上一篇
hadoop和数据仓库区别
Hadoop基于分布式架构处理非结构化大数据,支持灵活扩展;数据仓库采用传统架构管理结构化数据,侧重高效查询分析
Hadoop与数据仓库的区别分析

在大数据技术领域,Hadoop和数据仓库是两种不同的数据处理架构,它们在设计理念、技术实现和应用场景上存在显著差异,以下从多个维度进行对比分析:
| 对比维度 | Hadoop | 数据仓库 |
|---|---|---|
| 核心定位 | 分布式大数据处理框架 | 结构化数据存储与分析系统 |
| 数据类型 | 支持结构化、半结构化、非结构化数据(如日志、文本、音视频) | 主要处理结构化数据(如关系型数据库表) |
| 架构模式 | 基于HDFS分布式文件系统+MapReduce计算框架 | 基于关系型数据库(如Oracle、SQL Server)或专用数仓(如Teradata) |
| 扩展方式 | 横向扩展(Add节点即可扩容) | 纵向扩展(依赖硬件升级)或有限横向扩展 |
| 数据处理 | 批处理为主(也可通过Spark实现流处理) | 支持OLAP分析(预聚合立方体)、实时查询 |
| 存储格式 | 原始数据存储(如Text/CSV/Parquet/ORC) | 标准化表结构(星型/雪花模型) |
| 计算引擎 | MapReduce、Spark、Flink | SQL查询优化器、物化视图 |
| 数据更新 | 追加写入(Write-Once-Read-Many) | 支持ACID事务(Insert/Update/Delete) |
| 延迟性 | 分钟级到小时级延迟(批处理) | 亚秒级到秒级延迟(实时查询) |
| 硬件成本 | 廉价PC服务器集群(x86架构) | 专用高端服务器(UNIX/IBM大型机) |
