上一篇
hadoop建立数据仓库
Hadoop通过HDFS存储海量数据,结合MapReduce或Spark处理,经ETL流程整合清洗,利用Hive等工具
Hadoop建立数据仓库的详细实践指南
Hadoop与数据仓库的结合背景
Hadoop作为分布式计算框架,凭借其高扩展性、低成本存储和并行处理能力,成为现代数据仓库的重要基础,与传统数据仓库(如基于Oracle、Teradata的解决方案)相比,Hadoop生态提供了更灵活的数据处理方式,尤其适合处理海量非结构化或半结构化数据。
传统数仓 vs Hadoop数仓对比表
| 特性 | 传统数仓 | Hadoop数仓 |
|———————|————————–|———————————|
| 数据类型 | 结构化为主 | 结构化/非结构化混合支持 |
| 扩展性 | 纵向扩展(依赖硬件升级) | 横向扩展(增加节点即可) |
| 成本 | 高昂(授权费+硬件) | 低成本(开源软件+普通PC服务器)|
| 处理模式 | 专用SQL引擎 | 批处理(MapReduce)+实时(Flink)|
| 存储架构 | 集中式存储 | 分布式文件系统(HDFS) |
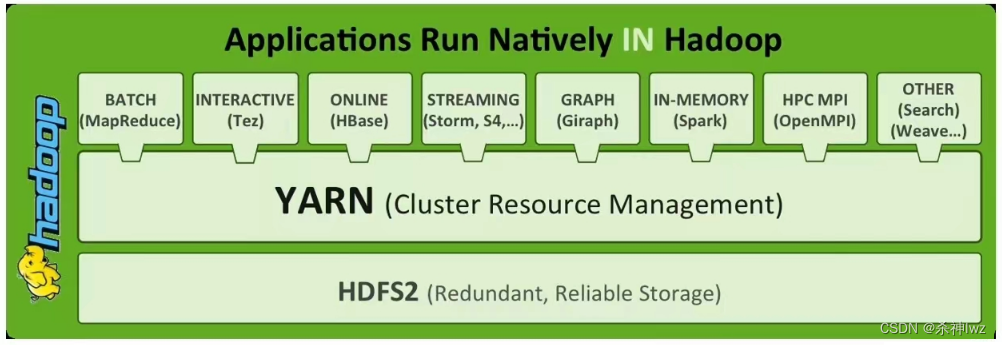
Hadoop数据仓库架构设计
核心组件选型
- 存储层:HDFS(默认块大小128MB,副本数3)
- 计算引擎:MapReduce(批量处理)、Spark(内存计算)、Flink(流批一体)
- 元数据管理:Hive(SQL on Hadoop)、HCatalog(统一元数据服务)
- 调度系统:YARN(资源管理)、Oozie(工作流调度)
- 数据接入:Sqoop(关系库导入导出)、Flume(日志流采集)
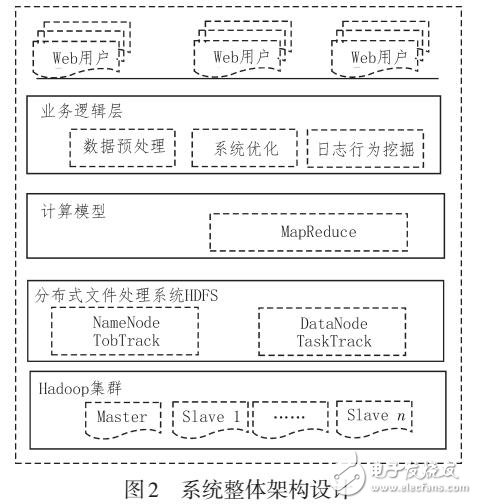
分层架构设计
典型数据仓库采用四层架构:- ODS层(操作数据存储):原始数据落地层,保留最细粒度数据
- DWD层(明细数据层):清洗后的结构化数据,按业务维度分区
- DWS层(汇总数据层):轻度聚合数据,按主题组织(如用户行为、订单统计)
- ADS层(应用数据层):为具体业务定制的数据集(如BI报表、ML训练集)
环境部署与配置
集群规划
- 典型生产环境采用「多Master+多Slave」架构
- 推荐节点配置:
- Master节点:8核CPU/16GB内存/500GB SSD(部署NameNode/ResourceManager)
- Slave节点:16核CPU/64GB内存/4TB HDD(DataNode/NodeManager)
- 网络拓扑:千兆以太网+心跳网络分离
关键配置文件
hdfs-site.xml核心参数:<property> <name>dfs.replication</name> <value>3</value> <!-副本数 --> </property> <property> <name>dfs.blocksize</name> <value>134217728</value> <!-128MB块大小 --> </property>
yarn-site.xml资源调度配置:<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>40960</value> <!-每个NodeManager最大内存 --> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>30720</value> <!-单个任务最大内存 --> </property>
数据处理流程
数据采集

批量导入:
sqoop import --connect jdbc:mysql://sourceDB --table user_log --target-dir /ods/user_log实时采集:Flume配置示例:
agent.sources = source1 agent.channels = channel1 agent.sinks = sink1 agent.sources.source1.type = taildir agent.sources.source1.channel = channel1 agent.sources.source1.filegroups = f1:/var/log/app/.log agent.channels.channel1.type = memory agent.channels.channel1.capacity = 10000 agent.channels.channel1.transactionCapacity = 1000 agent.sinks.sink1.type = hdfs agent.sinks.sink1.channel = channel1 agent.sinks.sink1.hdfs.path = hdfs://namenode/flume/%Y%m%d/%H%M/
数据清洗转换
- Hive SQL示例:
CREATE TABLE dwd_user_behavior AS SELECT user_id, parse_url(referrer, 'PATH') AS page_path, CASE WHEN action = 'click' THEN 1 ELSE 0 END AS is_click, ntp_timestamp AS event_time FROM ods_raw_log WHERE ntp_timestamp > date_sub(current_timestamp, 7) -保留最近7天数据 DISTRIBUTE BY user_id; -按用户ID哈希分区
