETL、数据挖掘) | 处理海量数据时性能稳定,但实时性较弱 |
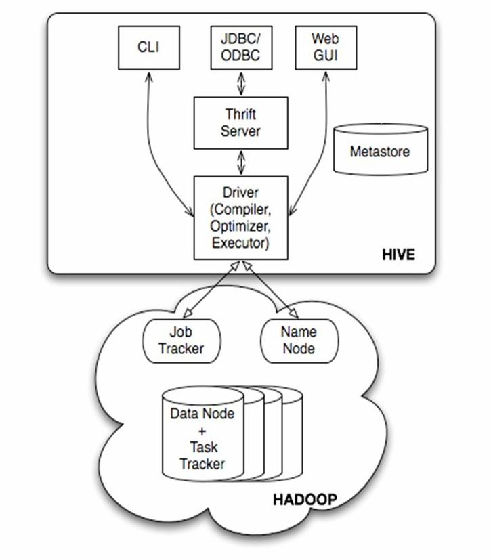
| 开放生态 | 与Hive、Pig、Impala等工具兼容 | 支持SQL查询、流处理、图计算等多种业务需求 |
Hadoop数据仓库的优势分析
低成本处理海量数据
- 存储成本:采用廉价PC服务器集群,相比传统高端数据库硬件成本降低80%以上。
- 计算弹性:动态分配计算任务,避免资源浪费,特别适合非结构化数据(如日志、视频)的存储与分析。
高可靠性与容错性
- 数据冗余:HDFS默认3副本存储,节点故障时自动切换,保障数据不丢失。
- 任务重试:MapReduce任务失败后可自动重启,适合复杂计算场景。
灵活的数据处理能力
- 多源数据整合:支持从关系型数据库、NoSQL、文件系统等多渠道导入数据。
- 生态丰富:通过Hive实现SQL化查询,Sqoop完成数据迁移,Oozie管理工作流,覆盖数据仓库全链路需求。
社区与商业支持并存
- 开源社区:全球开发者持续优化核心组件(如HDFS联邦架构、YARN资源调度)。
- 企业版服务:厂商提供定制化支持(如Cloudera Manager、Hortonworks Data Platform),降低运维复杂度。
Hadoop数据仓库的局限性
实时性不足
- 延迟问题:MapReduce任务启动和数据传输耗时较长,难以处理秒级实时需求。
- 解决方案:需结合Kafka+Spark Streaming等实时计算框架,但系统复杂度显著增加。
运维成本高
- 组件复杂:需管理NameNode、DataNode、ResourceManager等十余个核心服务。
- 资源调优:YARN资源分配、内存溢出等问题需要经验丰富的运维人员。
硬件资源消耗大
- 磁盘占用:HDFS存储效率较低(默认3副本),实际可用空间仅约33%。
- 网络带宽:Shuffle阶段产生大量中间数据传输,对网络IO要求极高。
学习门槛较高
- 技术栈复杂:需掌握Java/Scala开发、Linux系统管理、分布式原理等技能。
- 调试困难:分布式环境下的错误定位比单机系统更复杂。
与传统及现代数据仓库的对比
| 维度 | Hadoop数据仓库 | 传统数据仓库(如Oracle) | 云原生数据仓库(如Redshift) |
|---|---|---|---|
| 扩展性 | 横向扩展(添加节点) | 纵向扩展(依赖高端硬件) | 弹性扩展(按需付费) |
| 成本 | 硬件成本低,运维成本高 | 硬件+软件成本极高 | 按使用量付费,初期成本低 |
| 实时性 | 弱(需结合流处理框架) | 强(内置事务支持) | 强(毫秒级响应) |
| 易用性 | 需复杂配置和运维 | 开箱即用,图形化管理 | 自动化运维,SQL兼容 |
| 最佳场景 | 离线批处理、非结构化数据分析 | 小规模结构化数据OLAP分析 | 实时BI、混合负载场景 |
实际应用案例分析
互联网用户行为分析
某电商平台使用Hadoop存储每日50TB用户日志,通过MapReduce清洗数据后加载至Hive,结合Spark进行用户画像建模,虽然处理延迟在小时级,但成本仅为商用数据仓库的1/5。

金融风控系统
某银行将历史交易数据存入HBase(Hadoop生态组件),利用Impala进行实时查询,辅助反欺诈检测,但由于Hadoop实时性限制,核心风控规则仍依赖传统数据库。
基因测序数据处理
科研团队使用Hadoop分布式存储PB级基因序列数据,通过Bamtools等工具进行比对分析,Hadoop的高吞吐量显著缩短了处理时间。
适用场景建议
| 场景类型 | 推荐度 | 建议方案 |
|---|---|---|
| 离线数据分析 | Hadoop+Hive+Spark(批处理) | |
| 实时数据监控 | Hadoop+Kafka+Flink(需额外投入) | |
| 冷数据存储 | Hadoop归档历史数据,降低存储成本 | |
| 混合负载(批+实时) | 建议拆分系统,Hadoop处理批任务,专用系统(如ClickHouse)处理实时需求 |
FAQs
问题1:中小企业是否适合使用Hadoop数据仓库?
答案:需谨慎评估,若数据量未达TB级(如日均增量<100GB),Hadoop的运维成本可能超过开源数据库(如MySQL+MongoDB)的收益,建议优先考虑云服务(如AWS EMR)或轻量级方案(如Apache Drill)。
问题2:如何优化Hadoop数据仓库的查询性能?
答案:
- 数据分区:按时间、地域等字段预分区,减少全表扫描。
- 压缩存储:启用Parquet/ORC列式存储,节省70%存储空间并加速查询。
- 索引优化:使用Hive的Bloom过滤器或Bitmap索引跳过无关数据。
- 资源调优:调整YARN容器内存比例,避免Map/Reduce