| 典型场景 | 互联网日志分析、用户行为分析、机器学习数据预处理 | 企业级报表、财务分析、固定业务指标计算 |
技术特性深度解析
- 数据存储机制
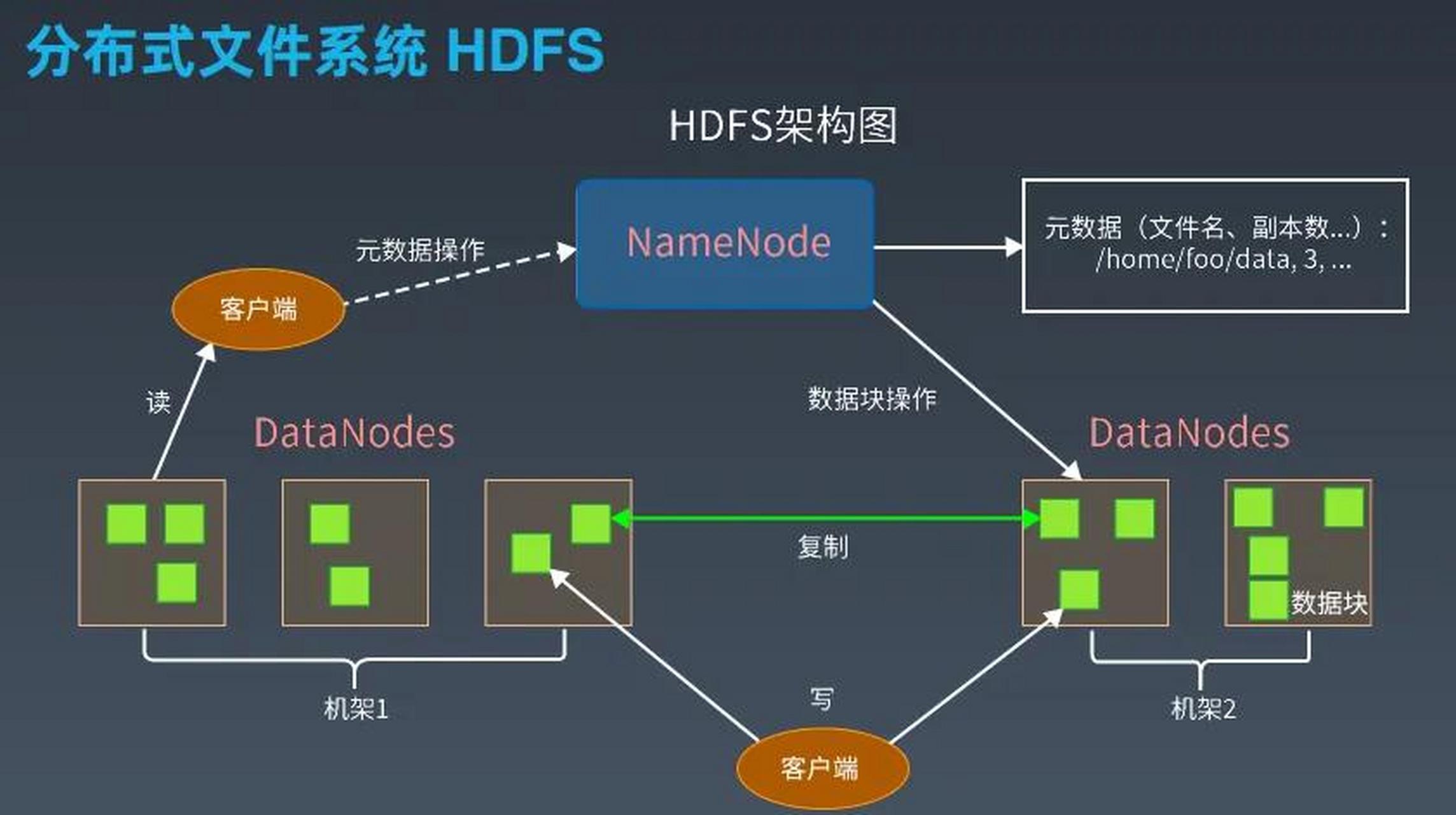
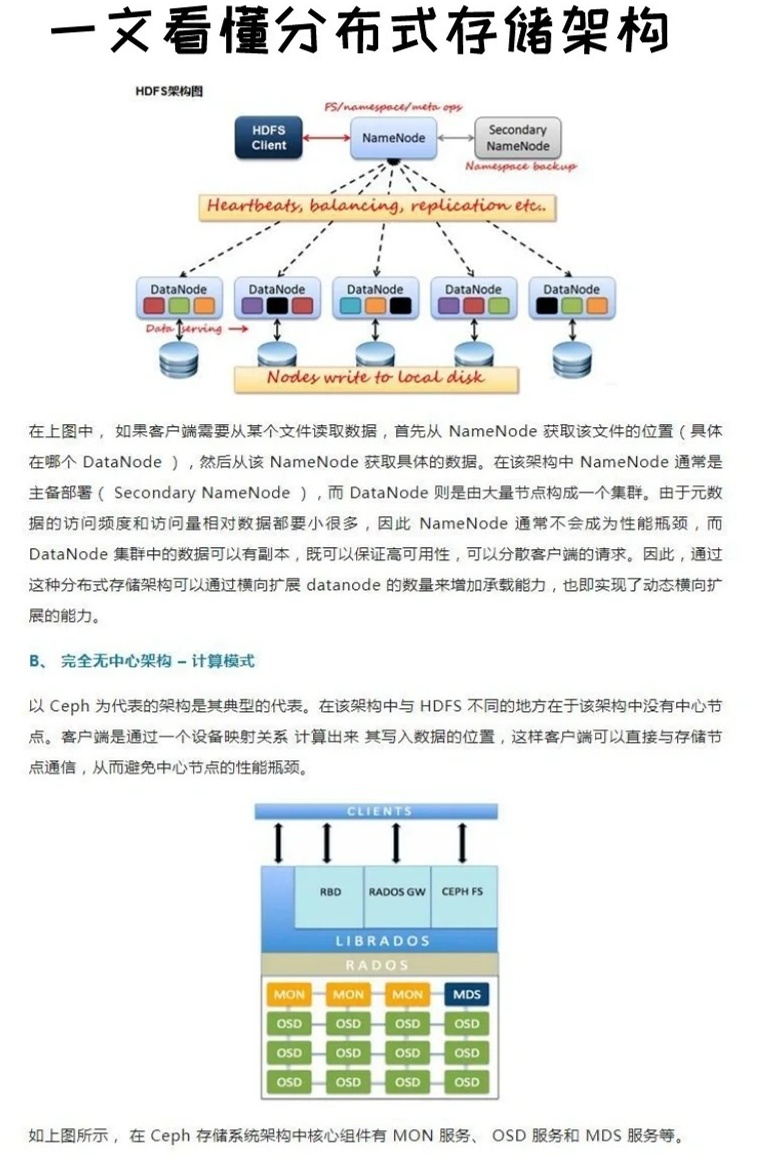
- Hadoop采用分布式文件系统(HDFS),将大文件切块存储,适合PB级原始数据存储,数据以块形式分布存储,无Schema约束。
- 数据仓库使用关系模型,要求预先定义数据Schema,数据按表结构组织,适合高一致性事务处理。
- 计算模型差异
- Hadoop的MapReduce将任务分解为Map阶段(数据切片处理)和Reduce阶段(结果汇总),适合离线批处理,Spark通过内存计算提升性能,支持迭代式算法。
- 数据仓库依赖SQL引擎优化查询计划,通过索引、分区、物化视图加速复杂查询,强调实时响应速度。
- 数据治理能力
- Hadoop生态(如Apache Hive/Impala)逐步增强SQL支持,但元数据管理相对松散,适合探索性数据分析。
- 数据仓库具备完善数据治理体系,支持主外键约束、ACID事务、数据血缘追踪,适合企业级生产环境。
- 扩展性对比
- Hadoop通过增加节点实现线性扩展,理论上可支持EB级数据存储,但运维复杂度随规模上升。
- 传统数据仓库扩展成本高昂,新型MPP数仓(如Greenplum)虽支持横向扩展,但成本仍高于Hadoop。
- 实时性能力
- Hadoop原生批处理延迟较高(通常小时级),需结合Kafka+Spark Streaming实现近实时处理。
- 数据仓库通过列式存储、向量化计算可实现秒级查询响应,适合实时决策场景。
选型建议
| 需求场景 | 推荐方案 | 原因说明 |
|---|---|---|