- Hive SQL示例:
数据聚合加速
创建分区表提升查询效率:
CREATE TABLE dws_order_stats ( order_date STRING, total_amount DOUBLE, order_count BIGINT ) PARTITIONED BY (dt STRING) STORED AS ORC; INSERT OVERWRITE TABLE dws_order_stats PARTITION(dt) SELECT from_unixtime(event_time, 'yyyy-MM-dd') AS order_date, sum(order_amount) AS total_amount, count(1) AS order_count, from_unixtime(event_time, 'yyyy-MM-dd') AS dt FROM dwd_order_detail GROUP BY from_unixtime(event_time, 'yyyy-MM-dd');
性能优化策略
存储优化
| 优化项 | 方案 |
|———————-|———————————————————————-|
| 数据压缩 | 使用Snappy(Hive表属性:TBLPROPERTIES ("orc.compress"="SNAPPY"))|
| 文件大小控制 | 设置mapreduce.input.fileinputformat.split.maxsize=256MB|
| 列式存储 | Hive使用ORC格式替代TEXTFILE |计算优化
- 倾斜处理:启用
mapreduce.job.auto-balance并设置mapreduce.job.reduces动态调整 - 内存优化:Spark配置
spark.executor.memory=4G配合spark.sql.shuffle.partitions=200 - 索引加速:Hive创建BITMAP索引(
CREATE INDEX ON table(col) AS 'BITMAP')
- 倾斜处理:启用
JVM调优
- MapTask JVM参数:
mapreduce.map.java.opts=-Xmx3072m -XX:+UseG1GC -XX:MaxGCPauseMillis=200
- YARN容器配置:
<property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> <!-虚拟内存是物理内存4倍 --> </property>
- MapTask JVM参数:
数据治理与安全
元数据管理
- 使用Apache Atlas进行数据血缘追踪
- Hive Metastore配置MySQL持久化:
<property> <name>hive.metastore.uris</name> <value>thrift://metastore:9083</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property>
权限控制
- Ranger插件配置示例:
{ "policyItems": [ { "accesses": ["read", "write"], "database": "dw_db", "tables": ["dwd_user_behavior"], "users": ["data_team"] } ] } - HDFS ACL配置:
hdfs dfs -setfacl -m user data_team:rwx /dw/dwd/ hdfs dfs -setfacl -d /dw/dwd/ default:r--
- Ranger插件配置示例:
典型应用场景
电商领域
- 用户行为分析:通过Hive+Spark计算UV/PV、转化率漏斗
- 订单监控:实时统计每小时GMV,设置异常阈值告警
金融风控
- 反欺诈模型:基于历史交易数据训练随机森林模型(使用H2O on Spark)
- 信用评分:整合多源数据(征信报告、消费记录)构建特征宽表
物联网场景
- 设备日志分析:Flume采集->Kafka缓冲->Spark Streaming实时处理
- 时序数据库集成:将聚合结果同步至InfluxDB进行可视化
FAQs
Q1:Hadoop数据仓库与传统数仓的核心区别是什么?
A1:主要差异体现在三个方面:① 存储成本(Hadoop使用廉价PC服务器,传统数仓依赖小型机);② 数据类型支持(Hadoop可处理非结构化数据);③ 扩展方式(Hadoop横向扩展,传统数仓纵向扩展),例如处理1PB日志数据,Hadoop集群成本仅为传统数仓的1/5。
Q2:如何诊断Hive SQL执行缓慢的问题?
A2:可从四个维度排查:① 查看执行计划(EXPLAIN FORMATTED);② 检查数据倾斜(通过MAPJOIN或DISTRIBUTE BY优化);③ 验证索引有效性;④ 调整并行度(设置mapreduce.job.reduces=500),实际案例中,某电商公司通过将TEXTFILE改为ORC格式,使复杂查询速度提升