| 海量非结构化数据处理 | Hadoop+Elasticsearch | 低成本存储+全文检索能力 |
| 实时业务指标监控 | 数据仓库+Kafka流处理 | 低延迟查询+事务一致性保证 |
| 机器学习模型训练 | Hadoop+Spark+TensorFlow | 大规模数据预处理+分布式计算框架 |
| 企业级财务报表分析 | Teradata/Redshift | ACID事务+复杂SQL支持 |
典型应用案例
- 电商用户行为分析
- Hadoop:存储全量浏览日志、点击流数据,进行用户画像建模
- 数据仓库:存储订单交易数据,生成GMV日报、转化率分析
- 物联网数据处理
- Hadoop:接收设备传感器原始数据,进行清洗转换
- 时序数据库:存储处理后的设备状态数据,实时监控预警
技术演进趋势
- Hadoop系:向实时化(Flink)、智能化(AI集成)、云原生(Kubernetes调度)发展
- 数据仓库:加强混合负载处理能力(HTAP架构),支持Serverless弹性扩缩容
- 融合方向:出现Hadoop+数据仓库混合架构,如使用Hive做历史数据存储,Redshift处理实时分析
FAQs
Q1:Hadoop可以完全替代数据仓库吗?
A1:不能直接替代,Hadoop擅长处理非结构化数据和离线批处理,但在事务处理、实时查询、数据一致性方面存在短板,企业通常采用”Hadoop+数据仓库”混合架构:用Hadoop处理原始日志和用户行为数据,用数据仓库存储交易数据和生成经营报表。
Q2:如何判断业务应该选择Hadoop还是数据仓库?
A2:关键看三个维度:①数据结构:非结构化占比高选Hadoop;②时效性要求:实时分析选数仓;③成本预算:百亿级数据存储选Hadoop更经济,例如互联网用户画像适合Hadoop,而银行风控